

How Grafana Labs switched to Karpenter to reduce costs and complexities in Amazon EKS
At Grafana Labs we meet our users where they are. We run our services in every major cloud provider, so they can have what they need, where they need it. But of course, different providers offer different services — and different challenges.
When we first landed on AWS in 2022 and began using Amazon Elastic Kubernetes Service (Amazon EKS), we went with Cluster Autoscaler (CA) as our autoscaling tool of choice. It’s open; it’s simple; it’s been battle tested by countless other people before us. However, it wasn’t long before we realized it was not the right tool for us.
In this blog, we’ll dig into why CA wasn’t the long-term answer, the alternatives we considered, and why we ultimately went with Karpenter. We’ll also look at some of the associated trade offs and lessons learned, as well as why Karpenter has helped us reduce costs and complexity, which in turn helps us provide better service to our users who are on AWS.
Disclaimer: This article uses the Karpenter v1alpha5 API spec. The project has recently introduced some breaking changes in the v1beta1 specification, alongside renaming core components. For example, Provisioners have been renamed to NodePools. We have decided to keep the v1alpha5 naming for consistency, as that is the one we are running and have experience with.
The challenges we were facing with Cluster Autoscaler
As we began to use CA, we quickly began running into a number of obstacles that limited the efficiency and flexibility of our EKS clusters. Before we get into how we addressed many of these problems by switching to Karpenter, let’s first look at what led us there.
Capacity requested vs. obtained
CA works by scaling Kubernetes node groups up and down. It watches for pending pods that cannot fit onto the existing nodes, and it will provision new nodes for them to land on, according to the node groups definition and their underlying Auto Scaling Groups.

AWS allows you to define a diverse range of instance types for your node groups. However, if you list multiple types for your group, CA will only run calculations for one of them in order to determine how many nodes it needs to scale up. It will then request that many instances to AWS, but you have no control over which instance types you’re actually getting. You may end up with capacity that does not match your actual needs, leading to more readjusting.
To work around this, CA recommends that you stick to similarly sized instances when you define your node groups. This is a simple enough solution. To pick a general example, instead of having a group of both m5.2xlarge and m5.4xlarge instances, you define two separate node groups, one of each instance size, and let CA do its job. It will then choose either one or the other and run the numbers for that particular instance size.
The downside to this approach is that CA has limited options for choosing optimal instances. You end up with a random decision between the two node groups, which can lead to underutilized nodes and, subsequently, to churn. Let’s say you needed enough capacity to fill three m5.2xlarge instances. If CA chooses the m5.2xlarge group, it’ll calculate that it needs three more instances and request them. But if it chooses the m5.4xlarge group, it’ll request two instances, and at least one of those instances will end up being underutilized. Depending on the threshold you set for it, it can then mark one of those nodes for deletion, as it is below its utilization threshold.
Increased infrastructure complexity and stiffness
As a consequence of the previous point, we ended up with more and more specialized node group definitions in order to answer our workloads’ demands. This, in turn, made it more difficult for our developers to run experiments on how their workloads performed in different instance types, as every experiment meant creating a new node group and decommissioning the previous one.
No soft constraints, no fallbacks
This one hurt us when we tried to use AWS’s Spot Instances. We wanted to take advantage of this highly-volatile, dirt-cheap compute option without letting it overcome our regular on-demand scale up plans. However, CA doesn’t consider “soft” constraints like preferredDuringSchedulingIgnoredDuringExecution when it selects node groups. If a workload prefers a spot node and one has space for it, the Kubernetes scheduler will try to land it there. But if there’s no space, CA will not take this into consideration when deciding which group to scale up. In our case, this meant the only way we could ever get spot nodes was if the workloads used a hard requirement instead, setting the requiredDuringSchedulingIgnoredDuringExecution property.
We then faced a very serious scarcity problem — a notorious challenge when working with required spot nodes. That’s because CA only ever requested scale ups to AWS, but it didn’t check for availability. If Spot Instances weren’t available, we had no way to tell CA to fall back to On-Demand Instances, and we ended up stuck in a few loops. This wouldn’t have been an issue if workloads just preferred Spot Instances, but we could get stuck in a scarcity scenario if the workloads required them. This problem, which a reliable platform should be able to address transparently, then seeped into our developers’ world, complicating their setups if they wanted to allow the use of Spot Instances.
Not so great bin-packing and reliability issues
This was the issue that put the nail in the coffin for us. We were keeping track of our clusters’ combined memory and CPU utilization ratio, and our AWS clusters were falling way behind the performance of the clusters we were running on other cloud providers. This meant we were burning cash, with some of them reaching north of 40% idle ratios!

On top of that, we hit a problem with Amazon EKS’s max number of pods. For workloads that had to be co-located and didn’t require lots of resources, we were barely using half the capacity of our nodes when they would hit the maximum number of allowed pods. At one point, CA was actively scaling down a group (because it considered the nodes underutilized), while pods were stuck as unschedulable (because there were not enough IPs for them to land anywhere else).
So we set out to find a solution.
Evaluating our autoscaling options
We looked into CA’s configuration options. Maybe we weren’t using the tool as it was meant to be used? However, the knobs and levers that are available weren’t enough to tackle the problems we were having. It seemed it was just not the right tool for our needs.
Were our needs so different from everyone else’s then? Maybe we should be running our own custom scheduler? We put some time into this, and soon realized the magnitude of the undertaking would be way too expensive, and it certainly wouldn’t help us standardize anything. This was not an option we wanted to take if better alternatives were available.
Karpenter: Can it be as good as it sounds?
We’d heard about Karpenter. Even though it had been mainly produced by AWS, it was open source, which aligned with one of our core values (OOS is in our DNA). It also had a strong community backing it, and it had even petitioned to become a CNCF project.
Karpenter is a huge paradigm shift. It brings up nodes just in time, using what it calls provisioners and node templates. It leaves behind the idea of predefined node groups, which we wrote as Terraform code, and it uses Kubernetes constructs instead. The idea is that Karpenter’s provisioners act as a set of requirements that a node conforms to. Unschedulable workloads are then matched with those provisioners, which select the optimal nodes for them to run on and spin them up.

This intelligent capacity management with a Kuberentes-native resource would mean not just more flexibility, but also better ease of use for our developers. They could adapt those resources to their needs in a form that was familiar to them already, making experimentation easier. On top of that, the docs said it would make our fleet run on exactly the resources we needed — no more, no less, which would hopefully bring our idle ratios back under control.
It also advertised native fallback from Spot to On-Demand instances via capacity type selection, as well as the possibility to add weights to the provisioners so we could have even finer control over fallback options of our own. Plus, Karpenter talks to the AWS’s EC2 API directly, which means it can react to scarcity by immediately falling back to the other defined options.
It seemed to tick all the boxes we needed, but it was also a deep departure from our previous setup. So we got to work seeing if it would actually meet our needs.
Migrating to Karpeneter without disrupting users
We implemented Karpenter at Grafana Labs as a deployment configured in Jsonnet, and its supporting infrastructure (e.g., IAM roles, SQS queues) was defined in Terraform. The Karpenter controller should not run in a Karpenter-provisioned node, as it would risk descheduling itself and not be able to come back up. In our case, we ran a dedicated node group for static critical cluster components only, but it could also run in AWS Fargate if we really wanted to get rid of all the node groups.
After we validated that we could make Karpenter work, we still had to figure out how to make the switch. As we said earlier, our setup was fairly complex. We needed a way to switch the autoscaling tool so it wouldn’t cause any disruptions to our users. We also couldn’t run both at the same time, as they’d conflict over the same responsibilities.
We needed to create a way for Karpenter to take over CA’s job. After some head scratching, we came up with a possible solution. The key was to do things in the right order.
Karpenter doesn’t do anything until it has provisioners. It only brings up nodes when a pod is marked as unschedulable by the Kubernetes scheduler and it can match that pod to one of its provisioners.This means you can deploy Karpenter, the controller itself, without provisioners, and it won’t interfere with CA. Then you just give it provisioners and node templates at the same time as you switch off CA, and it can take over. At that point it becomes just a matter of draining the old CA managed node groups and letting Karpenter do its job. Once all workloads have been moved to Karpenter provisioned nodes, you can get rid of all the old node groups for good.
Using this strategy, alongside some homegrown tools, we were able to migrate this core infrastructure component in production transparently, both to our developers and to our end users. Today, we run a single node group in all our AWS clusters for critical cluster components only, which we keep protected by taints, while Karpenter handles all the regular business workloads.
Cluster Autoscaler vs. Karpenter: the results
We had high expectations, but the results did not disappoint.
Idleness and total cost reduction
Idleness ratios fell by 50% on average. We had set a challenging goal for ourselves to go down to 15%, and while not all of our clusters got there, these were the results of the migration alone. We are yet to discover all the knobs we can tweak.

This alone would’ve meant a corresponding cost reduction; better utilization means not paying for as much idle capacity. But on top of that, one of Karpenter’s strongest selling points is consolidation.
Karpenter constantly calculates the overall needs of the cluster’s workloads as well as the infrastructure currently running them. If it determines that a cheaper configuration of nodes is available and fits the constraints of its provisioners as well as the needs of the workloads, it will gradually deprovision and replace nodes until the fleet costs are optimized.
The more options you give Karpenter to work with (instance types, families, sizes, etc.), the more it’ll be able to optimize your costs, based on AWS’s availability at any given time. And because it does the heavy lifting for you, you don’t really need to put as much effort into deciding which instance types are best for your cluster; it can do that on its own. In our case, it ended up favoring one specific instance type we had overlooked for months.
Unlike CA, Karpenter can run complex calculations and request a mix of instance types that will respond to your exact needs, because it’s constantly talking to the EC2 API, provisions nodes just in time, and isn’t limited by a tightly defined pool.
Note: Mind that consolidation only applies to On-Demand Instances. Karpenter follows a slightly different approach for Spot Instances.
Our biggest cluster workload utilization and distribution went from this:
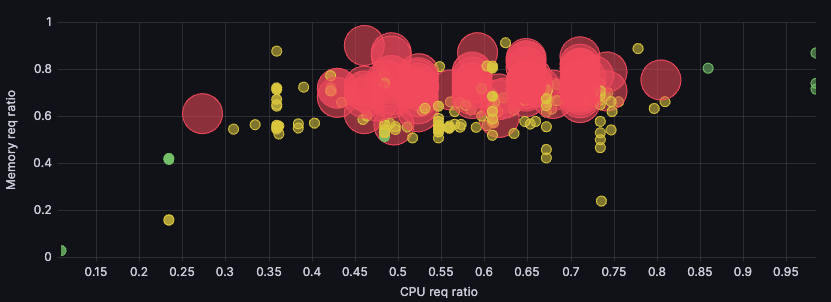
To this:
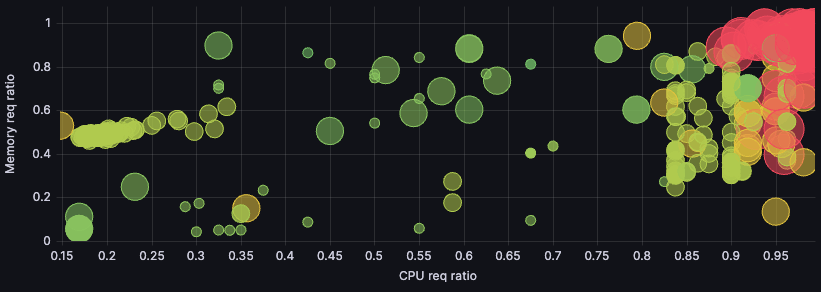
This visualization shows utilization ratio for memory and for CPU. We strive to get both as close to 1 as possible (top right corner), which would mean complete utilization. But because CPU is our main cost driver, we use the points’ sizes to visualize the number of cores of those nodes at a glance. The points’ colors represent pricing — green for cheaper nodes, up to red for more expensive ones.
CPU being the main cost driver, as we said, means size somewhat correlates with price: The bigger the point, the more expensive it’ll be in most cases. That means we care most about the biggest, reddest points, and we care more about getting them to the right-hand side (maximizing CPU utilization) than getting them to the top of the graph (maximizing memory utilization).
Here, our most relevant nodes moved from the top center to the top right, where they clustered even more. Success!
Improved reliability
If a change saves you money, more often than not, you’ll pay that back taking a hit in reliability. However, we found the exact opposite happened in this case.
Karpenter natively supports specifying the capacity type, and it prioritizes Spot Instances over On-Demand Instances. In case there are no Spot Instances available, it provides the fallback to On-Demand out of the box.
Plus, it addresses the bane of our existence with CA: Karpenter takes the max number of pods into account when deciding whether or not it can delete a node, checking that there will be not just resources but IPs available for the evicted pods.
It solved the two most problematic reliability issues we’d been facing by just swapping one tool for another.
What about Savings Plans?
We hit a bump here that we hadn’t taken into account. Karpenter works best the more options you give it. But in AWS, only Compute Savings Plans will give you that kind of flexibility. We were locked into some pre-existing EC2 Instance Savings Plans that we needed to fulfill first, before it made financial sense to jump into the full flexibility wagon.
Karpenter turned out to have exactly what we needed. We worked around this by using two provisioners’ features: weight and limits. We calculated how much CPU we needed to fulfill our EC2 Savings Plan commitment, created a provisioner with a high weight, and limited it to that amount of CPU.
Once that provisioner is handling as much CPU as its limit will allow, Karpenter moves onto the second one, with a lower weight, that fully harnesses all the flexibility AWS has to offer. And we seal the deal with some Compute Savings Plans that come into play at that point. This allowed us to meet our contractual obligations while still harnessing Karpenter’s optimization potential.
Better developer experience
Since provisioners are Kubernetes objects, and Karpenter can deal with having an extreme variety of instance types for any of them, developers can now run experiments with a lot less toil. All they have to do is set up a provisioner that will match their workloads and play around with it.
To see changes to a provisioner propagate, there are a number of alternatives. Because our clusters are fairly dynamic, the regular consolidation cycle is often enough for us to see the changes take effect if we’re touching on an existing provisioner. Old nodes get deprovisioned, new ones come up with the new setup. But for early experimentation, what usually happens is developers play around just draining the old nodes or bringing up more replicas that will spin up newly configured nodes.
Fair warning, though: deleting a provisioner will delete all nodes it was managing. So, let your developers know about the risks, and they can play around all they want.
Disaster recovery
Karpenter’s just-in-time node provisioning makes it ideal for disaster recovery scenarios. We depend on one single static node pool, the one running Karpenter itself, along with all the components that are critical for the cluster to be able to run at all. In case of disaster, that means the amount of components we could potentially need to intervene to recreate is minimal. Compared with the previous node-group-based approach of our AWS clusters, this makes us faster, requires far less human intervention, and is less error prone, in case we need to recreate an entire cluster in a hurry.
Simplified infrastructure: simplified Kubernetes upgrades
Yet another straightforward result from Karpenter’s design. Changes to the provisioners, as well as changes to the control plane, propagate naturally through regular cluster processes. That means that once the control plane is upgraded, all the new nodes Karpenter provisions will come up with the new Kubernetes version. No need to create new node groups and taint old ones. In theory, all you have to do is let it run its course.
To keep a finer degree of control over it, we use our own internal tooling to trigger a controlled drain of all old nodes, but that’s entirely optional. We also make sure that no node is left behind for too long by telling Karpenter to set a 30 day TTL on them. After that time, Karpenter marks those nodes as expired and gracefully deprovisions them. That way, we make sure the underlying infrastructure never drifts too far from the coded one.
Trade-offs
As excited as we are with these results, there are tradeoffs to every decision. In our case, adopting Karpenter meant giving up on a vision of a unified scaling solution across all the cloud providers that we use. Even though Karpenter is an open source project, at this point it only supports AWS, and only time will tell if other providers will join in the effort. But for now, we have a distinct, unique scaling solution for just one of our providers.
While it has already proven to be a very robust solution, Karpenter is still under very active development; it has a way to go to become a mature project. Consolidation is one of its most important features, yet it’s not available for Spot Instances, and there’s no easy solution in sight for it. It’s a difficult design problem that the project has not tackled yet.
Finally, we’re eager to see some features further down the line, such as improved deprovisioning controls, to provide a finer degree of control over Karpenter’s deprovisioning decisions. These features are on the roadmap, and we look forward to the v1 release!
Wrapping up
The switch from Cluster Autoscaler to Karpenter was a massive success for us. Karpenter’s setup was slightly more complex than CA’s, but the results are overwhelmingly positive, and it ended up actually simplifying our infrastructure. For bigger, more complex EKS clusters, it seems to be the tool for the job.
As a company, Grafana Labs has always been cost conscious, and as such, idle ratio is one metric that we always keep in mind so we make the most out of the resources we have and provide the best service out there. This change dramatically lowered our idleness within our AWS clusters, making us a lot more efficient.
The agility to pick available AWS instances and fall back from one instance type to another made us not only cost efficient, but also improved the reliability of our services. As an added bonus, it improved our position in the face of a potential disaster recovery scenario, so if it ever happened, we could react and return to normal operations a lot faster.
The migration itself was fairly straightforward too, and we didn’t hit any major hiccups. It can be done without downtime and paced as fast or slow as you need.
Once we completed the migration, it was all about letting the information bubble up and getting developers comfortable with the new paradigm. In our case, initial resistance to change was quickly overcome by ease of use and experimentation.
We’re excited to see this tool evolve and to use more features as it grows!


