

Call me, maybe: designing an incident response process
Hey, I just deployed — and this is crazy. But the server’s down, so call me, maybe?
Making your services available at all times is the gold standard of modern software operations. The easiest way to reach this would be to just write bug-free software, but even if you reach this completely unattainable goal — stuff happens! Modern software rarely exists in a vacuum and often depends on a multitude of external services and libraries. Especially in the context of cloud services, you don’t control every part of your stack. Eventually, something can — and will — go wrong.
To counteract this, you will need a well-defined incident response process, which is a document that outlines which steps to take when an incident occurs. But what if you’re new to this world? You probably don’t even know which questions to ask in order to be prepared for when that moment arrives. That’s where this blog post comes in.
Of course, every organization and architecture is different, so I cannot offer a one-fits-all solution. Instead, this post should lead you in the right direction and help you ask the right questions before, during, and after an incident.
What’s an incident?
Before embarking on a journey through different scenarios and challenges (technical as well as social), you need to figure out when you consider something an incident.
Incidents can take many forms. As you develop your incident response process, a good starting point would be to document what constitutes an incident for your organization. It could look something like this:
An issue with a production system where any of the following is true:
- There may be visible impact for customers
- You need to involve a second team/squad to fix the problem
- The issue is unresolved after an hour of concentrated analysis
This list is by no means exhaustive. You might want to exclude some criteria or add some more, depending on your area of business. Financial impact might play a role in your decision to declare an incident as well.
In any case, you will want to avoid a situation in which an incident should have been declared hours ago, and now you’re dealing with the incident itself, as well as organizing the overhead of reconstructing the timeline from scratch.
How do we know we have an incident?
The first step in handling an incident is to know that something is broken. Issues can be reported manually (e.g., through support, a team member, or by a customer directly) or automatically through an observability solution. Regardless of how you approach reporting, your top priority should be to set up a system that lets you know when something is up as soon as possible.
An alerting system can be configured to observe specific metrics, logs, or other indicators and dispatch an alert when a specific indicator violates a rule.
For example, a simple alert rule could be:
Alert us if more than 0.1% of our HTTP responses are 500 for at least five minutes.
Here we specify the condition with specific values (more than 0.1% of our HTTP responses are 500) and also mark the duration for which this should hold true (at least five minutes). The duration is needed to avoid flaky alerts by single, short-lived outliers.
If you can, you should alert on service-level objective (SLO) violations. Check out Chapter 5 of the Google SRE Handbook for more information on this.
Manual reporting
Sadly, an alerting system will never catch all things that could go wrong. This is when it is useful to know how to create incidents manually. Another use case for manually created incidents is security incidents that need to be handled confidentially. Many incident response and management (IRM) solutions offer integrations into messaging tools, which simplify reporting and creating incidents.
When reporting an incident manually, make sure you provide enough information and make yourself available for follow-up questions.
When to notify?
Depending on the type of alert received, you might want to perform different actions. This process is called routing. During this stage, the alert metadata is matched and a preliminary severity is decided.
This severity can then be used to figure out if and how we want to alert. Finding the correct balance can be tricky. You don’t want to wake up an engineer in the middle of the night if it isn’t absolutely necessary, but you also don’t want to risk a potential problem getting ignored.
Severity levels
A useful framework for classifying incidents is based on their severity. Severities should act as a basic prioritization tool and display the urgency of an incident at a glance.
A common definition for different urgencies could look like this:
Critical: Urgently requires immediate attention when any of the following is true
- System is down and unable to function with no workaround available
- All or a substantial portion of data is at significant risk of loss or corruption
- Business operations may have been severely disrupted
Major: Significant blocking problem that requires help
- Operations can continue in a restricted fashion, although long-term productivity may be impacted
- A major milestone, product, or customer is at risk
Minor: May be affecting customers but no one is blocked
- No notable impact, or only a minor impact on operations and customers
Below you can find a table of example incidents and how they could be classified:
| Incident | Severity | Reason |
|---|---|---|
| Landing page not reachable | Critical | Users can no longer access the target system |
| Search recommendations unavailable | Major | Core functionality still works, but users might not find what they are looking for |
| A user’s first and last name are switched | Critical/minor | Depending on the system affected, this could be a minor issue (e.g., it only shows up wrong on your profile) or cause significant issues (e.g., we’re invoicing the wrong person) |
These examples also showcase that it is hard to classify incidents with limited information. When new information becomes available, it can change the severity during an incident.
Who to notify?
This will be one of the trickier questions to answer as it needs to take into account a lot of different aspects:
- Who could fix this?
- Who is available?
- Are they awake?
- Are they allowed to work at this time?
To store this information in an easily digestible way, you will need to group people into teams (Who could fix this?) and plan a schedule for those teams (Who is available? Are they awake?).
Deciding which team can handle the incident should be straightforward in modern engineering organizations: If you build it, you maintain it. Depending on your organizational layout, this could also be an operations team.
Tip: Create an onboarding document for new team members outlining severities, classifications, on-call responsibilities and places they need access to. This can significantly help in onboarding new team members.
Planning a schedule
The schedule defines who is on-call during a specific time. When designing your schedule, keep the following in mind:
- Duration: Being on call for multiple weeks can be very exhausting, but shifting every day will lead to headaches as well.
- Predictability: Engineers will want to plan personal activities in advance and need to know if they’re on-call during that time.
- Balance: This should go without saying, but try to distribute shifts evenly to all team members.
- Legal constraints: Different countries have different regulations on how long and how often someone can be on call.
If you have a globally distributed team, you might want to consider a follow-the-sun rotation in which you’re only on-call during regular working hours. For smaller, geographically centralized teams, rotating weekly is a good starting point.
What does it mean to be on-call?
When you’re on-call, you’re expected to be reachable via some agreed-upon communication channel. Usually, this will be an app on your phone but it could also be a physical pager. When an alert is triggered, you’re required to handle it according to procedure. This could be simply acknowledging the alert (if it can wait for the next business day) or opening an incident.
The time you have between receiving an alert and acknowledging it (or getting to work on it) should be agreed upon beforehand so the engineer can plan their day accordingly.
How to notify?
Let’s recap! We’ve emitted an alert (automatically or manually), routed it to the right team at the right severity, and figured out who to alert at this time. The next question will be: How can we reach them?
This is the responsibility of escalation chains and notification policies. They continue routing the alert through notifications and integrations.
An example escalation chain could look like this:
- Notify the current engineer on-call
- Post in a Slack channel
- Wait 20 minutes
- Notify the secondary on-call engineer
When notifying an engineer, their respective notification policy will decide which bells should go off. This could look like:
- Send a mobile push notification
- Send an email
- Wait five minutes
- Call my number
If at any point the alert gets acknowledged, the remaining steps are skipped.
What happens when I get an alert?
If you get paged (or notified in any other way), it is up to you to decide if this warrants an incident based on the information you’ve been given. If you’re unsure, creating an incident is always the safest bet. Some situations in which you might not want to create an incident are provable false positives, quick routine remediation, or caused by another currently active incident.
How to handle an incident?
Now that you know when and how to declare an incident, let’s take a closer look at an example framework for the different roles and responsibilities during the handling of an incident. The following rules are based on our internal IRM handbook and are what we use to power Grafana Cloud. While they are fit for general use, make sure to always think through this with your organizational context in mind and change parts as you see fit.
Who does what?
When declaring an incident, we have two roles to fill: the commander and the investigator. The engineer currently on call will by default be the investigator, while the secondary on-call engineer takes the role of the commander. Of course, if someone has more in-depth knowledge, they can volunteer for any of these roles — even during an incident! The only requirement is that this transfer is agreed by the current and new engineer to avoid both thinking the other is currently working on this incident.
Investigator
The investigator deals with resolving the incident. How this looks depends on the used technology, systems, experience, and impact, so there are no clear guidelines on what to do. If you have runbooks, these may be a good place to start. Runbooks are documents outlining the identification and resolution of known or anticipated problems (e.g. a disk filling up, certificates not renewing).
Tip: Prioritize mitigation of the symptoms of the incident over fixing the issue in a permanent way within the handling of the incident. The goal is the shortest time to mitigate the impact that the incident produces whilst preserving evidence that aids the investigation.
While working on the incident, make sure to communicate new findings as soon as possible and keep an eye out for your emotional state. If you feel panicky or overwhelmed, ask the incident commander for more support.
Commander
As a commander, your job is to support and communicate. Your top priority is to get the investigator what they need. This can be access to systems, access to people on other teams, or getting in touch with external vendors.
The commander communicates the status of the incident to other teams (and customer support, if applicable) and helps the investigator to prioritize. They can also offer debugging ideas and hypotheses but only in a hands-off manner. Another responsibility is extracting the important information found by the investigator to document the incident as it progresses.
As with the investigator, periodically introspect your emotional state. If things get too stressful, ask another person to take over as a commander.
Other people
Sometimes incidents require collaboration of a multitude of different people. If you are not also working on an incident, it is assumed that you will give your support if called upon by an incident commander. Declaring an incident gives the incident commander authority to commandeer any person within the company at any level to help contribute towards the resolution of the incident.
The investigator remains the owner of the investigation, and other individuals involved should work to support the investigator.
What happens afterward?
As soon as the user-facing impact is mitigated, the incident can be considered resolved. However, this does not mean that everything is fixed and you can forget that anything ever happened. There are a few more steps you need to take until work on the incident can be considered done.
Creating a post-incident review
As an incident commander, you’re tasked with creating a post-incident review (PIR) document. Work on this can actually start during the incident. The PIR is used to document what happened during the incident and how it was resolved. It can also serve as a retrospective to discuss what went well, what went wrong, and where we got lucky.
Tip: If an incident was declared because of a false positive or turned out to be invalid, a PIR is not strictly needed. However, it can still be useful to reflect on the incident and learn how to avoid spending resources on this in the future.
PIRs are intended for internal education and can serve as a reference for future incidents. If you need to communicate the incident to customers or the broader public, create a separate document based on the PIR with the updated target audience in mind.
To improve this workflow, create a template in the document storage solution of your choice (Google Docs, Confluence, or Git). You can find an example for this in our newly released act-kit. When copying an existing template, take your time to reflect on headings and content to make sure it fits for you.
Creating follow-up tasks
As the goal of the investigator is to fix the symptoms, this can often result in a temporary fix being applied to resolve the incident as quickly as possible. An old saying in software is “Nothing is more permanent than a temporary fix”. It is important to create follow-up tasks directly after resolving the incident. Whether this task is fixing a bug, changing the configuration or rewriting the whole application from scratch depends on the root cause of the incident.
Cheat Sheet
We’ve covered a lot of ground so far. To help you organize your thoughts before you build your incident response plan, I created this cheat sheet you can use as a quick reference going forward.
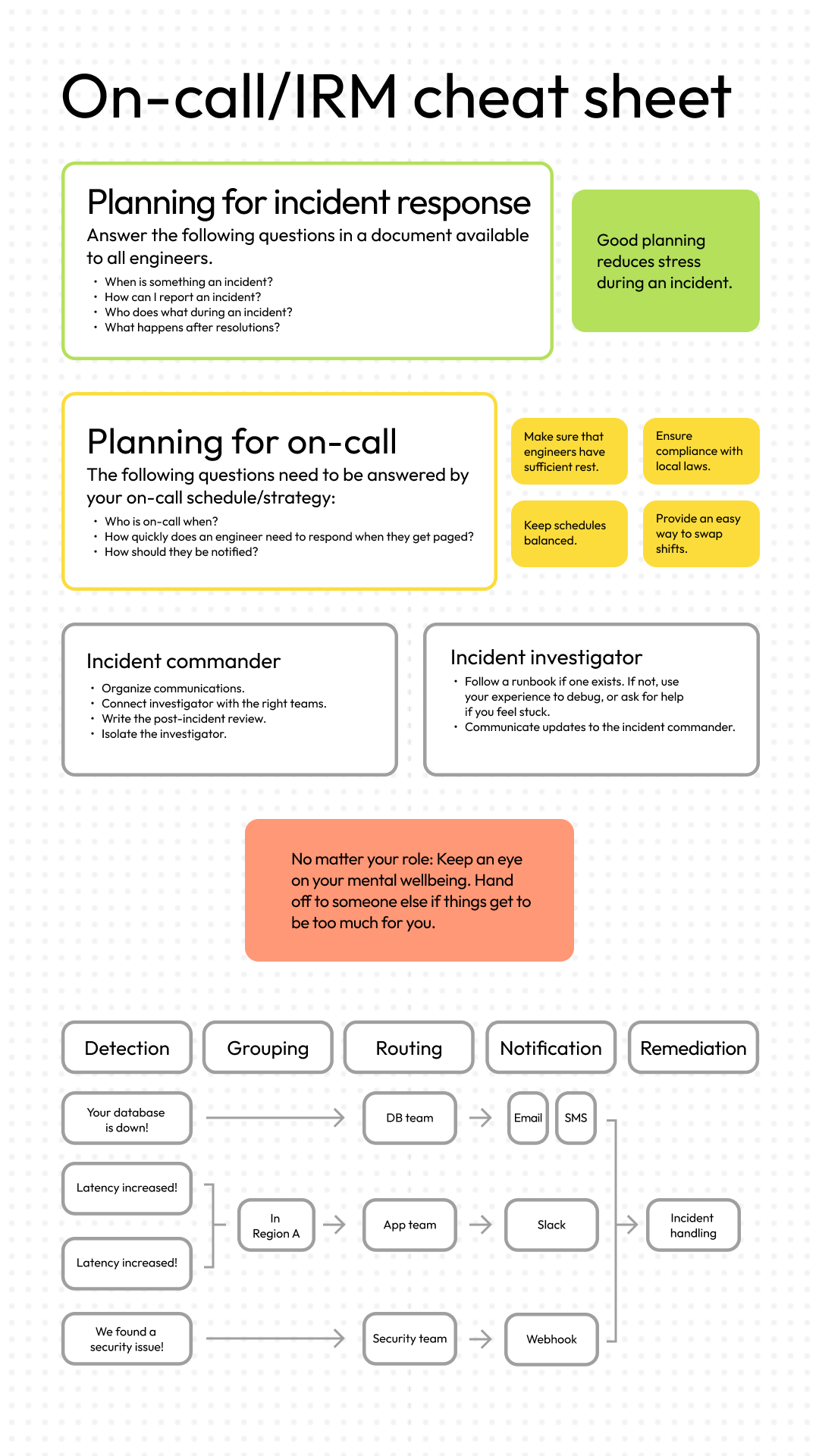
What else?
While this post should help you ask the right questions when setting up your on-call or IRM flow, the possibilities are endless. Maybe you want to manage your on-call rotation as code, explore ChatOps, or hook up created incidents to a status page.
No matter where your journey takes you: be mindful of what’s in the best interest of yourself, your team, as well as your organization, and you’ll be on the right track to find the tools and techniques that work for you.
Simplify incident response with Grafana IRM
And while a solid incident response process is an essential piece of guidance for your team, you don’t have to do everything you’ve outlined in the document alone. Grafana IRM provides a host of features intended to streamline and facilitate incident response and on-call management. This includes features to trigger incidents, automate alert routing and escalation chains, and simplify on-call scheduling.
Grafana Cloud is the easiest way to get started with metrics, logs, traces, dashboards, and more. We have a generous forever-free tier and plans for every use case. Sign up for free now!


