

How to securely connect Grafana to Google BigQuery using Workload Identity Federation
Umesh Pawar is a Senior Cloud Engineer at Searce, and is also the co-organizer of the Grafana and Friends Delhi Group. Umesh has been focused on infrastructure and app modernization, as well as observability solutions including the Grafana LGTM Stack, for the past two years.
With the Google BigQuery data source plugin for Grafana, you can easily query and visualize data from BigQuery directly in Grafana. This enables a wide range of use cases, such as creating dashboards for log analysis, billing data, sales metrics, traffic analysis, and digital marketing campaign tracking.
When running Grafana on Google Kubernetes Engine (GKE) and connecting to BigQuery as a data source, it’s essential to prioritize security. This blog explores how Workload Identity Federation can help you securely connect a Grafana instance running on GKE to the Google BigQuery service without exposing a service account key.
Authentication with GCP using Workload Identity Federation
You can securely access Google Cloud APIs from your workloads running in GKE clusters by using Workload Identity Federation for GKE.
If you are running Grafana on GKE in Autopilot mode, Workload Identity Federation is enabled by default. When you are running in Standard mode, you enable Workload Identity Federation on clusters and node pools using the Google Cloud CLI or the Google Cloud console. Workload Identity Federation for GKE must be enabled at the cluster level before you can enable it for GKE on node pools.
To enable on a new cluster:
gcloud container clusters create CLUSTER_NAME \
--location=LOCATION \
--workload-pool=PROJECT_ID.svc.id.googTo enable on an existing cluster:
gcloud container clusters update CLUSTER_NAME \
--location=LOCATION \
--workload-pool=PROJECT_ID.svc.id.googConfigure Grafana to use Workload Identity Federation for GKE
To let your GKE application — in our case, Grafana — authenticate to Google Cloud APIs using Workload Identity Federation for GKE, you need to create IAM policies for the specific APIs.
If you are using a Helm chart, just edit this code to values.yaml.
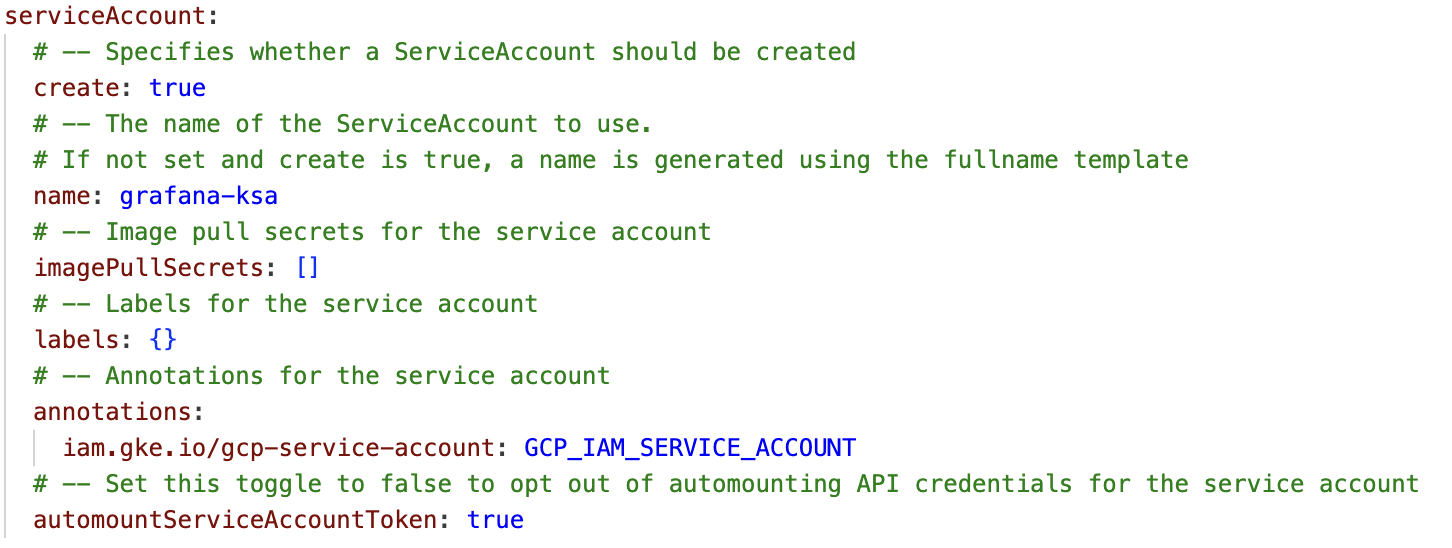
If you are deploying as a Kubernetes deployment, create a Kubernetes service account for Grafana to use. You can also use any existing Kubernetes service account in any namespace. If you don’t assign a service account to your workload, Kubernetes assigns the default service account in the namespace.
Grant your IAM service account the roles that it needs on specific Google Cloud APIs. In our case, Grafana wants to query the BigQuery API, so we will give it the BigQuery Admin role (but, in general, always follow the principle of least privilege).
gcloud projects add-iam-policy-binding IAM_SA_PROJECT_ID \
--member "serviceAccount:IAM_SA_NAME@IAM_SA_PROJECT_ID.iam.gserviceaccount.com" \
--role "ROLE_NAME"Create an IAM allow policy that gives the Kubernetes service account access to impersonate the IAM service account. As a good practice, grant permissions to specific Google Cloud resources that your application needs to access. You must have relevant IAM permissions to create allow policies in your project.
In the code block below, KSA_NAME represents the Kubernetes service account name attached to the Grafana workload, andNAMESPACE represents the namespace on which Grafana is deployed.
gcloud iam service-accounts add-iam-policy-binding IAM_SA_NAME@IAM_SA_PROJECT_ID.iam.gserviceaccount.com \
--role roles/iam.workloadIdentityUser \
--member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE/KSA_NAME]"Now we need to annotate the Kubernetes service account so GKE sees the link between the service accounts. Note: if you are deploying through Helm, skip this step and instead annotate on your Helm chart, as seen on the above step.
kubectl annotate serviceaccount KSA_NAME \
--namespace NAMESPACE \
iam.gke.io/gcp-service-account=IAM_SA_NAME@IAM_SA_PROJECT_ID.iam.gserviceaccount.comConfigure the Google BigQuery data source for Grafana
As mentioned above, the Google BigQuery data source plugin allows you to query and visualize Google BigQuery data from within Grafana.
Install the plugin
- Navigate to the BigQuery plugin homepage.
- On the right-hand side, click the Install button.
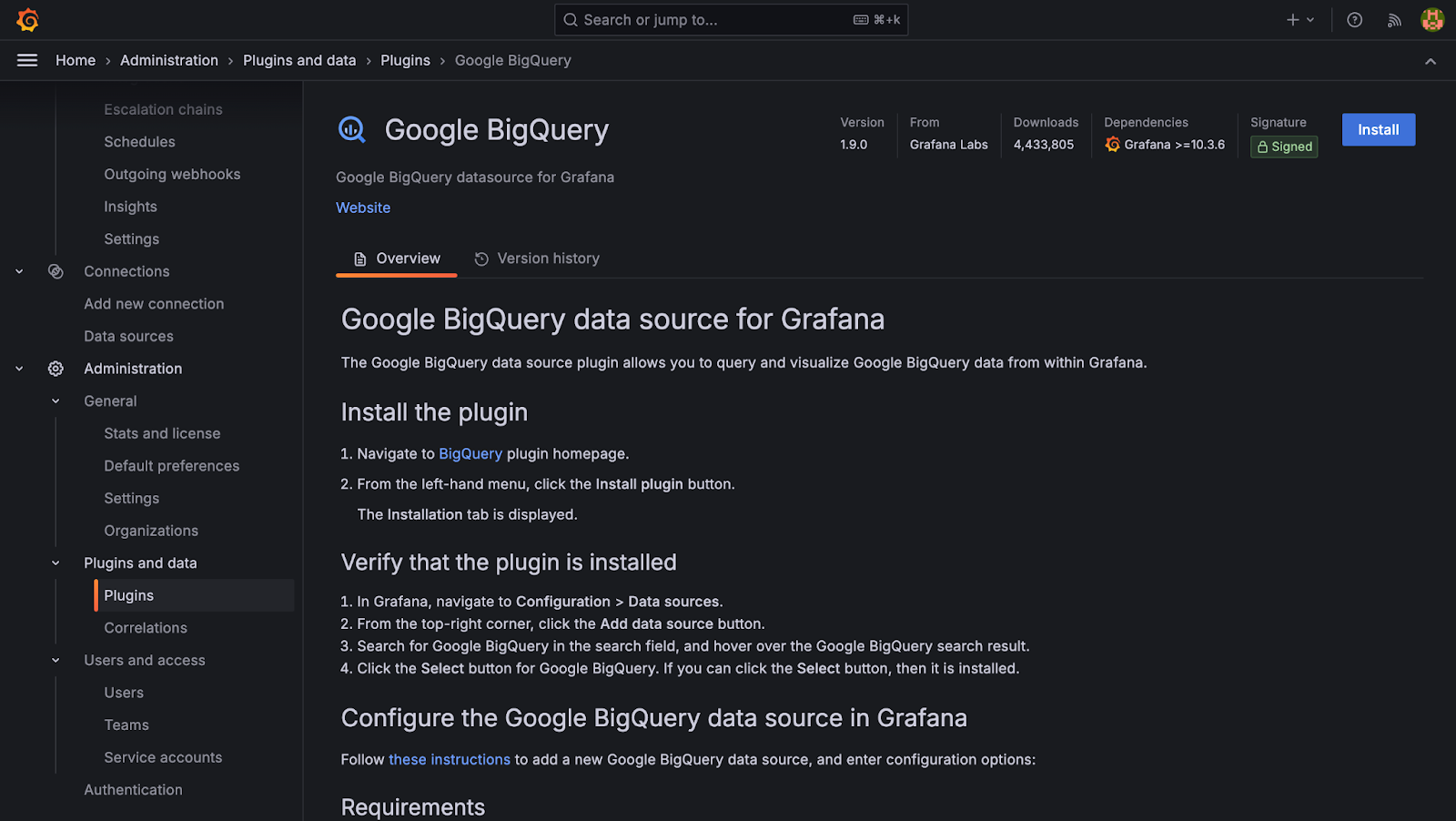
Verify that the plugin is installed
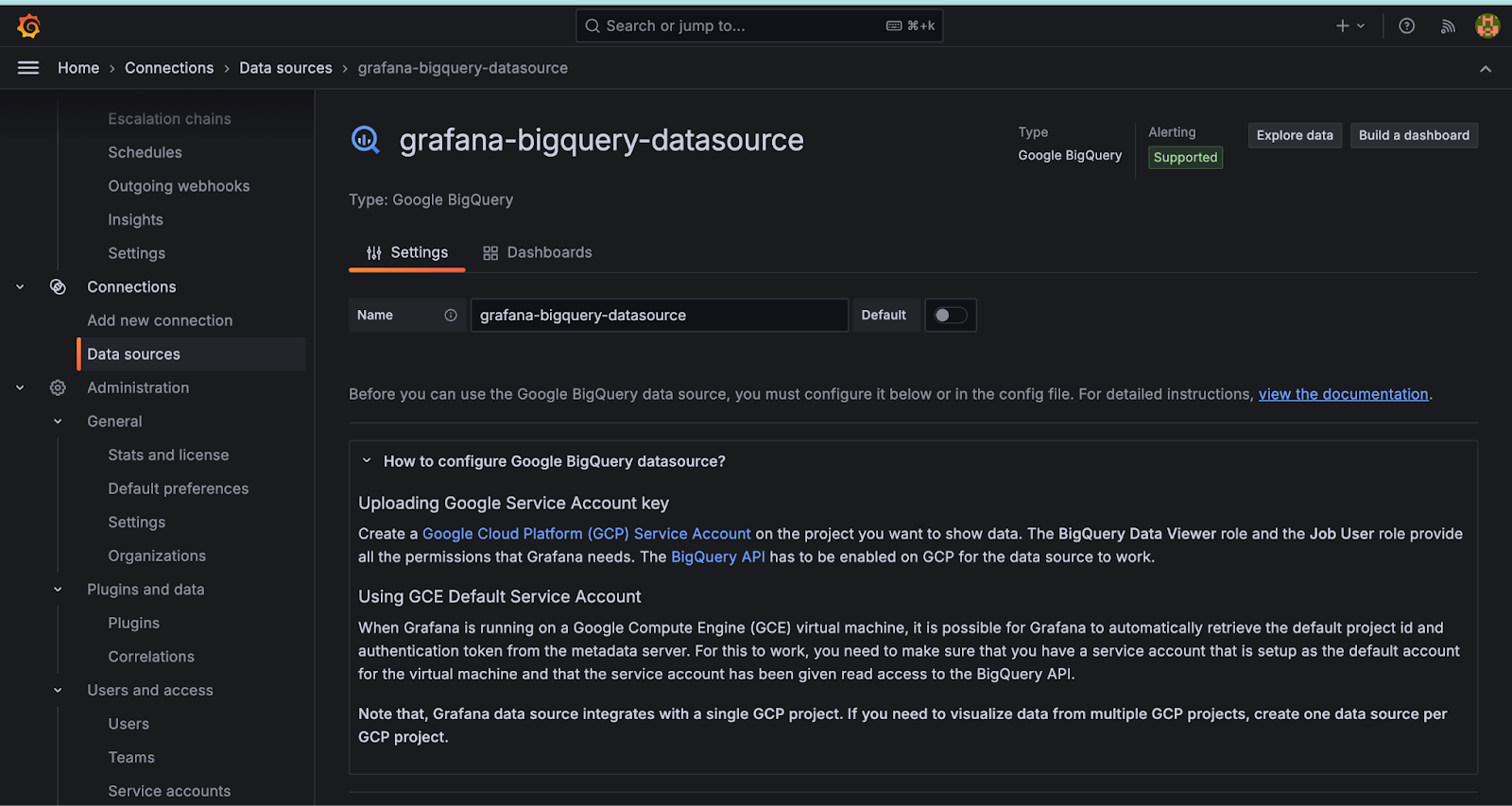
- In Grafana, navigate to Configuration > Data sources.
- From the top-right corner, click the Add data source button.
- Search for Google BigQuery in the search field, and hover over the Google BigQuery search result.
- Click the Select button for Google BigQuery. If you can click the Select button, then it is installed.
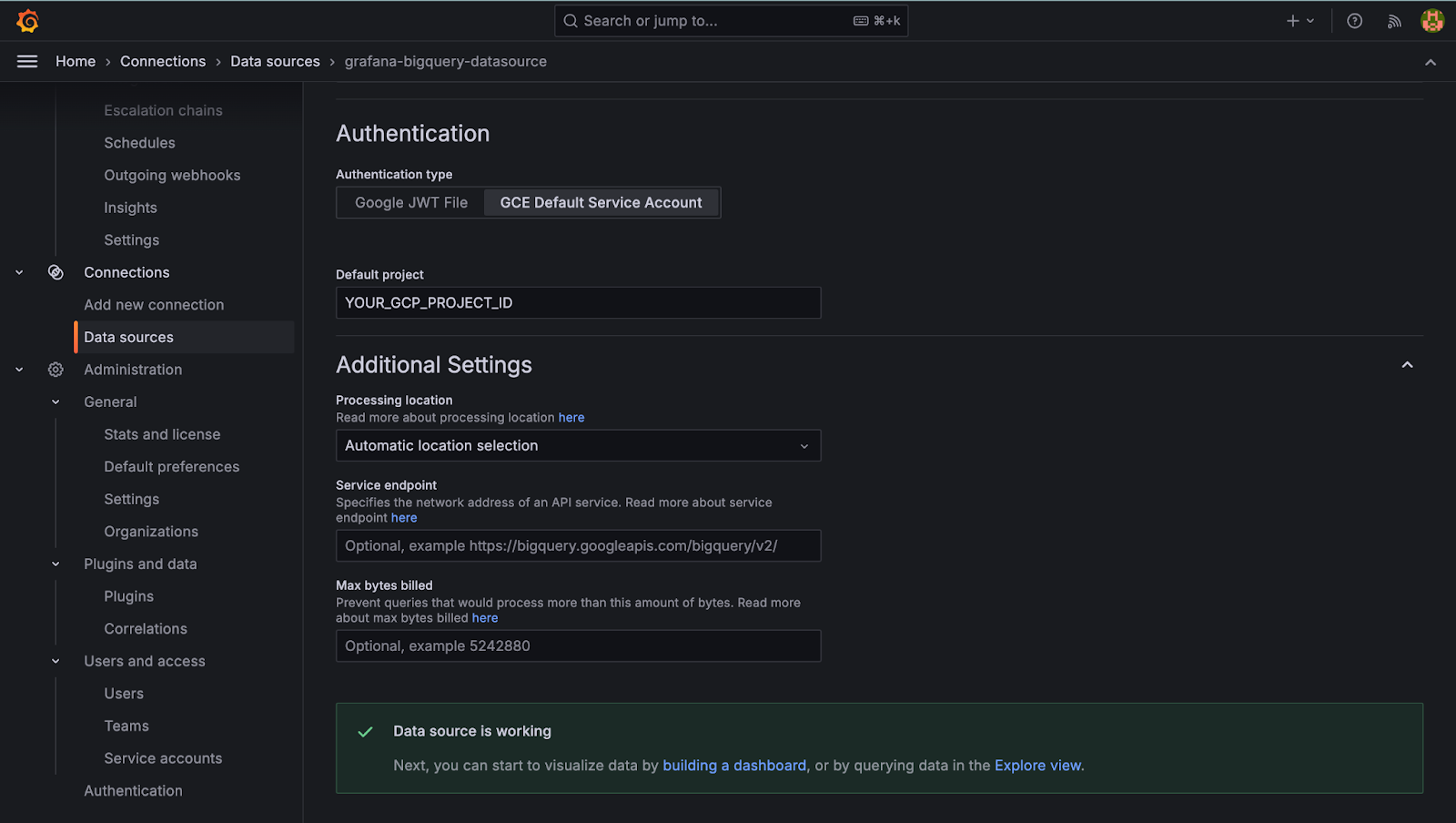
Authentication
By automatically retrieving credentials using Workload Identity Federation (when running Grafana on GKE), make sure that the service account has been given read access to the BigQuery API.
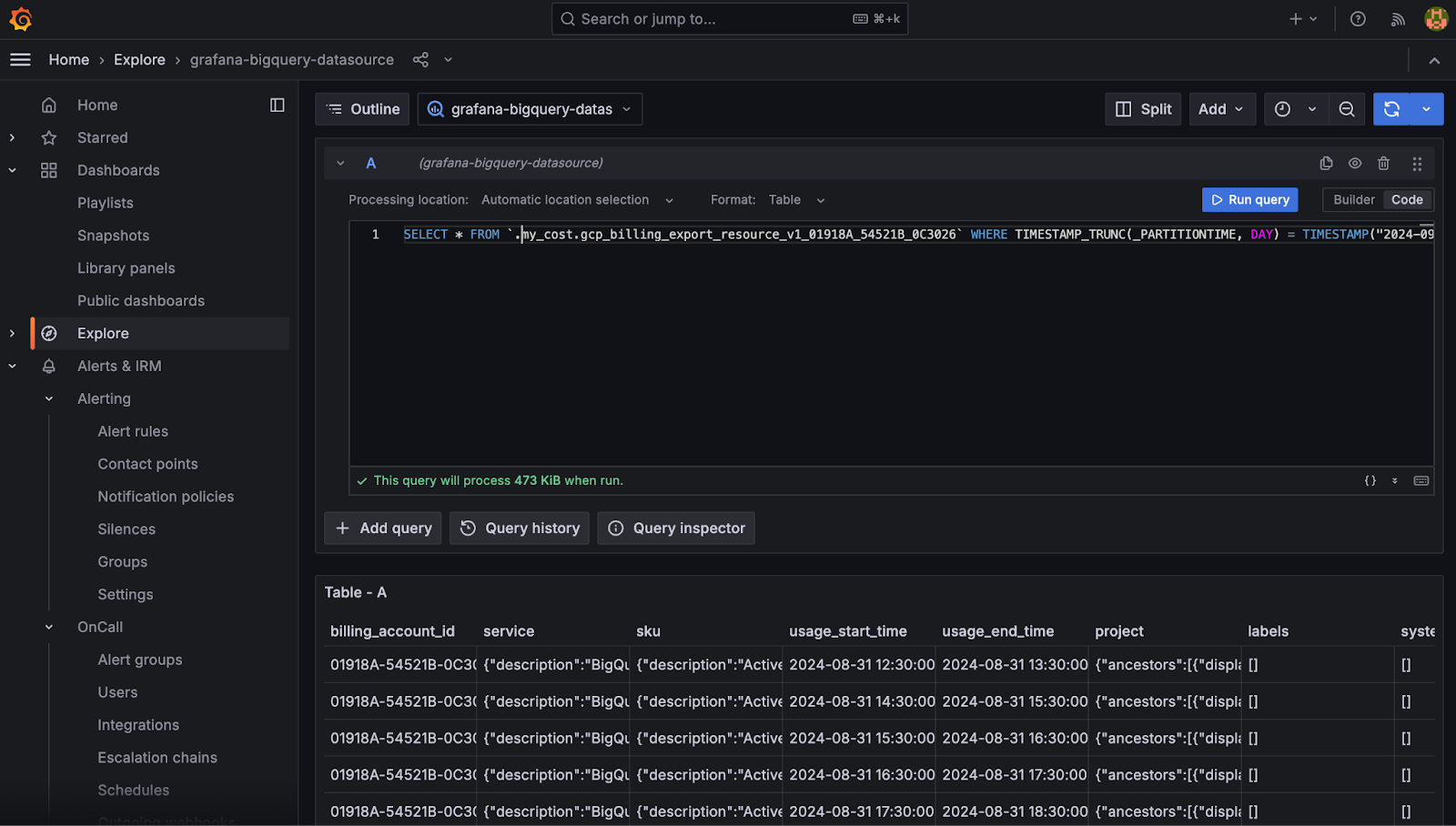
Query the data source
The query editor allows you to query the Google BigQuery data source. Queries can contain macros, which simplify syntax and allow your queries to be more dynamic. The SQL query editor comes with a rich support for standard SQL, as well as autocompletion for:
- BigQuery standard SQL language syntax
- BigQuery datasets, tables, and columns
- Macros and template variables
How to learn more
To explore more on this topic, you can check out these docs about Workload Identity Federation for GKE, as well as this page dedicated to the BigQuery data source plugin for Grafana.


