

Databases and SLOs: How to apply service level objectives to your databases with synthetic monitoring
Wilfried Roset is an engineering manager who leads an SRE team and he is a Grafana Champion. Wilfried focuses on prioritizing sustainability, resilience, and industrialization to guarantee customers satisfaction.
Nowadays databases are commonly used to build information systems. Relational or NoSQL, self-managed or as-a-service, those databases often play a critical role in the overall health of your applications. It comes with no surprises that operations teams have monitoring in place to ensure the correct state of their precious databases and respond accordingly when needed.
What about you? Do you have probe-based monitoring? Maybe a log-based monitoring system or a metrics-based one? In fact, you probably have a mix of that, and this is a great starting point. This is enough to successfully support database infrastructure for years.
But what if there is room for improvement? What if we could level up your users’ experience while also improving the workload of your operations teams?
Service Level Objectives can answer both needs.
What are SLOs?
Service Level Objectives (SLOs) are quantifiable targets that organizations establish to measure the performance and reliability of their IT services. The primary purpose of SLOs, which were initially introduced by Google in the SRE book, is to ensure that IT services meet predetermined levels of quality, availability, and responsiveness. By setting specific SLOs, organizations can establish a shared understanding of what is expected from services and ensure that they are meeting the required standards. SLOs typically cover metrics such as uptime, response times, and error rates, and are often specified in terms of percentage or other quantifiable measures. Organizations using SLOs can maintain a focus on delivering high-quality services and ensure that their service providers are meeting the required standards, thereby reducing the risk of service disruptions and improving customer satisfaction.
That’s not all: With SLOs, organizations can use the concept of error budgets. For example, a service could have 99.5% uptime SLO over a month; therefore, the ops team has an error budget of 3.5 hours of allowed downtime. This error budget can then be used to pace deployment: If you haven’t burned your budget already, you can move faster and take risks, and if the remaining error budget is low or negative, you know that you must be careful.
How to use SLOs for databases
SLOs are often presented with HTTP API in mind. However, nothing prevents us from applying the same principles to relational databases. In fact, as soon as you realize that a database is an API just like a web server, the SLO framework starts to fit nicely. If you are still not convinced here is a parallel between both HTTP and SQL API:
| HTTP Verb | SQL DML |
| GET | select |
| POST | insert |
| PUT | update |
| DELETE | delete |
Now that we have established that SQL is an API just like an HTTP one, let’s try to apply the rest of the SLOs framework. In a production context, uptime can give additional information, but it is not the most actionable, especially if you have high availability in place. However, error rates and response times are more actionable for your operations teams:
- error rates: The percentage of queries that fail or result in an error.
- response times: The time taken to respond to a query.
Picture this: your database is 100% healthy in your monitoring (e.g: icinga, nagios, Prometheus …) but the simplest query takes 5ms. Are your customers happy? What if it is 50ms? 500ms? Another case could be that the most critical queries fail 0.001% of the time. Are your customers happy? What if those queries fail 0.01% of the time?
This is where those two SLOs become handy. Following the framework, your operations teams can define meaningful targets with the business owners relying on the databases. For example, you might decide that the business accepts at worst 0.01% of failed queries over a four-week rolling window. Or, the simplest queries must respond under 8ms 75% of the time over the same observation window.
How to implement SLOs for databases
Once you have reached an agreement about SLO targets with your business owners, operations teams need to choose how to implement them, by either:
- Sampling real traffic and compute the quality of service based on that data
- Relying on synthetic monitoring
Both methods are useful and provide interesting information, but there is a trade-off between the two.
1. Real-traffic sampling
Real traffic provides a picture of the production performance, but this requires generating the signals that will be used to compute the quality of service. Those signals could be either metrics or logs. The trick is to make sure those signals come from the applications.
Indeed, operations teams could be tempted to use the signals of the database, but the result will be a quality of service from a database point of view. Using database signals will not reflect the clients’ perspectives and by doing so we might miss some critical information.
For example, a database’s signals don’t include the network latency between the clients and the service. Relying only on such signals is error prone and could lead to a difference of understanding — one team could perceive the database as slow while the ops team would perceive the database as running as expected. Moreover, it means that your operations teams rely on the databases’ clients to measure the quality of the services they are providing 🙃.
2. Synthetic monitoring
On the other end, synthetic monitoring relies on inducing traffic and extracting signals from it. It is straightforward to put in place and most importantly it does not depend on the database’s clients; the operations teams have full control of such synthetic monitoring. They can make it more or less complex and adjust it as they go to make sure that the resulting signals are actually useful and actionable.
For those reasons, it is easier to start with synthetic monitoring. All you need is an agent. This agent will mimic what an application does with a database: open a connection, select, insert, update, and delete data. That’s it.
This agent should be deployed close enough to where the applications are deployed in your information systems — for example, in Kubernetes. This is a key factor. If the deployment of the agent is not similar to the applications, the signals that are produced will not be as accurate as you might want.
Let’s say your operations team provides a database from Kubernetes cluster A and this database is used by an application deployed on a Kubernetes cluster B. It is tempting for the database provider to deploy its synthetic monitoring agent where the database is hosted: Kubernetes cluster A. Well, what if there is an issue in the ingress of Kubernetes cluster A? Your synthetic monitoring agent deployed where the database is hosted will not witness the issue, but from the application point of view, the database is not reachable.
justwatch/sql_exporter, an open source Prometheus exporter that I configured as a synthetic monitoring agent, allows us to mimic an application and monitor your database from an external point of view. It is configurable to query a database and exposes metrics, such as the number of queries that run successfully and latency histogram. Finally it can be deployed on Kubernetes via its helm chart. In order to track your SLOs in the long run you will need a Prometheus remote storage. Grafana Mimir is arguably one of the best in the open source community.
Caveat about aggregation
Well, you have made it this far with SLOs that are clearly defined by operations teams and their stakeholders, and a synthetic monitoring agent that is well configured and deployed aside from the production applications. We now only need a few Prometheus queries to obtain the indicators. sql_exporter exposes four useful metrics:
- sql_exporter_query_failures_total: total number of queries issued by the exporter that have failed
- sql_exporter_queries_total: total number of queries issued by the exporter
- sql_exporter_query_duration_seconds_bucket: time spent querying the database by bucket
- sql_exporter_query_duration_seconds_count: number of observation in the histogram
Open source tools such as pyrra uses those metrics to compute your quality of services.
First win
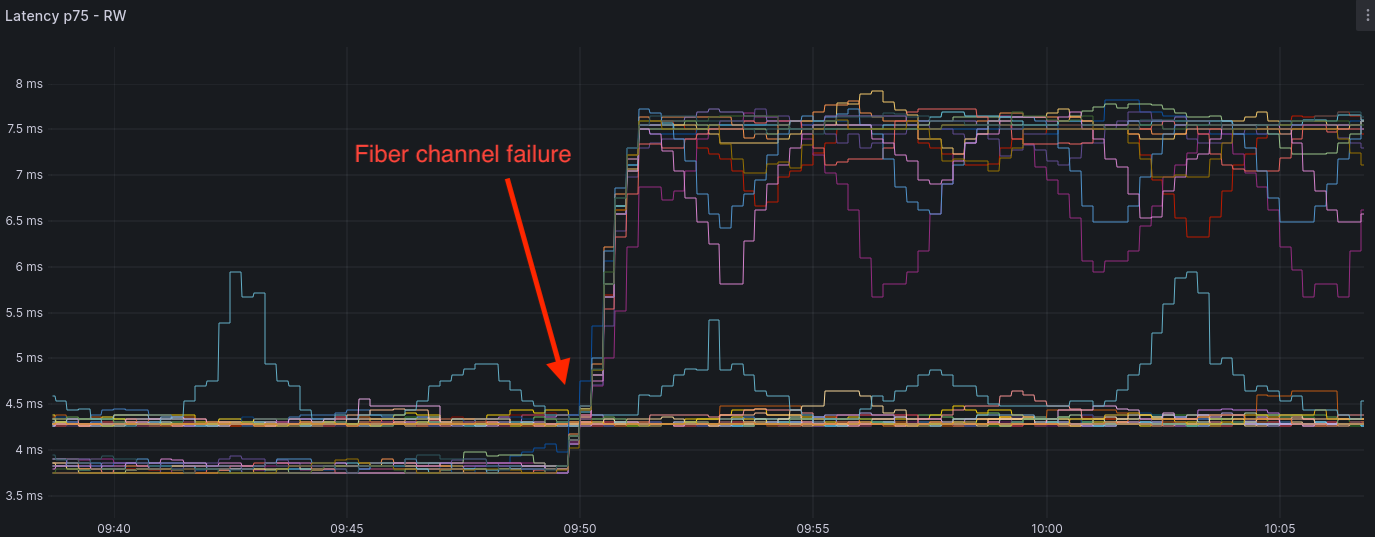
This setup is incredibly powerful. In one of my use cases, it has been able to detect a network issue with Grafana Mimir’s Alertmanager and confirm it with our Grafana operational dashboards. One of our teams was reporting slowness in their applications. From our point of view, everything was working as expected. Based on what we could see from the database point of view, all queries were performing as fast as usual, which means that the issue was between the applications and the database. Indeed, network equipment and cable failure happen even in the cloud. This was the case at that time: a faulty fiber channel was causing traffic to be routed differently, which in turn caused a latency increase of 4ms. Wow, a 4ms impact can be detected by synthetic monitoring.
This first win convinced us that we were rowing in the right direction.
SLOs are accessible to anyone and awesomely efficient to represent the quality of service. And as we have seen, SLOs can, and should, be applied to databases. It allows operations teams to answer customers’ needs while keeping the right focus on the quality of services. One could also investigate how to accurately use the error budget to prioritize operations and toil or define an SLO related to data freshness.


