
Databricks data source for Grafana
The Databricks data source allows a direct connection to Databricks to query and visualize Databricks data in Grafana.
This data source provides an SQL editor to format and color code your SQL statements.
Installation
For detailed instructions on how to install the plugin on Grafana Cloud or locally, please checkout the Plugin installation docs.
Note: This plugin uses dynamic links for Credentials authentication (deprecated). We suggest using Token authentication. If you run the plugin on bare Alpine Linux, using Credentials authentication it will not work. If for some reason Token based auth is not an option and Alpine Linux is a requirement, we suggest using our Alpine images.
Manual configuration
Once the plugin is installed on your Grafana instance, follow these instructions to add a new Databricks data source, and enter configuration options.
With a configuration file
It is possible to configure data sources using configuration files with Grafana’s provisioning system. To read about how it works, including all the settings that you can set for this data source, refer to Provisioning Grafana data sources.
Here are some provisioning examples for this data source using basic authentication:
apiVersion: 1
datasources:
- name: Databricks
type: grafana-databricks-datasource
jsonData:
host: community.cloud.databricks.com
httpPath: path-from-databricks-odbc-settings
secureJsonData:
token: password/personal-tokenTime series
Time series visualization options are selectable after adding a datetime
field type to your query. This field will be used as the timestamp. You can
select time series visualizations using the visualization options. Grafana
interprets timestamp rows without explicit time zone as UTC. Any column except
time is treated as a value column.
Multi-line time series
To create multi-line time series, the query must return at least 3 fields in the following order:
- field 1:
datetimefield with an alias oftime - field 2: value to group by
- field 3+: the metric values
For example:
SELECT log_time AS time, machine_group, avg(disk_free) AS avg_disk_free
FROM mgbench.logs1
GROUP BY machine_group, log_time
ORDER BY log_timeTemplates and variables
To add a new Databricks query variable, refer to Add a query variable.
After creating a variable, you can use it in your Databricks queries by using Variable syntax. For more information about variables, refer to Templates and variables.
Macros in Databricks Query
| Macro example | Description |
|---|---|
$____interval_long | Converts Grafana’s interval to INTERVAL DAY TO SECOND literal. Applicable to Spark SQL window grouping expression. |
$__timeFilter(dateColumn) | Will be replaced by a time range filter using the specified column name. For example, dateColumn "time BETWEEN '2006-01-02T15:04:05Z07:00' AND '2006-01-02T15:04:05Z07:00'" |
$__timeFrom(dateColumn) | Will be replaced by the start of the currently active time selection. For example, "time > '2006-01-02T15:04:05Z07:00'" |
$__timeGroup(dateColumn,'5m') | Will be replaced by an expression usable in GROUP BY clause. For example, UNIX_TIMESTAMP(time_column) DIV 900 * 900 |
$__timeGroup(dateColumn,'5m', 0) | Same as above but with a fill parameter so missing points in that series will be added by grafana and 0 will be used as value (only works with time series queries). |
$__timeGroup(dateColumn,'5m', NULL) | Same as above but NULL will be used as value for missing points (only works with time series queries). |
$__timeGroup(dateColumn,'5m', previous) | Same as above but the previous value in that series will be used as fill value if no value has been seen yet NULL will be used (only works with time series queries). |
$__timeTo(dateColumn) | Will be replaced by the end of the currently active time selection. $__timeTo(time) => "time < '2006-01-02T15:04:05Z07:00'" |
$__interval_long macro
In some cases, you may want to use window grouping with Spark SQL.
Example:
SELECT window.start, avg(aggqueue) FROM a17
GROUP BY window(_time, '$__interval_long')will be translated into the following query based on dashboard interval.
SELECT window.start, avg(aggqueue) FROM a17
GROUP BY window(_time, '2 MINUTE')Macro examples
The following table shows the macro expansion for the $__interval_long macro when Grafana has a 1m interval.
| Format | Expands to |
|---|---|
$__interval_long | 1 MINUTE |
OAuth Configuration
OAuth Passthrough with Microsoft Entra ID (Azure Active Directory)
Gather information
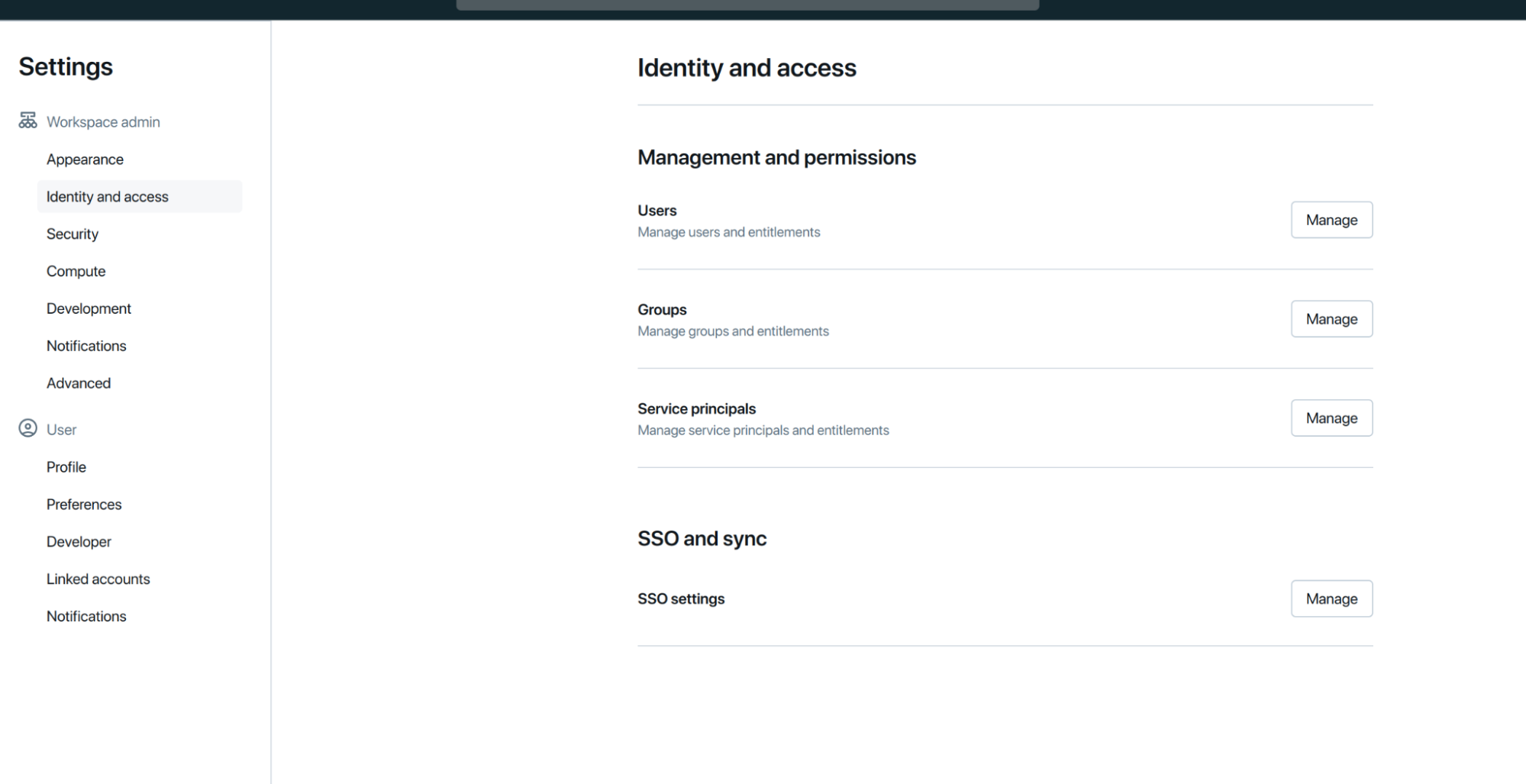
- Go to your Databricks Dashboard as an administrator under Settings > Identity and access > SSO and sync > SSO Settings > Manage:
![Databricks dashboard]()
- Copy the Databricks SAML URL. (Don’t close the tab)
![Databricks dashboard]()
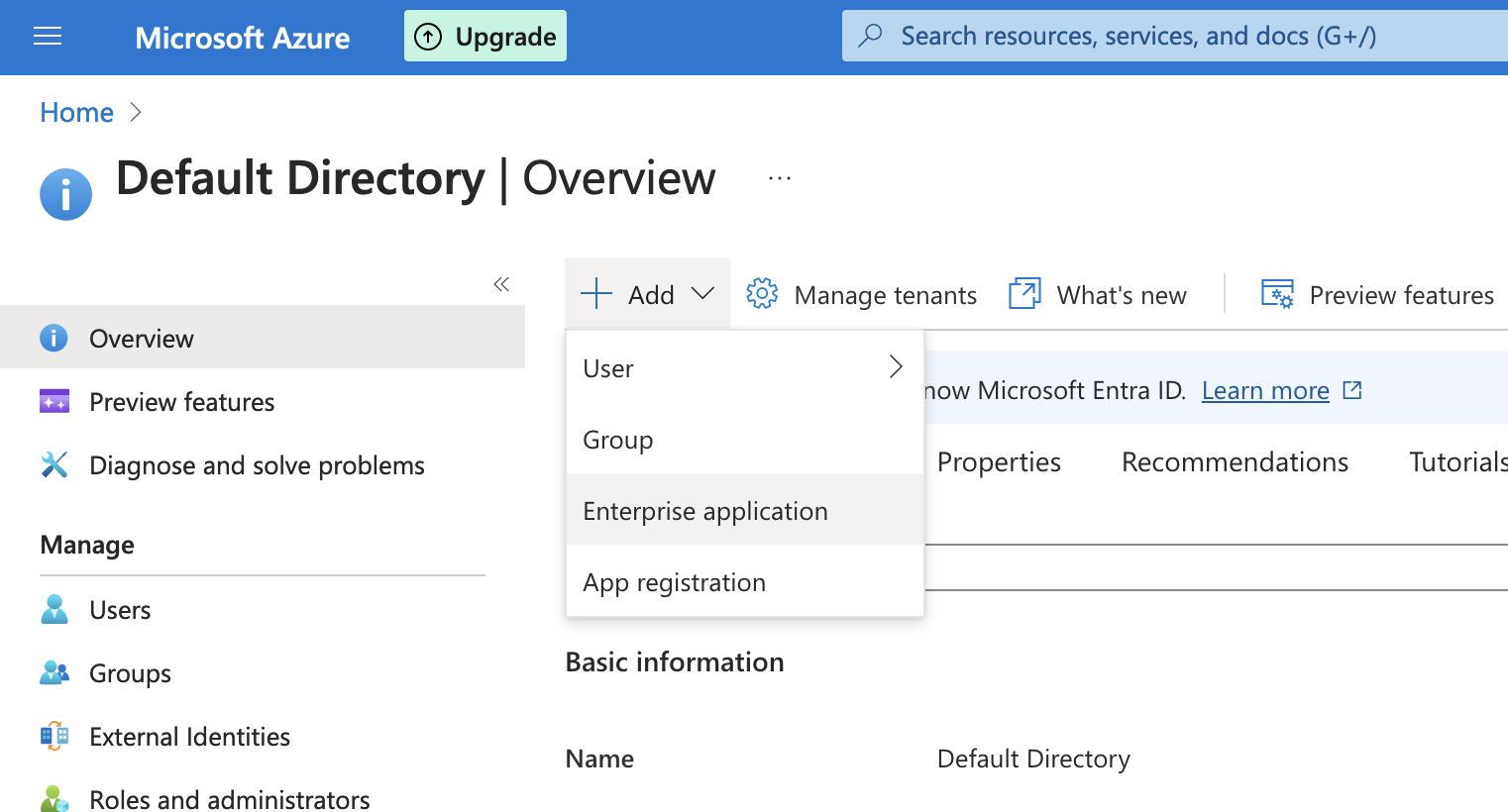
- Create your App Registration:
- Go to the Azure Portal
- Microsoft Entra ID > Add > Enterprise Application
![Microsoft Entra ID Add Enterprise Application screen]()
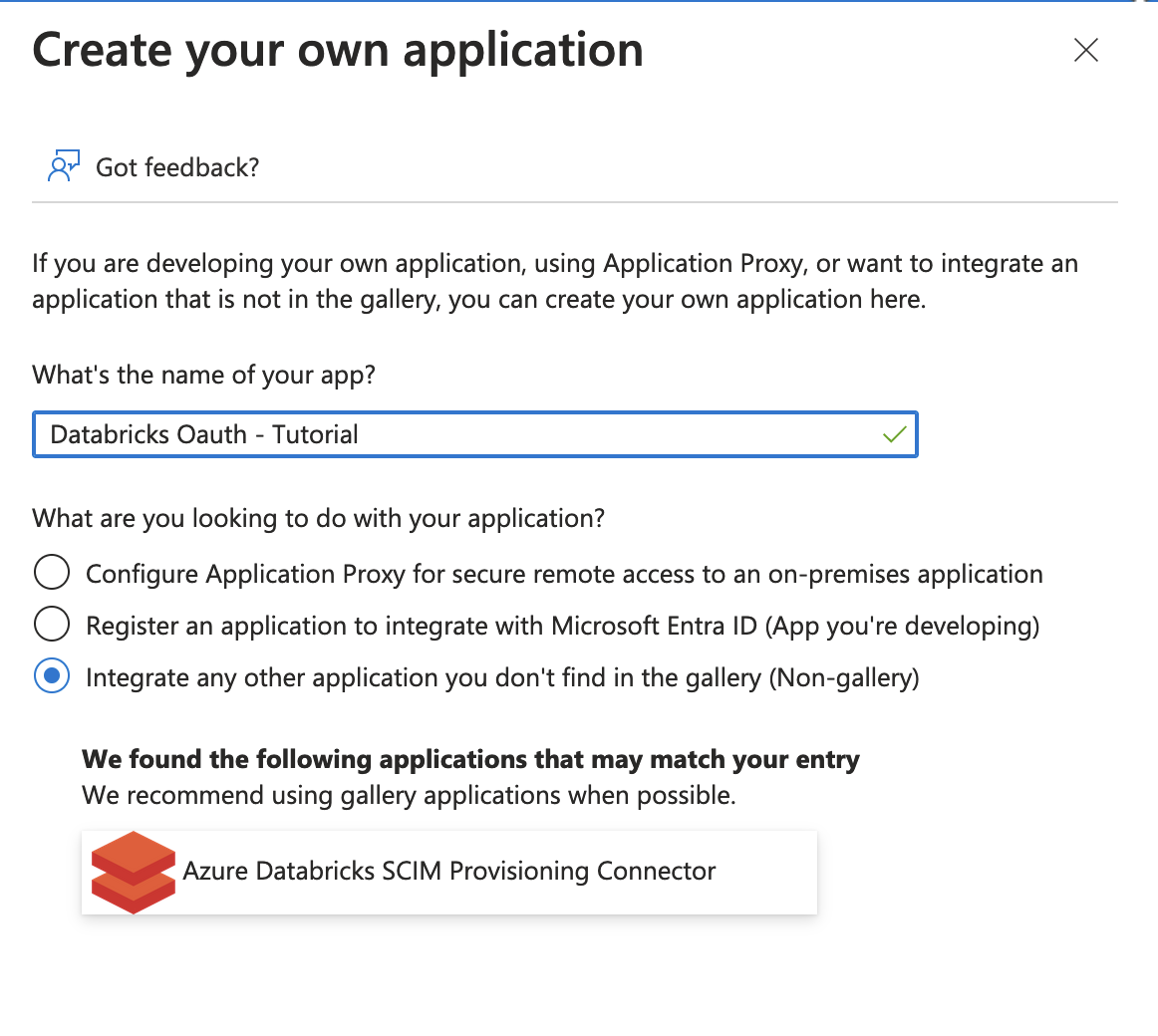
- Enter a name for the application. When asked “What are you looking to do with your application?”, choose Integrate any other application you don’t find in the gallery.
![Databricks create application screen]()
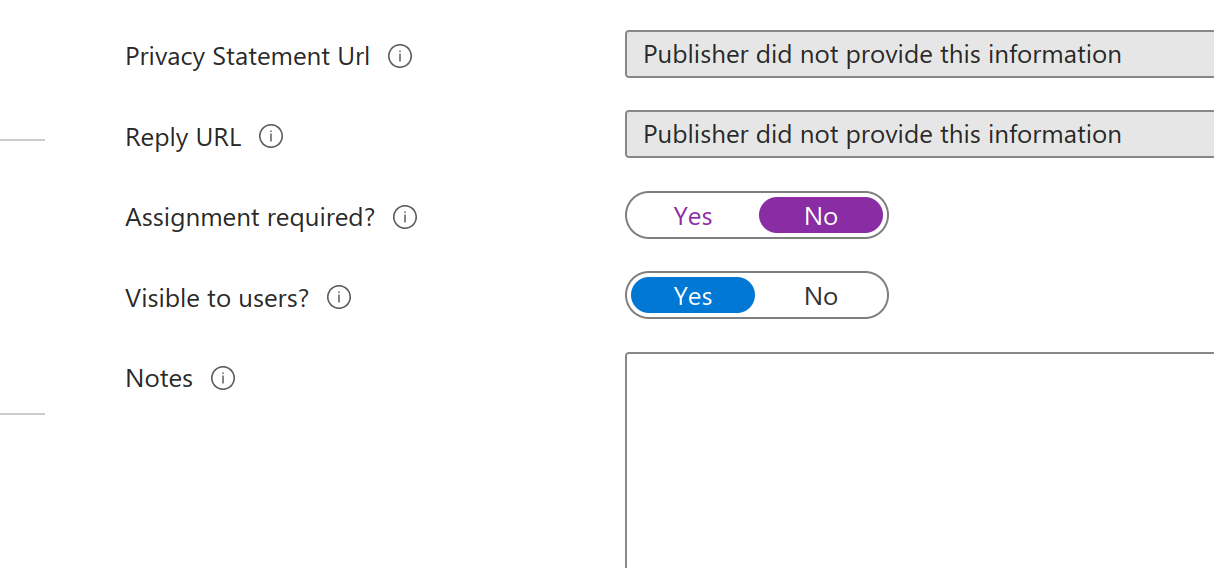
- Under Properties set Assignment Required to NO:
![Databricks create application screen]()
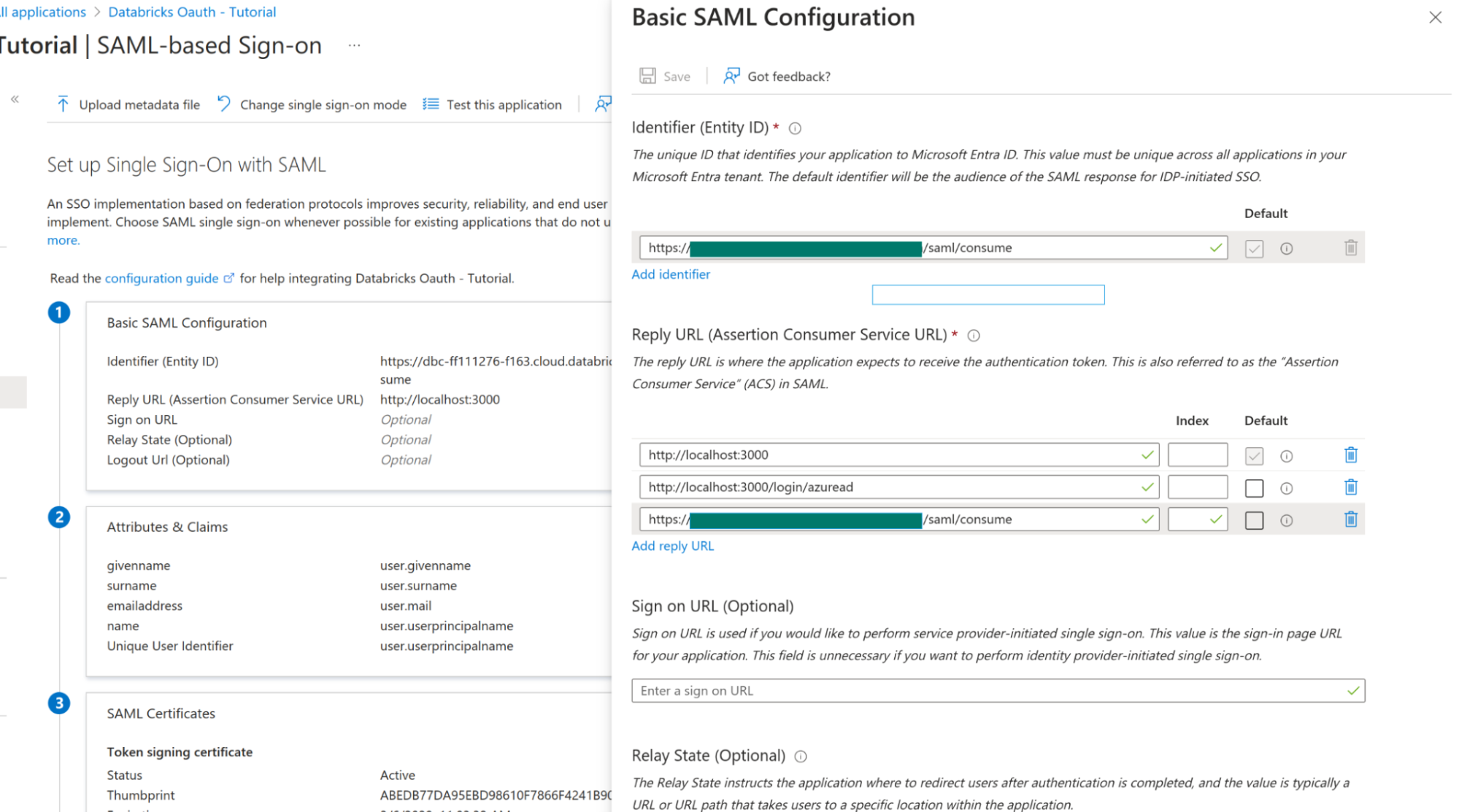
- Under Single-sign on click on SAML and under Basic SAML Configuration click edit:
- Set Identifier ID to the Databricks SAML URL saved from earlier and for Reply URLS set it also to the Databricks SAML URL as well as the Grafana redirect URLs from this guide
![Basic SAML Configuration]()
- Under SAML Sign-in Certificate click Edit and set Sign-in Option to Sign SAML response and assertion. Click Save.
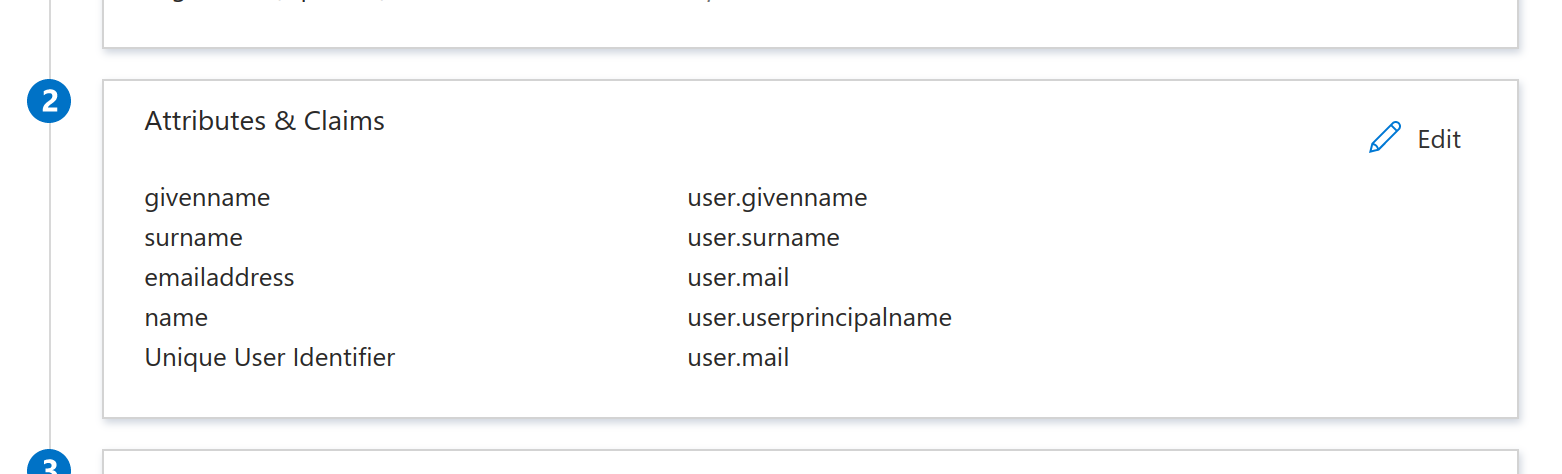
- Under Attributes & Claims click edit. Set the Unique User Identifier (Name ID) field to user.mail
![Basic SAML Configuration]()
- Under SAML Certificates next to Certificate Base 64 click Download. This will download a
.cerfile. Copy the contents for further steps in Databricks. - Also save Login URL and Microsoft Entra ID Identifier for Databricks
- Back in your Databricks SSO Settings tab
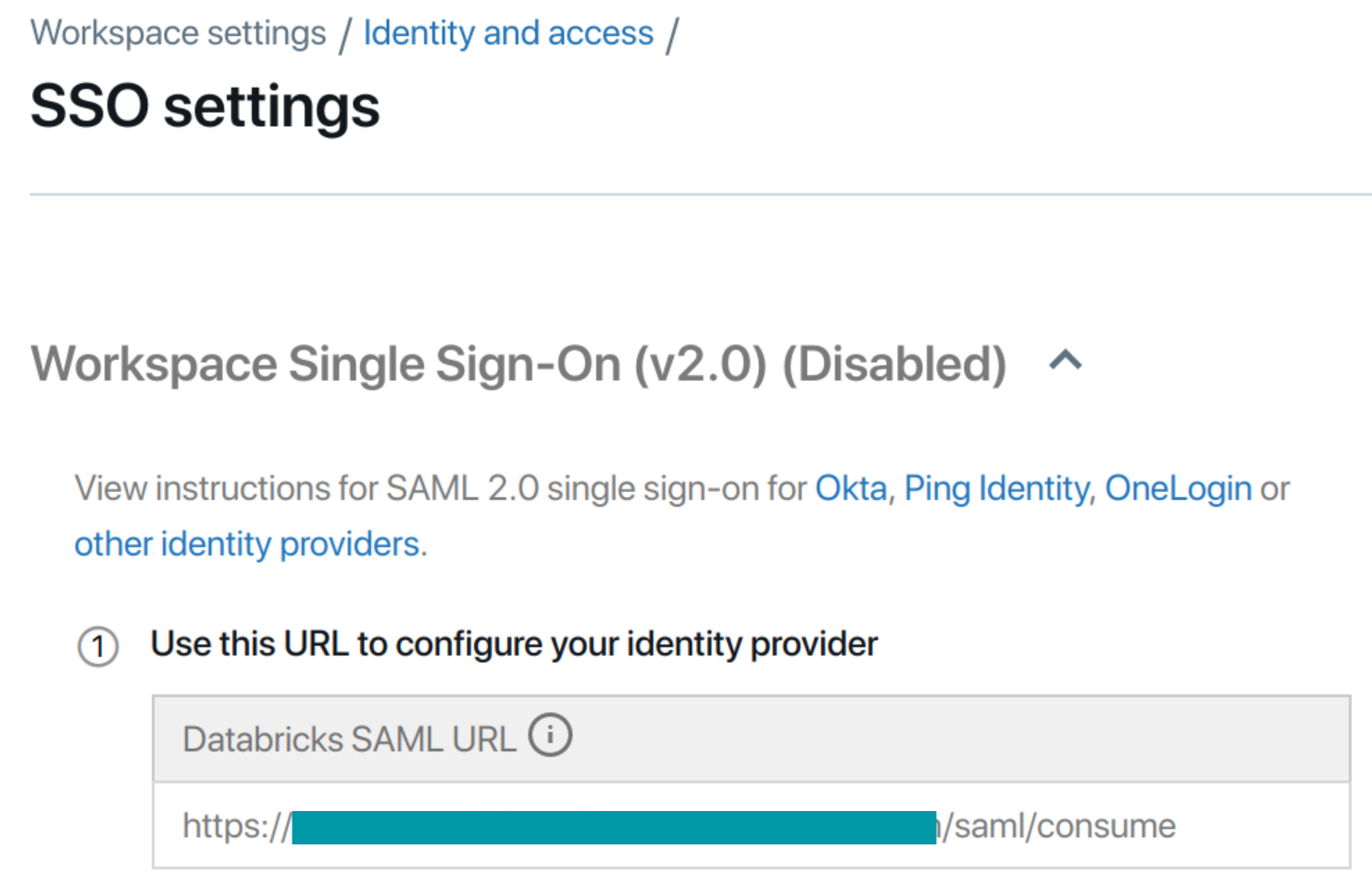
- Single Sign-On URL => Login URL (from previous step)
- Identity Provider Entity ID => Microsoft Entra Identifier (from previous step)
- X.509 Certificate => Contents from downloaded certificate
Complete Grafana OAuth Setup
- On the Azure Portal go to App Registrations > All Applications and find your application name
- On the overview page note the Application (client) ID. For config in your
conf.inifile this is the Oauth client ID as well of Directory (tenant) ID. - Click on Endpoints:
- Note the OAuth 2.0 authorization endpoint (v2) URL. This is the authorization URL.
- Note the OAuth 2.0 token endpoint (v2). This is the token URL.
- Click Certificates & secrets, then add a new entry under Client secrets with the following configuration.
- Description: Grafana OAuth
- Expires: Never
- Click Add then copy the key value. This is the OAuth client secret.
Define Required Roles
- Go to Microsoft Entra ID and then to Enterprise Applications.
- Search for your application and click it.
- Click Users and Groups.
- Click Add user/group to add a user or group to the Grafana roles.
- Now go back to Microsoft Entra ID and then to App Registrations. Search for your app and click it.
- Go to App Roles and configure roles like described in here.
- Now Configure AD Oauth in Grafana Configuration file as described in here.
Forward Token to Users
In your grafana.ini file set:
[azure]
forward_settings_to_plugins = grafana-azure-monitor-datasource, prometheus, grafana-azure-data-explorer-datasource, mssql, grafana-databricks-datasourceFinally, under the data source settings page set the Authentication Type to OAuth Passthrough.
On-behalf-of Authentication
On-behalf-of authentication is only applicable to Azure Databricks clusters. It allows individual users to be authenticated using their own credentials via an App Registration configured in Azure with access to Databricks resources.
On-behalf-of authentication is not supported for private clouds (Azure China Cloud, Azure Government Cloud) at this time.
Warning
Avoid setting up alerts if your data source is configured to use on-behalf-of authentication. Alert rules will not function because no user is in scope to supply credentials for the query.
Setup
Configure Grafana to use OAuth2 with Microsoft Entra ID as documented. The
[auth.azuread]scopes(or$GF_AUTH_AZUREAD_SCOPES) must contain “openid email profile offline_access”.ID tokens must be enabled with a checkbox found on the Azure portal under “App Registrations” → the respective application → “Manage” → “Authentication”.
In addition to the “Microsoft Graph”
User.Read, a special “Azure Databricks”user_impersonationpermission must be enabled on the Azure portal under “App Registrations” → the respective application → “Manage” → “API permissions”.Enable “Admin consent” under “App Registrations” → the respective application → “Security” → “Permissions”. Enabling “Admin consent” will grant consent on behalf of all users in the current tenant, ensuring the users will not be required to consent when using the application.
When configuring the data source for an Azure Databricks cluster, the hostname and HTTP path can be found by navigating to your Azure Databricks cluster → SQL Warehouses → Connection details → Server hostname and HTTP path.
Use the Tenant ID, Client ID, and Client secret values for the Application Registration created in step 1.
Learn more
- Add Annotations.
- Configure and use Templates and variables.
- Add Transformations.
- Set up alerting; refer to Alerts overview.
Was this page helpful?
Related resources from Grafana Labs


