

OpenTelemetry best practices: A user's guide to getting started with OpenTelemetry
If you’ve landed on this blog, you’re likely either considering starting your OpenTelemetry journey or you are well on your way. As OpenTelemetry adoption has grown, not only within the observability community but also internally at Grafana Labs and among our users, we frequently get requests around how to best implement an OpenTelemetry strategy.
Grafana Labs is fully committed to OpenTelemetry, building compatibility into our open source projects and our products while also remaining actively involved in the OTel community.
In the past year, our two main areas of focus in OpenTelemetry have been interoperability with Prometheus and instrumentation SDKs. We’ve also contributed support for Prometheus native histograms in the OTel Collector. In fact, Grafana Labs is the only company that is a leading contributor to both projects (#1 company contributor to Prometheus and a top 10 contributor to OTel).
Below is a compilation of OpenTelemetry best practices based on commonly asked questions, frequent topics of discussion, and our own experiences. We hope you will find some helpful tips and tricks to keep in mind throughout your implementation.
OpenTelemetry instrumentation
TL;DR: Use auto-instrumentation to get started.
Auto-instrumentation is designed to encompass a wide variety of use cases, so it won’t always provide specialized information (for example, any proprietary IP or business code you have implemented). If in doubt, start with auto-instrumentation and if you are missing something, then look at adding in manual instrumentation where detail may be lacking and to take away what you do not need.
You can learn more about Grafana auto-instrumentation for .NET and Grafana auto-instrumentation for Java.
Initialize OpenTelemetry first
TL;DR: Make sure you actually collect everything you want.
You should always initialize OpenTelemetry and any variables defined in the front of your application before using any libraries that should be instrumented. Otherwise you won’t be able to find the spans you need.
In the case of auto-instrumentation, this means adding the relevant OpenTelemetry frameworks to your code (for example, in Java this consists of including the OpenTelemetry JAR file alongside your application).
In cases where you’re manually instrumenting, this consists of importing the OpenTelemetry SDK libraries into your code.
Tip: Speaking of manual instrumentation—don’t forget to end your spans! A span should always have a start and an end.
OpenTelemetry attribute generation
TL;DR: Ensure that your data is consistent and meaningful.
In general, you should only include attributes that are relevant to the operation that the span represents. For example, if you are tracing an HTTP request, you might include attributes such as the request method, the URL, and the response status code.
If you are unsure whether or not to include an attribute, it is always better to err on the side of caution and leave it out. You can always add more attributes later if you need them!
Dos and don’ts for OpenTelemetry attributes
- Do not put metrics or logs as attributes in your spans. Let each telemetry type do the job its best at.
- Do not use redundant attributes. There is no need to have five different attributes that all specify the service name. This will just cause confusion for the end users and add bytes to your span size.
- Do consider service flow and what is happening in the context of the current span only when considering what attributes to add.
Use OpenTelemetry semantics
TL;DR: Semantics are the way.
The OpenTelemetry semantic conventions provide a common vocabulary for describing different types of entities (attributes and resources), which can help to ensure that your data is consistent and meaningful. If you are just starting out with OpenTelemetry, this is a great methodology to implement early on to ensure a common framework.
Speaking of frameworks, when naming attributes and resources, prioritize descriptive names and avoid unfamiliar abbreviations or acronyms. Establish a consistent style for capitalization, formatting (e.g., suffix or prefix), and punctuation.
Correlating OpenTelemetry data
TL;DR: Be strategic and realistic about the use cases for metrics, logs, and traces, and generate the right telemetry type to answer questions.
Ensure you are able to correlate this data seamlessly so that you can jump to the correct data no matter what backend it’s stored in. For example, log the traceID in the logs for the application you’ve instrumented and take advantage of metadata. Read more strategies here!
OpenTelemetry batching
TL;DR: Batch and compress telemetry based on size or time to query data faster.
To batch, or not to batch? This is another one of those “it depends on use case” answers. In general, batching is likely preferred as it will reduce your network overhead and allow you to better plan around resource consumption; however, the batch processor will add some processing time to the data, increasing the lag between generation and availability to query.
If your application requires almost real-time querying, it may be best to use simple processing for that one app and batch for the others, but even with batching, the data will process extremely quickly so this likely won’t impact most!
Sampling in OpenTelemetry
TL;DR: Find a sampling strategy that fits your use case.
Sampling is likely a good idea, but it depends on your use case. While Grafana Tempo is more than capable of storing full fidelity trace data, at some point it may become a cost consideration or, depending on throughput, ingest volume.
The best sampling strategy for you to select will depend on the specific requirements of the system. Some factors that may need to be considered include the amount of data that is being generated, the performance requirements of the system, and the specific needs of the telemetry consumers. There is no one-size-fits-all solution, so you will need to experiment to find the best policy for your needs.
OpenTelemetry sampling: Pros
- Reduces the amount of data collected to save on storage and bandwidth costs
- Improves performance because less data needs to be processed and transmitted
- Filters out the noise and focuses on specific parts of the system
OpenTelemetry sampling: Cons
- Introduces bias into the data because not all of the data is collected
- Can be more difficult to troubleshoot problems since the full context of the problem may not be available
- May be difficult to implement and manage because it requires careful consideration of the specific needs of the system
In many cases, head sampling with remote control paired with probabilistic tail sampling is sufficient for most use cases. Read our Introduction to trace sampling blog post for different strategies.
Span events
TL;DR: Take full advantage of your trace data.
Span events are used to record interesting and meaningful events that occur during any singular span. A span will always have a start and end — so think of the user clicking “checkout” — this will record the start (click) to the end (page load). An event is a single point in time, such as an error message or recording when the page becomes interactive. Auto-instrumentation will collect relevant information in span events for you. For example, in auto-instrumented Java applications, all exceptions will be automatically logged into the span event field.
Context propagation
TL;DR: Make sure you have the right data when and where you need it.
While it’s possible to propagate context manually, it is a better practice to allow the instrumentation libraries to handle it for you. For most OpenTelemetry SDKs, both HTTP and gRPC communication will include propagators if using auto-instrumentation. Unless you have a unique use case or systems in your environment that require otherwise, you should use W3C Trace Context Recommendation.
Use baggage where applicable
Baggage uses HTTP headers to propagate key-value pairs between spans when that data may not be available to spans further down the stack. Take an example of an origin IP. This data may be available to the first service in the transaction, but unless you specify to propagate it along to the remaining spans, those later services cannot access that data. When you use baggage, you gain the ability to add attributes to future spans based on the values being stored as baggage.
Span metrics and service graph connector
TL;DR: Always take advantage of span metrics for easy analysis of RED data!
Span metrics enable you to query, analyze, and build custom visualizations based on aggregations of your span data in the form of request rates, error rates, and duration over time (RED metrics).
In the fully managed Grafana Cloud platform, span metrics and service graph metrics can be automatically generated from your ingested traces. This is the same functionality that OpenTelemetry offers with these connectors, and you can certainly implement generation on the collector side or by using Grafana Agent in Flow mode, if preferred. It doesn’t matter — the important part is that span metrics are generated somewhere!
You can read more in GitHub about how to configure the span metrics connector and the service graph connector in the collector.
You can also refer to our documentation to learn more about how the metrics generator and span metrics generation work in Grafana Cloud. You can also check out our blog post on generating ad hoc RED metrics with Grafana Tempo.
Options for generating RED metrics
In Grafana Cloud, metrics are generated based on the spans ingested. If any type of tail sampler is utilized in Grafana Agent or the OpenTelemetry Collector, then spans for those traces that are not sampled are dropped before ingestion. In a case where a 10% probabilistic sampler is being used, this means that you are only seeing metrics for 10% of the trace estate. This obviously will greatly affect the generated metrics being observed, and should sampling of errors, latency, etc. take place, then the metrics may not be useful (although Tempo and Grafana Cloud Traces do include an option to roughly multiply up span values to make them representative).
Grafana Agent (and the OTel Collector if the pipeline is configured correctly) generates metrics from spans before tail sampling occurs. Because of this, relying on local metrics generation that can be sent to Grafana in these collectors will still give an accurate reflection of all traces pre-sampling. This will allow for accurate metric active series even with sampling.
Note: This does not include head sampling. Head samples are dropped pre-export by application code and will never make it to the Agent/Collector!
OpenTelemetry architecture
TL;DR: Use a collector!
Whether you choose Grafana Agent distribution or the OpenTelemetry Collector, this will allow you to batch, compress, mutate, and transform your data before storage. As a centralized proxy, this implementation also provides a central single location to manage secrets.
With all of the flexibility provided by the collector, the use cases you can implement are endless. Even if you do not have anything in mind right now, it will almost certainly benefit you in the long run to deploy a collector. Typically we advise that you send directly to an OTLP endpoint in testing or small scale development scenarios only.
A final architecture might look something like this:

If you’re still wondering about collectors, check out our recent Do you need an OpenTelemetry Collector? blog post.
OpenTelemetry Collector deployment architectures
There are a lot of considerations to make when deciding on your production architecture for your deployment. For a look at the different deployment options, refer to our documentation on use cases.
Use exporters
TL;DR: Make sure you send your data somewhere.
So your collector is up and running? Use one or more exporters in your Grafana Agent or OpenTelemetry Collector to send your data to a backend or log to console for troubleshooting. And if you’re testing or actively developing, why not both? Both options support using multiple exporters, so you can use a combination of vendor specific and logging exporters in the collector.
Tip: Know your restrictions
With Grafana Tempo, there are some default limits set around trace/span and attribute sizes.Max Attribute value length: 2046
Max Trace size: 50mbWe also implement the OpenTelemetry specs for default limits.
Get the most our of your OpenTelemetry data with Grafana Cloud
Grafana Cloud is the easiest way to get started with visualizing, querying, and correlating your OpenTelemetry data efficiently. By enabling Application Observability, which is compatible with OpenTelemetry and Prometheus, you will have a set of prebuilt Grafana dashboards natively integrated with your OpenTelemetry data. While out of the box dashboards are always nice, there may be times when you want to build your own. Below is just one example of how you can build a custom dashboard based on your OpenTelemetry traces and span metrics.
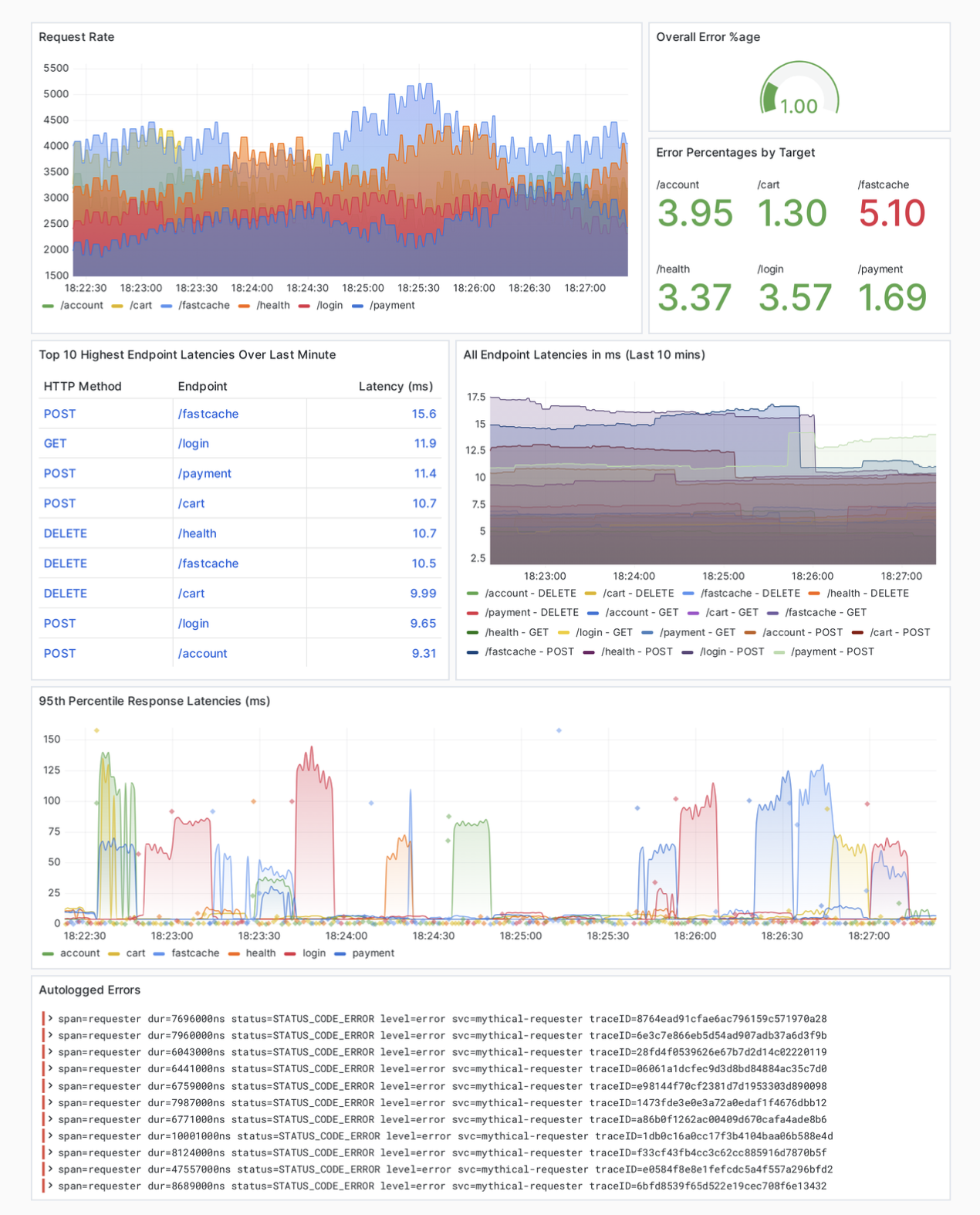
If you are using Grafana Cloud, you can also start to think outside of the box and integrate your OpenTelemetry data with other features. For example, wouldn’t it be great to use Grafana Machine Learning to discover if your application sees an abnormal increase in requests outside of the expected values based on day, time, or seasonality?
To learn more about OpenTelemetry and Grafana Cloud, read our documentation.
Grafana Cloud is the easiest way to get started with metrics, logs, traces, dashboards, and more. We have a generous forever-free tier and plans for every use case. Sign up for free now!


