

Demystifying the OpenTelemetry Operator: Observing Kubernetes applications without writing code
The promise of observing your application without writing code (i.e., auto-instrumentation) is not new, and it’s extremely compelling: run a single command in your cluster and suddenly application telemetry starts arriving at your observability backend. What else could you ask for?
The OpenTelemetry Operator aims to fulfill such a dream for Kubernetes environments by using a set of well known patterns such as operators and custom resources. However, for new users, the complexity of such an approach can feel overwhelming, particularly when things don’t work as expected.
In this blog post, you’ll learn how the OpenTelemetry Operator works and follow a step-by-step guide on how to use it to instrument your applications.

Overview
The OpenTelemetry Operator follows the Kubernetes operator pattern. In essence, it is a process running in your cluster watching for Kubernetes events. For example, the operator might detect that a new pod has been created, inspect its manifest, and decide to manipulate it to inject a new container depending on certain conditions (such as the presence of specific annotations in its PodSpec).
The operator can be configured via custom resources. Custom resources are a generalization of built-in Kubernetes resources (such as “Service” or “Deployment”) and allow extending the Kubernetes API with new, user-defined types of resources. New resource types can be added via CustomResourceDefinitions, which define the schema for each specific resource type.
In the case of the OpenTelemetry Operator, the operator watches for changes to custom resources it defines, including:
- Collector: Manages the lifecycle of OpenTelemetry Collector instances running within the cluster.
- Instrumentation: Defines how auto-instrumentation should be configured.
When a change is detected, the operator will do certain actions like creating/deleting pods or changing the way it instruments applications.
Now that we understand what the operator does, let’s look at how to use it.
Installation
The first step is to run the OpenTelemetry Operator in your cluster. For the purposes of this post, we will demonstrate how to do this with kind, a tool for running lightweight local Kubernetes clusters.
Let’s start by creating a new cluster:
kind create cluster -n otel-onboardingThe OpenTelemetry Operator requires secrets to exist under a specific name and following a specific format, which can be accomplished via cert-manager or OpenShift’s version of it. Let’s add cert-manager to our cluster:
kubectl --context kind-otel-onboarding apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.1/cert-manager.yamlNote: cert-manager takes some time to get fully up-and-running. To make sure we are ready for the next step, run:
kubectl --context kind-otel-onboarding wait --for=condition=Available deployments/cert-manager -n cert-managerNow we are ready to install the operator:
kubectl --context kind-otel-onboarding apply -f https://github.com/open-telemetry/opentelemetry-operator/releases/latest/download/opentelemetry-operator.yamlThis will run the operator and install all the required CustomResourceDefinitions, among other things. Our operator is now running, however it’s not doing much yet. Time to add a collector!
Note: Alternatively, you can use the OpenTelemetry Operator Helm chart for your installation.
OpenTelemetry Collector
A collector will help us batch, process, and transform our telemetry signals (traces, metrics, and logs) before sending them to a telemetry backend. Luckily, the OpenTelemetry Operator already knows how to install and configure the OpenTelemetry Collector. All we need to do is create a manifest with some configuration and it will take care of the rest.
kubectl --context kind-otel-onboarding apply -f - <<-"EOF"
apiVersion: opentelemetry.io/v1beta1
kind: OpenTelemetryCollector
metadata:
name: otel-collector
spec:
image: otel/opentelemetry-collector-contrib:latest
env:
- name: OTLP_ENDPOINT
value: '<my_value>'
config:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
batch: {}
exporters:
otlphttp:
endpoint: '${env:OTLP_ENDPOINT}'
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlphttp]
metrics:
receivers: [otlp]
processors: [batch]
exporters: [otlphttp]
logs:
receivers: [otlp]
processors: [batch]
exporters: [otlphttp]
EOFReplace the value of OTLP_ENDPOINT from <my_value> to the URL of the backend you want to send the signals to.
This step will create resources like a Deployment, Service, ConfigMap, ServiceAccount, ClusterRole, and ClusterRoleBinding.
In this example, we are using opentelemetry-collector-contrib, which is a distribution of the collector packed with additional components.
Instrumentation
With our collector up and running, we are ready to set up auto-instrumentation. The first step is to instruct the operator how to instrument applications. We will do this using a custom resource:
kubectl --context kind-otel-onboarding apply -f - <<-"EOF"
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: my-instrumentation
spec:
exporter:
endpoint: http://otel-collector:4318
env:
- name: OTEL_EXPORTER_OTLP_HEADERS
value: 'Authorization=Basic x'
python:
env:
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: http://otel-collector:4318
dotnet:
env:
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: http://otel-collector:4318
java:
env:
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: http://otel-collector:4317
nodejs:
env:
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: http://otel-collector:4317
EOFThe OpenTelemetry Operator will inject auto-instrumentation agents/SDKs into our running pods. The custom resource my-instrumentation we just created defines default settings for every supported language, including the OTLP endpoint (our collector service). Additional auto-instrumentation directives can be specified (docs here). Using this information, the operator will add the right environment variables and libraries to our running pods.
However, we are not done yet. Our OpenTelemetry Operator is running an OpenTelemetry Collector and knows how to auto-instrument applications for all supported languages, but how does it know which pods or applications to instrument? For that, we need to set some annotations for the deployment manifest of these applications.
Annotations and resource attributes
Annotations are used to indicate to the OpenTelemetry Operator that we want to instrument a given application and to specify its resource attributes such as service.name.
We recommend passing resource attributes through resource.opentelemetry.io/* annotations and letting the OpenTelemetry Operator generate a service.instance.id that will be based on the container, pod, and namespace names. For some resource attributes like service.name, it’s also possible to rely on the naming strategy of the OpenTelemetry Operator that will pick sensible defaults like the app.kubernetes.io/name label or deployment name, as documented here.
Annotations are added in the spec section of the Kubernetes deployments. Make sure to add them in the PodSpec (spec/template/metadata/annotations), and not in the main metadata section, as illustrated in the following example.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
template:
metadata:
annotations:
resource.opentelemetry.io/service.name: "adservice"
resource.opentelemetry.io/service.namespace: "ecommerce"
resource.opentelemetry.io/service.version: "1.2.3"
resource.opentelemetry.io/deployment.environment.name: "production"
...Each language has its own instrumentation annotations. We will describe each and also discuss some of the caveats.
In Java, the following annotation is used:
instrumentation.opentelemetry.io/inject-java: "true"The operator will make the following changes to pods with this annotation:
- Mount a shared volume under
/otel-auto-instrumentation-java. - Inject an init container. The init container will copy
javaagent.jar(the Java auto-instrumentation agent) to the shared volume. - Set the environment variable “JAVA_TOOL_OPTIONS” to “-javaagent:/otel-auto-instrumentation-java/javaagent.jar”, which effectively injects the agent at runtime.
- Set the rest of “OTEL_*” environment variables with the configuration defined in our Instrumentation custom resource.
The result is the same as if we had altered our application to make use of the OpenTelemetry Java agent, providing traces, metrics, and logs auto-instrumentation out of the box.
An important consideration for Python applications is the C library used in the Docker image. This may vary from application to application, and different distributions use different libc implementations. The runtime injected by the operator needs to be compiled against the same libc variant as our application’s image. Here are some common Linux distributions and associated libc implementations:
glibc: Ubuntu, Red Hat, Arch and its derivativesmusl: Alpine
Images using glibc need to be annotated with:
instrumentation.opentelemetry.io/inject-python: "true"
instrumentation.opentelemetry.io/otel-python-platform: "glibc"Images using musl need to be annotated with:
instrumentation.opentelemetry.io/inject-python: "true"
instrumentation.opentelemetry.io/otel-python-platform: "musl"When an annotation is found, the operator will do the following:
- Mount a shared volume under “/otel-auto-instrumentation-python”.
- Inject an init container. The init container will copy “/autoinstrumentation-
/.” to the shared volume. It effectively contains an alternative runtime with instrumentation already set up. - Set the environment variable “PYTHONPATH” to the newly copied runtime.
- Set the rest of “OTEL_*” attributes with the configuration defined in our Instrumentation custom resource.
The C library used by the container image is also relevant for .NET applications.
In this case, applications using glibc need to be annotated with:
instrumentation.opentelemetry.io/inject-dotnet: true
instrumentation.opentelemetry.io/otel-dotnet-auto-runtime: linux-x64 Applications using musl need to be annotated with:
instrumentation.opentelemetry.io/inject-dotnet: true
instrumentation.opentelemetry.io/otel-dotnet-auto-runtime: linux-musl-x64When an annotation is found, the operator will do the following:
- Mount a shared volume under “/otel-auto-instrumentation-dotnet”.
- Inject an init container. The init container will copy “/autoinstrumentation/.” to the shared volume. It contains startup hooks and additional libraries required for auto-instrumentation.
- Set several environment variables required to enable auto-instrumentation, including “DOTNET_STARTUP_HOOKS” and “DOTNET_ADDITIONAL_DEPS”.
- Set the rest of “OTEL_*” attributes with the configuration defined in our Instrumentation custom resource.
In the case of NodeJS applications, a single annotation is required:
instrumentation.opentelemetry.io/inject-nodejs: "true"When the annotation is found, the operator will make the following changes to pods:
- Mount a shared volume under “/otel-auto-instrumentation-nodejs”.
- Inject an init container. The init container will copy “/autoinstrumentation/.” to the shared volume. It contains the auto-instrumentation libraries for javascript.
- Set the environment variable “NODE_OPTIONS” to “–require /otel-auto-instrumentation-nodejs/autoinstrumentation.js”. This will inject auto-instrumentation into our application.
- Set the rest of “OTEL_*” attributes with the configuration defined in our Instrumentation custom resource.
Grafana Cloud
As a reference, we have prepared a GitHub repository with a working demo of all the steps mentioned in this post, pre-configured to send your telemetry to a Grafana Cloud stack and ready to use with Application Observability. This should help you get started in no time.
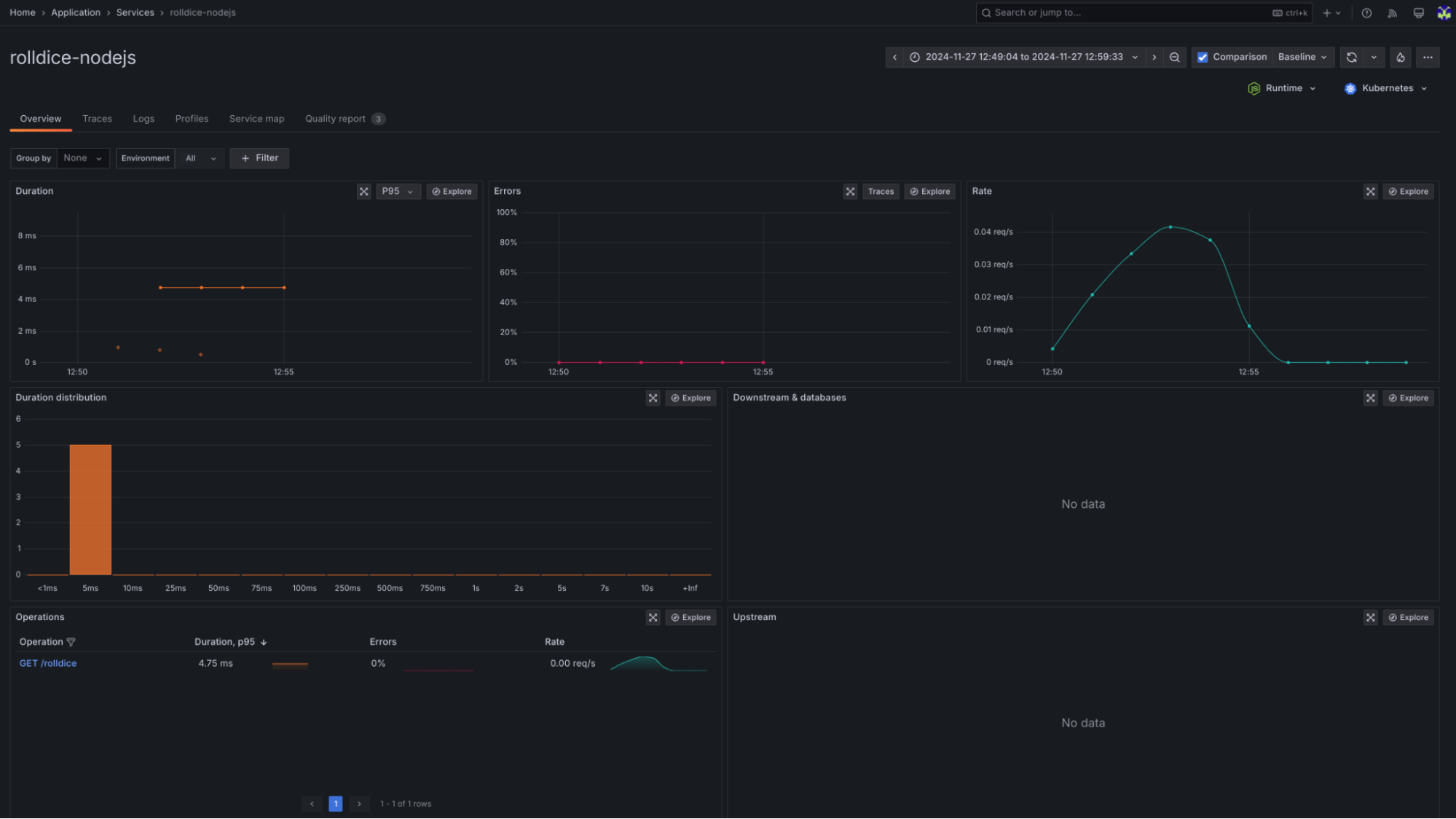
Start using the OpenTelemetry Operator with confidence
As you can see, OpenTelemetry Operator is not black magic. Hopefully, by better understanding what it does and how it works, you can more confidently make use of the conveniences it provides such as decoupling application development from instrumentation (which could be handled by independent teams) and managing the lifecycle of your collectors. Additionally, you will have a better idea on where to look when things don’t work as expected.
Happy auto-instrumentation!
Grafana Cloud is the easiest way to get started with metrics, logs, traces, dashboards, and more. We have a generous forever-free tier and plans for every use case. Sign up for free now!


