
Release date:
Menu
Grafana Cloud
RSS
What’s new in Grafana Cloud
Grafana Labs products, projects, and features can go through multiple release stages before becoming generally available. These stages in the release life cycle can present varying degrees of stability and support. For more information, refer to release life cycle for Grafana Labs.
Loading...
Area of interest:
Cloud availability:
Cloud editions:
Self-managed availability:
Self-managed editions:
No results found. Please adjust your filters or search criteria.
Page:
Substring matcher added to the filter by value transformation
Generally AvailableDashboards and visualizations
Release date: 2024-03-01
This update to the Filter data by values transformation simplifies data filtering by enabling partial string matching on field values thanks to two new matchers: Contains substring and Does not contain substring. With the substring matcher built into the Filter data by values transformation, you can efficiently filter large datasets, displaying relevant information with speed and precision. Whether you’re searching for keywords, product names, or user IDs, this feature streamlines the process, saving time and effort while ensuring accurate data output.
In the Filter data by values transformation, simply add a condition, choose a field, choose your matcher, and then input the string to match against.
Log Volume Explorer
Generally AvailableLogsCost management
Release date: 2024-02-29
The Log Volume Explorer has been promoted to General Availability! First announced at ObsCon London in Nov 2023, the Log Volume Explorer adds to our set of features that help you manage your observability spend. Identify the source of logs ingested into Grafana Cloud and answer questions like “Which of my teams, environments, Kubernetes clusters, and/or applications are generating the most logs?” Find the Log Volume Explorer under Administration > Cost Management > Logs.
GCk6 Private Load Zones
Generally AvailableK6
Release date: 2024-02-29
Are you a k8s user? Do your requirements involve testing internal services or generating load from inside your network? Private Load Zones are a new feature of Grafana Cloud k6 that allow you to run k6 load generators from your k8s cluster and push metrics to Grafana Cloud and visualize them in the Grafana Cloud k6 app plugin.
This feature is built on top of our OSS k6-operator and lets you start tests with the k6 cloud command the same way you would do if you used Grafana Cloud’s load zones.
Use Azure Private Link to send metrics, logs, and traces to Grafana Cloud
Available in public preview
Release date: 2024-02-28
Save money and apply an extra layer of network security by using Azure Private Link to send metrics, logs, traces, and profiles to Grafana Cloud.
Normally when you send telemetry from Microsoft Azure to Grafana Cloud, you incur network egress fees above a certain traffic volume and your data, though encrypted, traverses the public internet. With Azure Private Link, traffic between your virtual network and Grafana Cloud travels the Microsoft backbone network, so exposing your service to the public internet is no longer necessary.
Subfolders
Generally AvailableDashboards and visualizations
Release date: 2024-02-27
Subfolders are here at last!
Some of you want subfolders in order to keep things tidier. It’s easy for dashboard sprawl to get out of control, and setting up folders in a nested hierarchy helps with that.
Aggregates in Grafana Cloud k6 dashboards
Generally AvailableK6
Release date: 2024-02-26
If you’ve wanted to visualize your Grafana Cloud k6 test results in a dashboard you’ve been limited to displaying data as a time series. But sometimes a single number is more digestible and can help you make an assessment of your test results quicker.
Now you can aggregate your data not only over time, but as a single aggregated value. This is especially useful in combination with the Stat panel. Just change the type of your query to “Aggregate” in the new options section and data will now be aggregated for the entire time series.
SSO Settings UI and Terraform resource for configuring OAuth providers
Available in public previewAuthentication and authorization
Release date: 2024-02-26
Configuring OAuth providers was a bit cumbersome in Grafana: Grafana Cloud users had to reach out to Grafana Support, self-hosted users had to manually edit the configuration file, set up environment variables, and then they had to restart Grafana. On Cloud, the Advanced Auth page is there to configure some of the providers, but configuring Generic OAuth hasn’t been available until now and there was no way to manage the settings through the Grafana UI, nor was there a way to manage the settings through Terraform or the Grafana API.
Our goal is to make setting up SSO for your Grafana instance simple and fast.

Centralized diagnosis and troubleshooting in AWS Observability app
Generally Available
Release date: 2024-02-24
It’s hard to diagnose and resolve issues when your observability data is dispersed across many systems, which can lead to longer times to troubleshoot. Grafana’s AWS Observability provides a centralized location to work with critical observability data so you can fully understand the state of your systems. You can:
- Configure simply and securely
- Access, query, alert on, and interact in one place

Configure metrics and logs easily in AWS Observability app
Generally Available
Release date: 2024-02-24
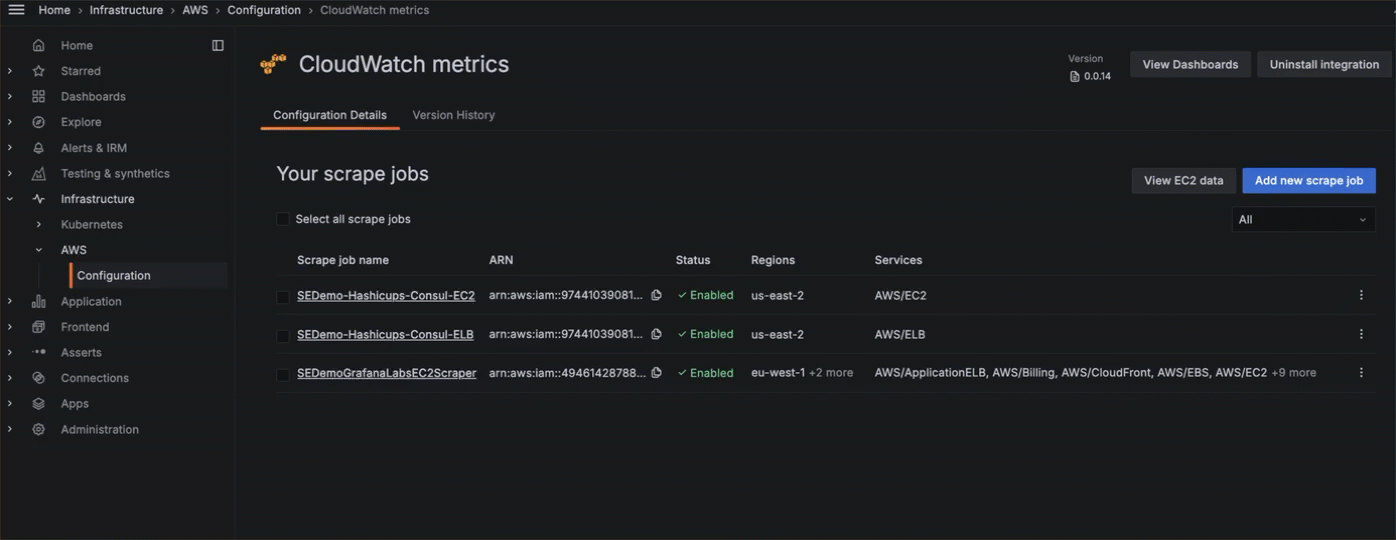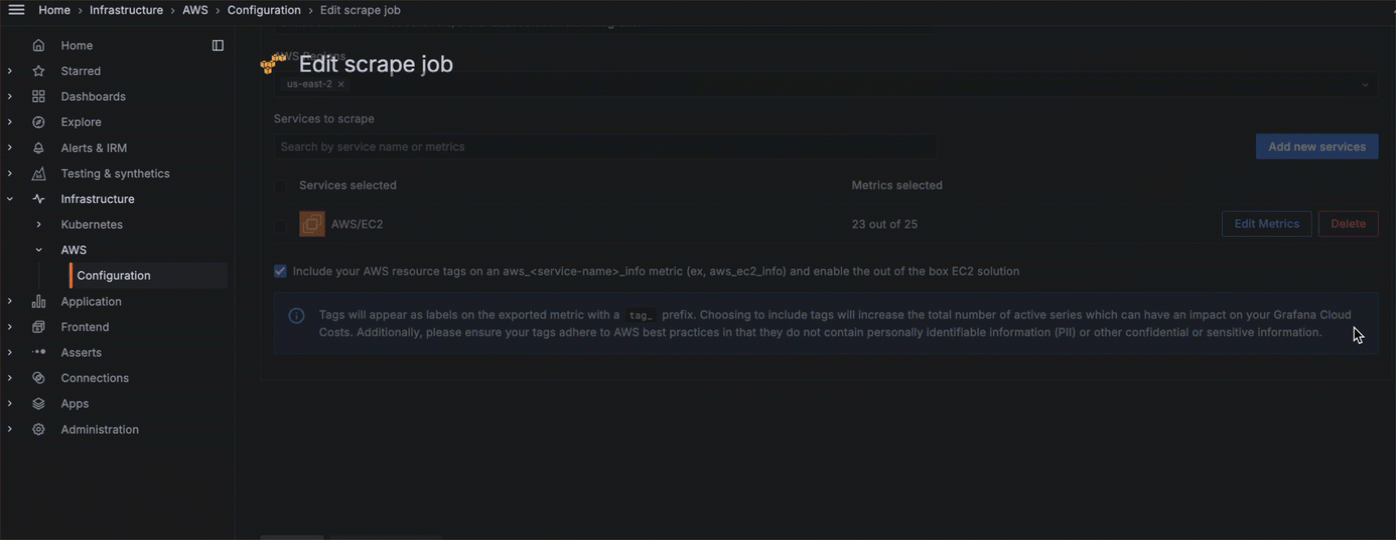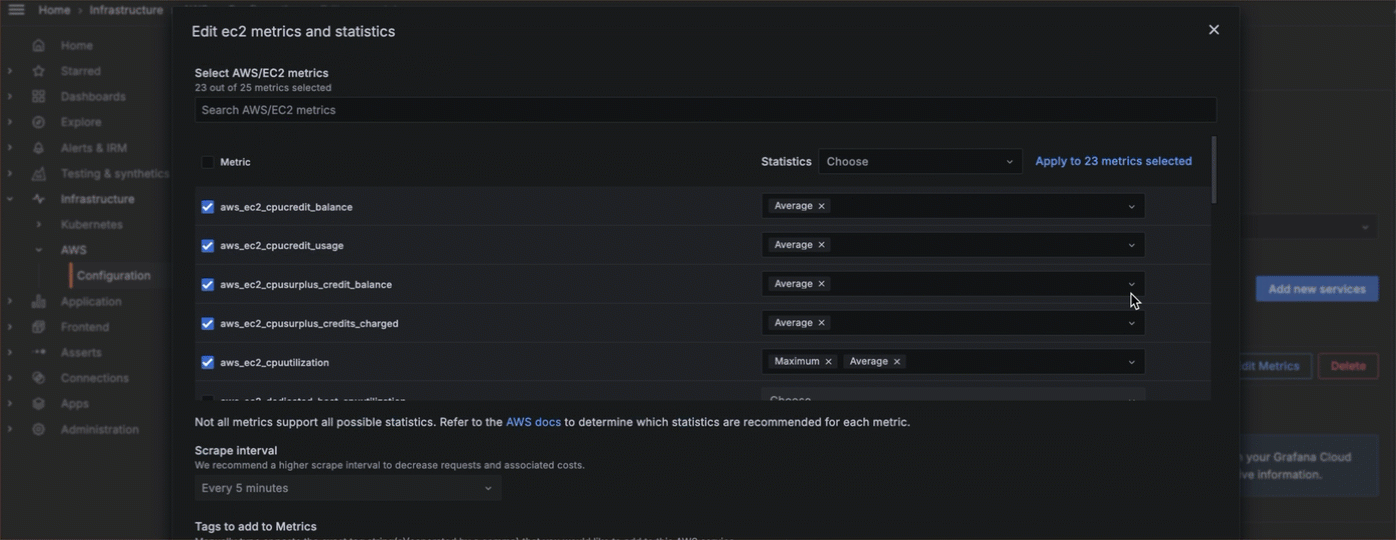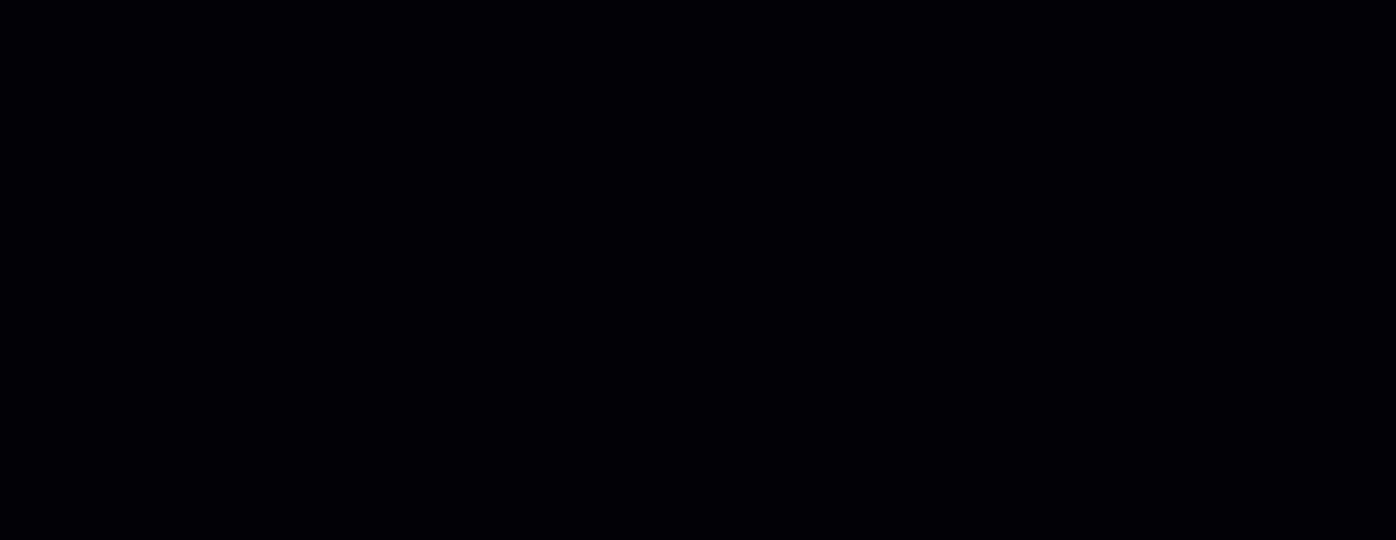
You can choose to configure manually, or use a more streamlined configuration process with CloudFormation or Terraform. To send CloudWatch metrics to Grafana Cloud, you:
- Connect to your AWS account.
- Configure the connection between Grafana Cloud and your AWS account.
- Continue configuration with either CloudFormation or Terraform.
- Choose what service to monitor, what metrics to gather, the scrape interval, and what statistics to gather.
- Add any custom namespaces you want to monitor.
![Metrics configuration]()

You can also edit or delete scrape jobs.
Embedded, out-of-the-box dashboards in AWS Observability
Generally Available
Release date: 2024-02-24
AWS Observability provides preconfigured dashboards embedded within the app.

You can easily access dashboards to monitor AWS costs and cloud services. For example, the following shows the billing dashboard.

Monitor AWS EC2 in Grafana Cloud out of the box
Generally Available
Release date: 2024-02-24
Grafana AWS Observability offers an out-of-the-box, embedded experience for you to efficiently explore and analyze your Amazon EC2 data.
The list of EC2 instances is available from the Overview tab.

Create subtables in table visualizations with Group to nested tables
Available in public previewDashboards and visualizations
Release date: 2024-02-20
You can now create subtables out of your data using the new Group to nested tables transformation. To use this feature, enable the groupToNestedTableTransformation feature toggle.
Data visualization quality of life improvements v10.4
Generally AvailableDashboards and visualizations
Release date: 2024-02-20
We’ve made a number of small improvements to the data visualization experience in Grafana.
Geomap geojson layer now supports styling

Tooltip improvements
Available in public previewDashboards and visualizations
Release date: 2024-02-20
We’ve made a number of small improvements to the way tooltips work in Grafana. To try out the new tooltips, enable the newVizTooltips feature toggle.
Copy on click support

PagerDuty enterprise data source for Grafana
Generally AvailableData sourcesPlugins
Release date: 2024-02-14
PagerDuty enterprise data source plugin for Grafana allows you to query incidents data or visualize incidents using annotations.
Plugin is currently in a preview phase.

Was this page helpful?
Related resources from Grafana Labs
5 Mar

Getting started with managing your metrics, logs, and traces using Grafana
In this webinar, we’ll demo how to get started using the LGTM Stack: Loki for logs, Grafana for visualization, Tempo for traces, and Mimir for metrics.
26 Feb

Intro to Kubernetes monitoring in Grafana Cloud
In this webinar you’ll learn how Grafana offers developers and SREs a simple and quick-to-value solution for monitoring their Kubernetes infrastructure.
60 min

Building advanced Grafana dashboards
In this webinar, we’ll demo how to build and format Grafana dashboards.