
Important: This documentation is about an older version. It's relevant only to the release noted, many of the features and functions have been updated or replaced. Please view the current version.
Using InfluxDB in Grafana
Grafana ships with a feature-rich data source plugin for InfluxDB. The plugin includes a custom query editor and supports annotations and query templates.
Add the data source
- Open the side menu by clicking the Grafana icon in the top header.
- In the side menu under the
Dashboardslink you should find a link namedData Sources. - Click the
+ Add data sourcebutton in the top header. - Select InfluxDB from the Type dropdown.
- Select InfluxQL or Flux from the
Query Languagelist.
Note: If you’re not seeing the
Data Sourceslink in your side menu it means that your current user does not have theAdminrole for the current organization.
InfluxQL (classic InfluxDB query)
| Name | Description |
|---|---|
Name | The data source name. This is how you refer to the data source in panels and queries. |
Default | Default data source means that it will be pre-selected for new panels. |
URL | The HTTP protocol, IP address and port of your InfluxDB API (InfluxDB API port is by default 8086) |
Access | Server (default) = URL needs to be accessible from the Grafana backend/server, Browser = URL needs to be accessible from the browser. |
Database | Name of your InfluxDB database |
User | Name of your database user |
Password | Database user’s password |
HTTP mode | How to query the database (GET or POST HTTP verb). The POST verb allows heavy queries that would return an error using the GET verb. Default is GET. |
Access mode controls how requests to the data source will be handled. Server should be the preferred way if nothing else stated.
Server access mode (Default)
All requests will be made from the browser to Grafana backend/server which in turn will forward the requests to the data source and by that circumvent possible Cross-Origin Resource Sharing (CORS) requirements. The URL needs to be accessible from the grafana backend/server if you select this access mode.
Browser access mode
All requests will be made from the browser directly to the data source and may be subject to Cross-Origin Resource Sharing (CORS) requirements. The URL needs to be accessible from the browser if you select this access mode.
Min time interval
A lower limit for the auto group by time interval. Recommended to be set to write frequency, for example 1m if your data is written every minute.
This option can also be overridden/configured in a dashboard panel under data source options. It’s important to note that this value needs to be formatted as a
number followed by a valid time identifier, e.g. 1m (1 minute) or 30s (30 seconds). The following time identifiers are supported:
| Identifier | Description |
|---|---|
y | year |
M | month |
w | week |
d | day |
h | hour |
m | minute |
s | second |
ms | millisecond |
Query Editor
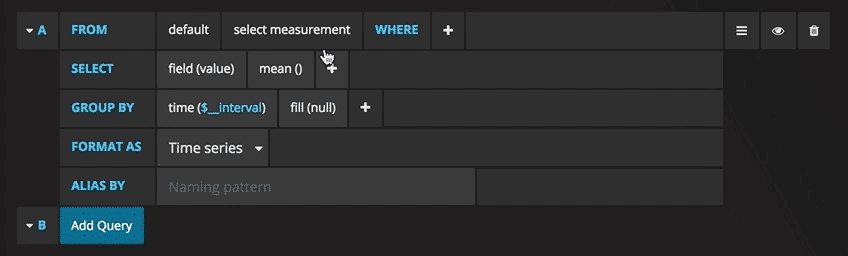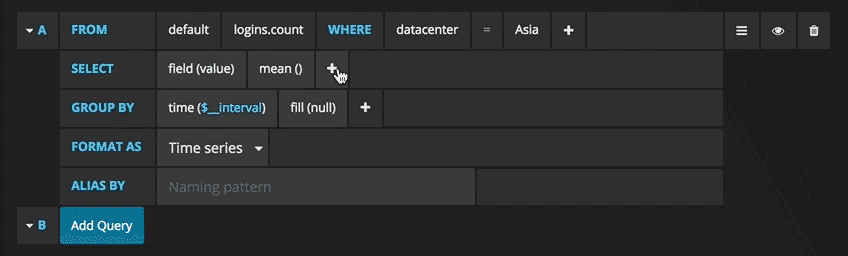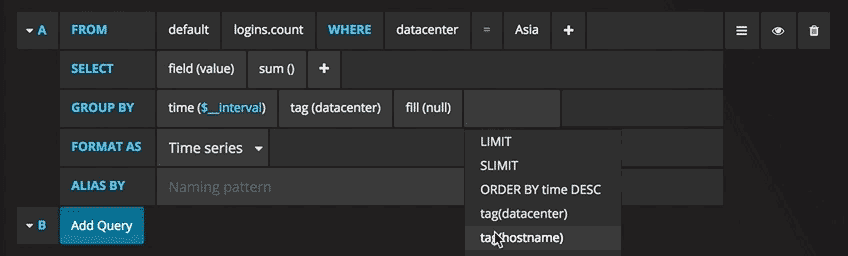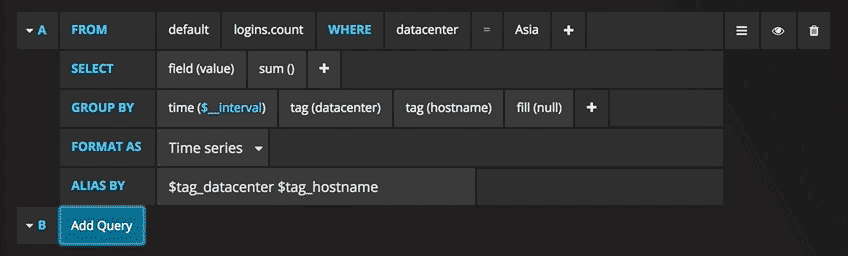
You can access the InfluxDB editor under the metrics tab when you are in the edit mode of the Graph or Singlestat panels. Enter edit mode by clicking the panel title and clicking Edit. The editor allows you to select metrics and tags.
Filter data (WHERE)
To add a tag filter, click the plus icon to the right of the WHERE condition. You can remove tag filters by clicking on
the tag key and then selecting --remove tag filter--.
Regex matching
You can type in regex patterns for metric names or tag filter values. Be sure to wrap the regex pattern in forward slashes (/). Grafana automatically adjusts the filter tag condition to use the InfluxDB regex match condition operator (=~).
Field and Aggregation functions
In the SELECT row you can specify what fields and functions you want to use. If you have a
group by time you need an aggregation function. Some functions like derivative require an aggregation function. The editor tries to simplify and unify this part of the query. For example:
![]()
The above generates the following InfluxDB SELECT clause:
SELECT derivative(mean("value"), 10s) /10 AS "REQ/s" FROM ....Select multiple fields
Use the plus button and select Field > field to add another SELECT clause. You can also
specify an asterix * to select all fields.
Group By
To group by a tag, click the plus icon at the end of the GROUP BY row. Pick a tag from the dropdown that appears.
You can remove the “Group By” by clicking on the tag and then click on the x icon.
Text Editor Mode (RAW)
You can switch to raw query mode by clicking hamburger icon and then Switch editor mode.
If you use Raw Query be sure your query at minimum have
WHERE $timeFilterAlso please always have a group by time and an aggregation function, otherwise InfluxDB can easily return hundreds of thousands of data points that will hang the browser.
Alias patterns
- $m = replaced with measurement name
- $measurement = replaced with measurement name
- $col = replaced with column name
- $tag_exampletag = replaced with the value of the
exampletagtag. The syntax is$tag_yourTagName(must start with$tag_). To use your tag as an alias in the ALIAS BY field then the tag must be used to group by in the query. - You can also use [[tag_hostname]] pattern replacement syntax. For example, in the ALIAS BY field using this text
Host: [[tag_hostname]]would substitute in thehostnametag value for each legend value and an example legend value would be:Host: server1.
Table query / raw data
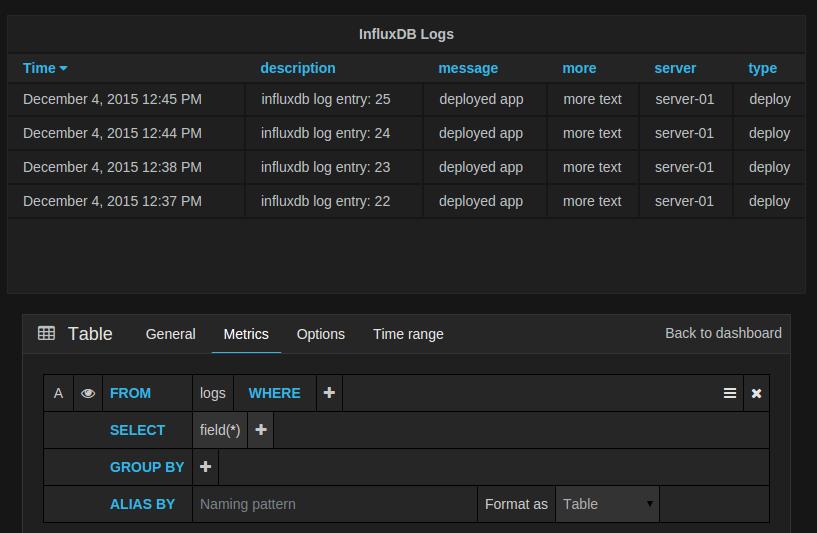
You can remove the group by time by clicking on the time part and then the x icon. You can
change the option Format As to Table if you want to show raw data in the Table panel.
Flux support
Starting in v7.1, Grafana can execute Flux queries.
The client supports Flux running on InfluxDB 1.8+. See 1.8 compatibility for more information and connection details.
| Name | Description |
|---|---|
URL | The HTTP protocol, IP address and port of your InfluxDB API (InfluxDB 2.0 API port is by default 9999) |
Organization | The Influx organization that will be used for Flux queries. This is also used to for the v.organization query macro |
Token | The authentication token used for Flux queries. With Influx 2.0, use the influx authentication token to function. For influx 1.8, the token is username:password |
Default Bucket | The Influx bucket that will be used for the v.defaultBucket macro in Flux queries |
You can use the Flux query and scripting language. Grafana’s Flux query editor is a text editor for raw Flux queries with Macro support.
Supported macros
The macros support copying and pasting from Chronograph.
| Macro example | Description |
|---|---|
v.timeRangeStart | Will be replaced by the start of the currently active time selection. For example, 2020-06-11T13:31:00Z |
v.timeRangeEnd | Will be replaced by the end of the currently active time selection. For example, 2020-06-11T14:31:00Z |
v.windowPeriod | Will be replaced with an interval string compatible with Flux that corresponds to Grafana’s calculated interval based on the time range of the active time selection. For example, 5s |
v.defaultBucket | Will be replaced with the data source configuration’s “Default Bucket” setting |
v.organization | Will be replaced with the data source configuration’s “Organization” setting |
For example, the following query will be interpolated as the query that follows it, with interval and time period values changing according to active time selection):
Grafana Flux query:
from(bucket: v.defaultBucket)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "cpu" or r["_measurement"] == "swap")
|> filter(fn: (r) => r["_field"] == "usage_system" or r["_field"] == "free")
|> aggregateWindow(every: v.windowPeriod, fn: mean)
|> yield(name: "mean")Interpolated query send to Influx:
from(bucket: "grafana")
|> range(start: 2020-06-11T13:59:07Z, stop: 2020-06-11T14:59:07Z)
|> filter(fn: (r) => r["_measurement"] == "cpu" or r["_measurement"] == "swap")
|> filter(fn: (r) => r["_field"] == "usage_system" or r["_field"] == "free")
|> aggregateWindow(every: 2s, fn: mean)
|> yield(name: "mean")You can view the interpolated version of a query with the Query Inspector.
Querying Logs (BETA)
Only available in Grafana v6.3+.
Querying and displaying log data from InfluxDB is available in Explore, and in the logs panel in dashboards. Select the InfluxDB data source, and then enter a query to display your logs.
Log Queries
The Logs Explorer (the Measurements/Fields button) next to the query field shows a list of measurements and fields. Choose the desired measurement that contains your log data and then choose which field Explore should use to display the log message.
Once the result is returned, the log panel shows a list of log rows and a bar chart where the x-axis shows the time and the y-axis shows the frequency/count.
Filter search
To add a filter, click the plus icon to the right of the Measurements/Fields button or a condition. You can remove tag filters by clicking on the first select and choosing --remove filter--.
Templating
Instead of hard-coding things like server, application and sensor name in your metric queries you can use variables in their place. Variables are shown as dropdown select boxes at the top of the dashboard. These dropdowns make it easy to change the data being displayed in your dashboard.
Check out the Templating documentation for an introduction to the templating feature and the different types of template variables.
Query variable
If you add a template variable of the type Query, then you can write an InfluxDB exploration (metadata) query. These queries can
return things like measurement names, key names or key values.
For example, you can have a variable that contains all values for tag hostname if you specify a query like this in the template variable Query setting.
SHOW TAG VALUES WITH KEY = "hostname"You can also create nested variables. For example, if you had another variable, for example region. Then you could have
the hosts variable only show hosts from the current selected region with a query like this:
SHOW TAG VALUES WITH KEY = "hostname" WHERE region = '$region'You can fetch key names for a given measurement.
SHOW TAG KEYS [FROM <measurement_name>]If you have a variable with key names you can use this variable in a group by clause. This will allow you to change group by using the variable dropdown at the top of the dashboard.
Using variables in queries
There are two syntaxes:
$<varname> Example:
SELECT mean("value") FROM "logins" WHERE "hostname" =~ /^$host$/ AND $timeFilter GROUP BY time($__interval), "hostname"[[varname]] Example:
SELECT mean("value") FROM "logins" WHERE "hostname" =~ /^[[host]]$/ AND $timeFilter GROUP BY time($__interval), "hostname"Why two ways? The first syntax is easier to read and write but does not allow you to use a variable in the middle of a word. When the Multi-value or Include all value
options are enabled, Grafana converts the labels from plain text to a regex compatible string. Which means you have to use =~ instead of =.
Example Dashboard: InfluxDB Templated Dashboard
Ad hoc filters variable
InfluxDB supports the special Ad hoc filters variable type. This variable allows you to specify any number of key/value filters on the fly. These filters will automatically
be applied to all your InfluxDB queries.
Annotations
Annotations allows you to overlay rich event information on top of graphs. Add annotation queries using the Annotations view in the Dashboard menu.
An example query:
SELECT title, description from events WHERE $timeFilter ORDER BY time ASCFor InfluxDB, you need to enter a query like the one in the example above. The where $timeFilter component is required. If you only select one column, then you do not need to enter anything in the column mapping fields. The Tags field can be a comma-separated string.
Configure the data source with provisioning
You can now configure data sources using config files with Grafana’s provisioning system. You can read more about how it works and all the settings you can set for data sources on the provisioning docs page.
Here are some provisioning examples for this data source.
InfluxDB 1.x example
apiVersion: 1
datasources:
- name: InfluxDB_v1
type: influxdb
access: proxy
database: site
user: grafana
password: grafana
url: http://localhost:8086
jsonData:
httpMode: GETInfluxDB 2.x example
apiVersion: 1
datasources:
- name: InfluxDB_v2
type: influxdb
access: proxy
url: http://localhost:8086
secureJsonData:
token: token
jsonData:
version: Flux
organization: organization
defaultBucket: bucket
tlsSkipVerify: trueWas this page helpful?
Related resources from Grafana Labs


