

Anleitung zur Überwachung des Zustands und der Ressourcennutzung von Kubernetes-Nodes in Grafana-Cloud
Die Wirbelsäule ist für jede Aktivität wichtig, wie Krabbeln, Gehen oder Schwimmen. So wie die Wirbelsäule notwendig ist, um diese Bewegungen zu ermöglichen, benötigt eure Kubernetes-Infrastruktur ein Rückgrat, um effizient und effektiv zu sein. Wenn also Kubernetes-Cluster als das Rückgrat eurer Architektur fungieren, dann sind Kubernetes-Nodes wie die Wirbel — sie bilden ein Kubernetes-Cluster, wie die Wirbel die Wirbelsäule bilden.
Ob auf virtuellen oder Bare-Metal-Maschinen, es gibt zwei Arten von Knoten in einem Kubernetes-Cluster:
- Worker-Nodes: Diese hosten Ihre Anwendungscontainer, die als Pods gruppiert sind.
- Control-Plane-Nodes: Diese führen die Dienste aus, die zum Steuern des Kubernetes-Clusters erforderlich sind.
Wenn ihr möchtet, dass eure Cluster funktionieren und eure Anwendungen schnell ausgeführt werden, müsst ihr über ein gesundes Rückgrat effizienter Nodes verfügen. Ihr könnt dies auf zwei Arten erreichen:
- Über einen teuren Autoscaler, der euch immer mehr Cloud-Ressourcen kauft und immer mehr Nodes schafft. Obwohl ihr scheinbar endlose Ressourcen habt, ist es schwierig, festzustellen, wo die tatsächlichen Probleme liegen.
- Oder durch einen datengesteuerten Ansatz für eine bessere Kapazitätsauslastung, Ressourcenverwaltung, Pod-Platzierung und Problemlösung mithilfe eines starken Observability-Tools.
Unter der Annahme, dass ein Autoscaler allein eure Infrastrukturprobleme nicht zufriedenstellend löst, informiere ich euch gerne über unsere neue Kubernetes-Node-Observability. Diese ist ein neuer Bestandteil des Kubernetes Monitoring, der vollständigen Kubernetes-Observability-Lösung, die allen Grafana-Cloud-Benutzern zur Verfügung steht, einschließlich derjenigen, die die großzügige kostenlose Stufe verwenden. (Wenn ihr noch kein Grafana-Cloud-Konto habt, könnt ihr euch noch heute für ein kostenloses Konto anmelden!)
So funktioniert die Kubernetes-Node-Observability in Grafana-Cloud
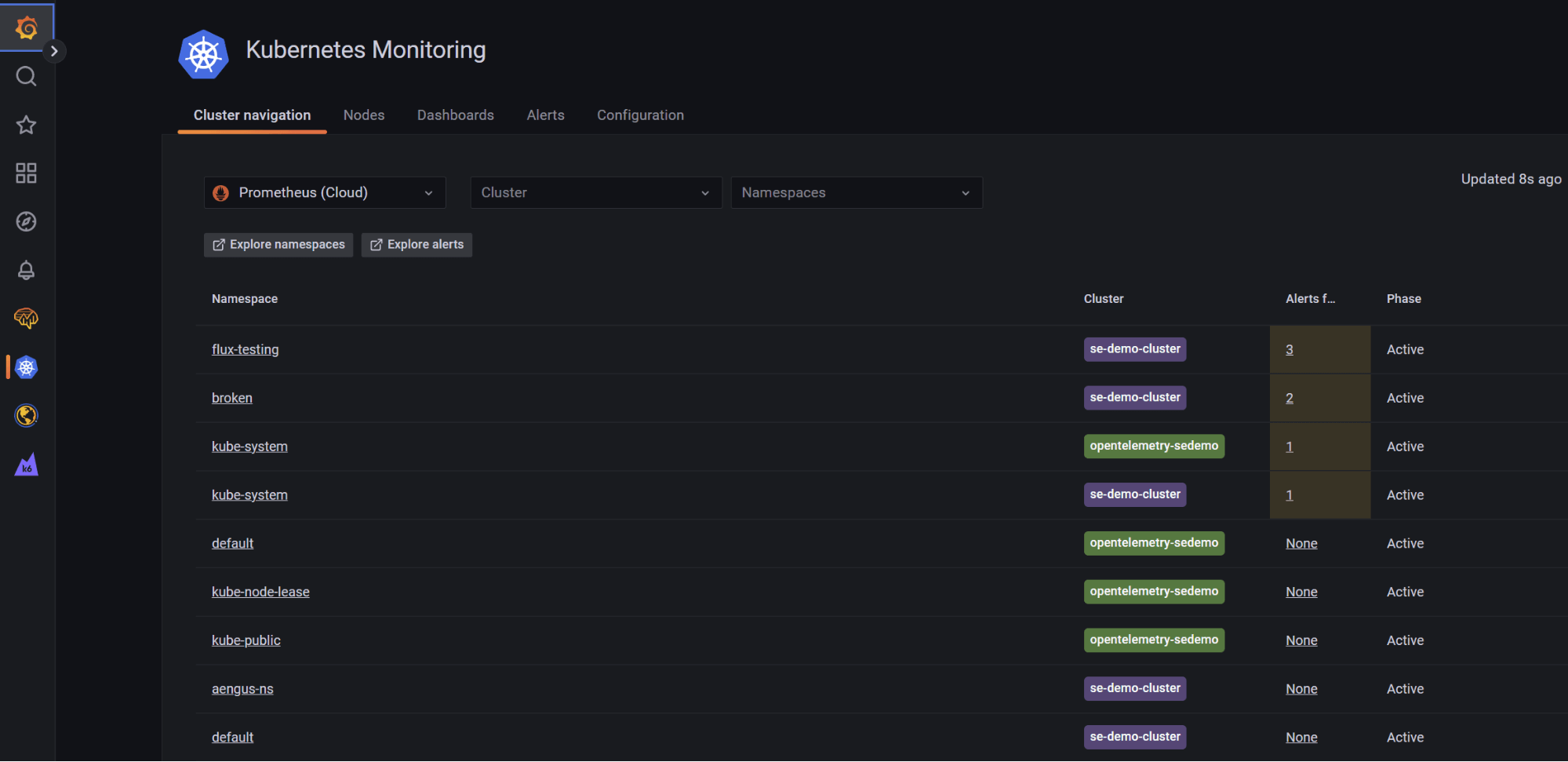
Die Einrichtung und Skalierung von Kubernetes Monitoring ist komplex und schwierig. Mit der Node-Observability in der Kubernetes Monitoring-Lösung in Grafana Cloud bieten wir Funktionen, die drei umfassende Problembereiche bei der Verwaltung von Node ansprechen.
1. Anzeigenaller Nodes in euren Clustern inklusive Zustand und aktuell verfügbarer Ressourcennutzung
Wie dies euer Leben erleichtert: Verringert die mittlere Zeit bis zur Lösung (MTTR), indem es auf einen Blick Lösungsansätze zu einem bestehenden oder potenziellen Problem bietet.
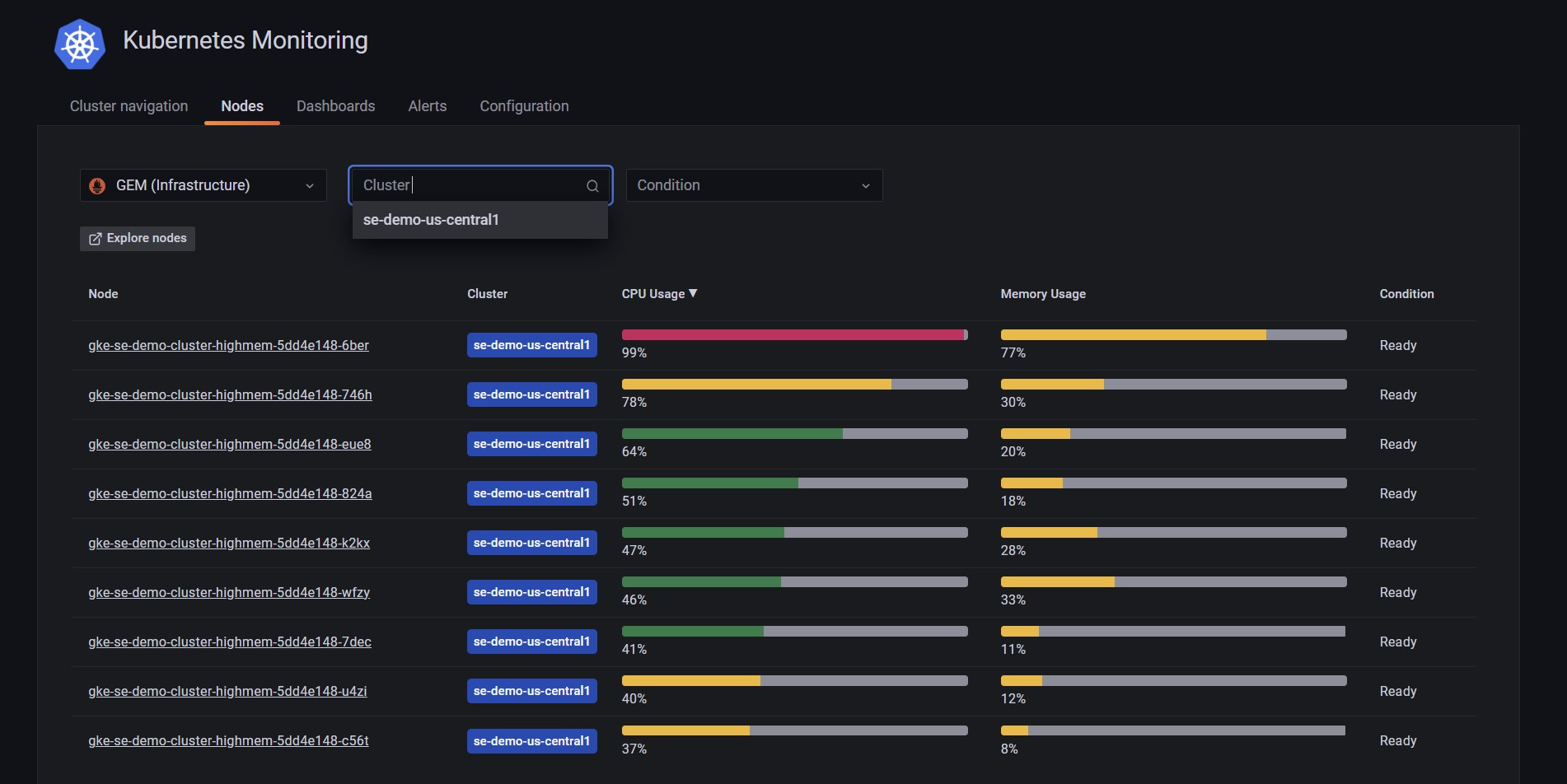
Erkenntnisse, die ihr gewinnt:
- Eine Übersicht all eurer Knoten, die zu einem Cluster gehören inklusive Filtermechanismen.
- Farbige Indikatoren für CPU- und Speicherverbrauch.
- Der Zustand eurer Nodes in Kombination mit ihrer Kubernetes-Beschreibung.

2. Indikatoren für Node-kapazität, Auslastung und Ressourcenmanagement
Wie dies euer Leben erleichtert: Erlaubt auf einen Block potenzielle Fehlkonfigurationen, wie z. B. fehlerhafte Replica-sets, zu erkennen, und erkennt Gelegenheiten zur Vereinfachung eurer Umgebung durch:
- Zuordnen von Pods zu Nodes basierend auf ihrer Ressourcennutzung.
- Optimieren der Anzahl der Nodes in einem Cluster.
- Sicherstellung der Hochverfügbarkeit auf Master-Node-Ebene.

Erkenntnisse, die ihr gewinnt:
- Verwendete vs. verfügbare Pods eines Nodes
- Ein sofortiger Hinweis auf über- oder unterprovisionierte Nodes in Bezug auf CPU, RAM, Speicher und Pod-Dichte mit einer neuen Farbmarkierung:
- Grün zeigt die Verwendung zwischen 40 und 75 % an: Dies ist ein gesunder Zustand für die Ressourcen eines Nodes. Ressourcen (CPU, RAM oder Speicher) befinden sich in einem Bereich, an der sie nicht als ungenutzt angesehen werden, noch befinden sie sich in einer Gefahrenzone, in der sie eure verfügbaren Ressourcen überschreiten und Pods evakuiert oder nicht platziert werden können.
- Gelb zeigt an, dass die Nutzung unter 40 % oder zwischen 75 und 90 % liegt: Die Nutzung unter 40 % (jeder Ressource) zeigt an, dass der Knoten möglicherweise überprovisioniert ist. Daher zahlt ihr für die Ressourcen, nutzt sie aber nicht. Die Nutzung zwischen 75 und 90 % wird als hoch angesehen — nicht erschreckend ungesund, aber sie verdient Aufmerksamkeit, um evakuierte Pods aufgrund nicht verfügbarer Kapzitäten zu vermeiden.
- Rot zeigt die Nutzung von über 90 % an: Eure Node-ressourcen befindet sich gefährlich nahe an der maximalen Kapazität. Wir empfehlen sich umgehend genauer mit Ressourcen auseinanderzusetzen, die über 90 % verwendet werden, da dies zu längeren Reaktionszeiten, zur fehlenden Antwort durch Kubelet und zum Beenden der Neuplanung von Pods führen kann.
Wenn die Farben für verschiedene Ressourcen nicht übereinstimmen, ist dies ein möglicher Indikator dafür, dass eine bessere Pod-Platzierung erreicht werden kann.
Zeigt alle Pods an, die zu einem Node gehören, mit ihren Gesundheitsindikatoren, Status und Protokollen
Wie dies euer Leben erleichtert: Bestimmt schnell den Zustand jedes Pods in eurem Node. Wenn ihr auf einen Node klickt und an den allgemeinen Informationen vorbei scrollt, werdet ihr zu einer Liste aller Pods innerhalb des ausgewählten Nodes weitergeleitet.
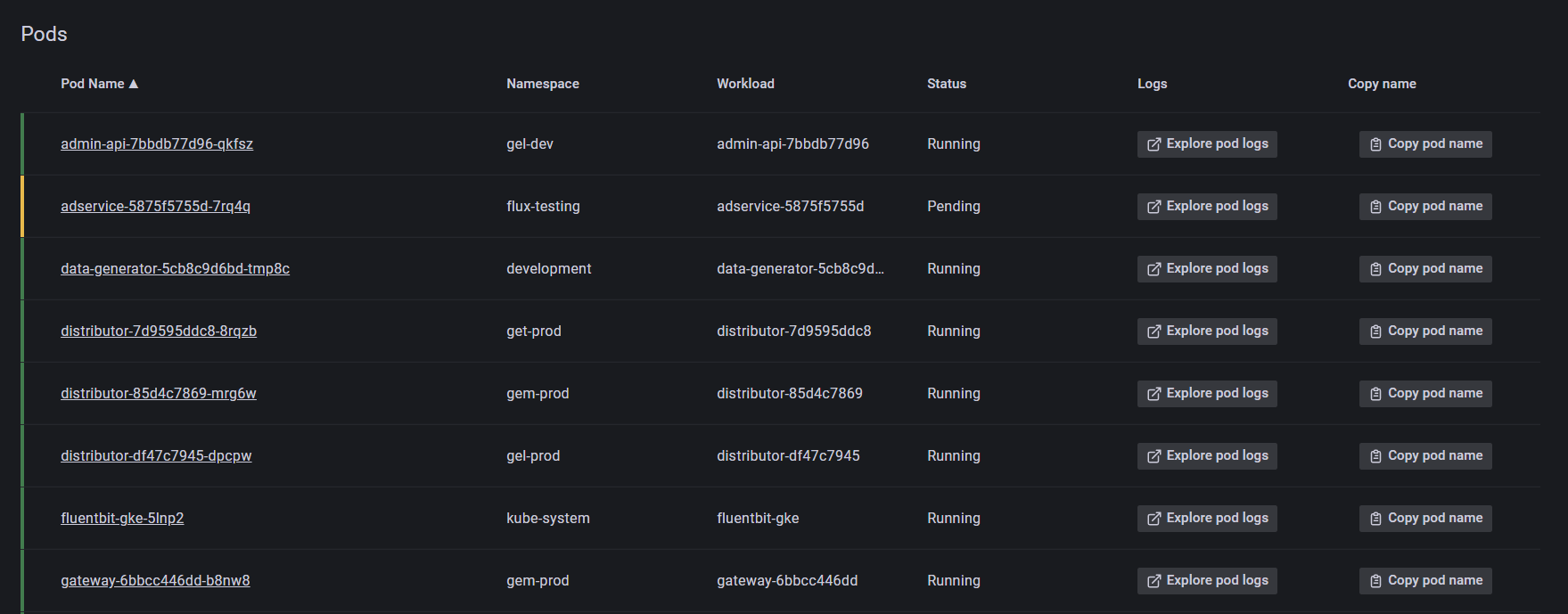
Ihr könnt die Gesundheit jedes Pods entsprechend der Farbmarkierung links neben dem Podnamen sehen.
- Grün: Pod läuft.
- Gelb: Pod ist ausstehend.
- Rot: Pod läuft nicht.

Erkenntnisse, die ihr gewinnt:
- Eine schneller und umfassender Überblick aller Pods, die zum Knoten gehören, mit Indikatoren für ihre Gesundheit und Status.
- Erkundet ungesunde Pod-Logs mit dem Ein-Klick-Log-Drilldown.

Erfahrt mehr über die Node-Observability in der Grafana Cloud
Für Kubernetes-Administratoren bietet die neue Funktion zur Node-Observability für die Kubernetes-Monitoring-Lösung von Grafana Cloud ein einfaches, aber leistungsstarkes Tool, das Schlüsselindikatoren liefert, um Probleme zu lokalisieren oder Verbesserungen in euren Kubernetes-Clustern zu skizzieren.
Während die Aufrechterhaltung der Leistung und des Zustands eurer Infrastruktur von entscheidender Bedeutung ist, ist die Ressourcennutzung genauso wichtig. Ausfallzeiten aufgrund von Vorfällen können zu massiven Kosten führen, und mangelnde Effizienz beim Ressourcenverbrauch kann leicht das Gleiche verursachen.
Mit der Knoten-Observability, der Clusternavigation und allen Funktionen der Kubernetes-Monitoring-Lösung von Grafana Cloud könnt ihr jedoch sicher sein, dass ihr eine vollständige Lösung für alle Kubernetes-Nutzungsebenen in eurem Unternehmen habt.
Wenn ihr wissen möchtet, wie Kubernetes Monitoring in der Grafana Cloud eurem Unternehmen helfen kann, besucht unsere Seite zu Kubernetes Monitoring-Lösungen, lest unsere zugehörige Dokumentation zu Kubernetes Monitoring oder seht euch unser Webinar „Kubernetes Monitoring Out-of-the-Box mit Grafana Cloud“ an. Weitere Informationen zu Best Practices für die Kubernetes-Überwachung findet ihr auch in der Dokumentation zu Kubernetes oder in unserem Leitfaden zur Einführung in Kubernetes Monitoring.


