

Announcing Sift: automated system checks for faster incident response times in Grafana Cloud
When faced with an incident, there are two areas that demand your immediate attention: the incident investigation, and the cross-functional coordination needed to resolve the issue.
Grafana Incident helps with the collaboration by providing a central hub for communication across teams that seamlessly integrates with the tools you are already using, such as Slack or Microsoft Teams. But how can you best use your telemetry data to debug your application and bring your systems back online?
At Grafana Labs, we understand the challenges of on-call duty because we’ve experienced those adrenaline-pumping moments. We also love finding smarter solutions to make an engineer’s life easier, especially when dealing with incident response management. This is why we are excited to introduce Sift, a feature currently in public preview in Grafana Cloud that performs a set of automated system checks and surfaces potential issues in your Kubernetes environment. With the information Sift provides, you can get to the root of the problem and resolve it faster and more efficiently.
There’s supposed to be a video here, but for some reason there isn’t. Either we entered the id wrong (oops!), or Vimeo is down. If it’s the latter, we’d expect they’ll be back up and running soon. In the meantime, check out our blog!
Introducing Sift: your trusted IRM assistant
Sift is a diagnostic feature in the Grafana Incident & Response Management (IRM) suite in Grafana Cloud, and it’s powered by Grafana Machine Learning.
Sift is also deeply integrated into the Grafana LGTM Stack (Loki for logs, Grafana for visualization, Tempo for traces, and Mimir for metrics). It knows where to find your metrics, logs, and traces, and which patterns to look for in the most common types of incidents.
With that information, Sift automates some of the routine parts of incident investigation, such as spotting error log increases or identifying recent service deployments that might be related to your issue. It can also show if your servers are overloaded or low on memory. It’s like having an extra pair of eyes, filling in context as you focus on solving the incident.
How Sift works to identify the root cause of an incident
Sift conducts investigations through the following tailored checks, which provide a comprehensive view of your Kubernetes infrastructure.
- Error pattern logs. This check searches through your error logs, deciphering patterns that are often at the heart of an incident. By identifying groups of similar log lines and highlighting those with a sudden spike in activity, Sift directs you toward the areas that require immediate attention.
- Kube crashes. Kubernetes containers sometimes terminate unexpectedly. Sift takes a closer look at Kubernetes metrics to detect recent container crashes and gives you insights into the root causes of these crashes, whether they are application errors or out-of-memory terminations.
- Noisy neighbors. Sift uses node metrics to identify overloaded hosts that could lead to high latency and performance issues. It also analyzes the pods on these hosts to identify the ones using more resources than they should.
- Recent deployments. Changes in Kubernetes workloads can sometimes trigger incidents. Sift proactively keeps tabs on recently updated workloads, highlighting services that have been modified, updated, or tweaked in any way.
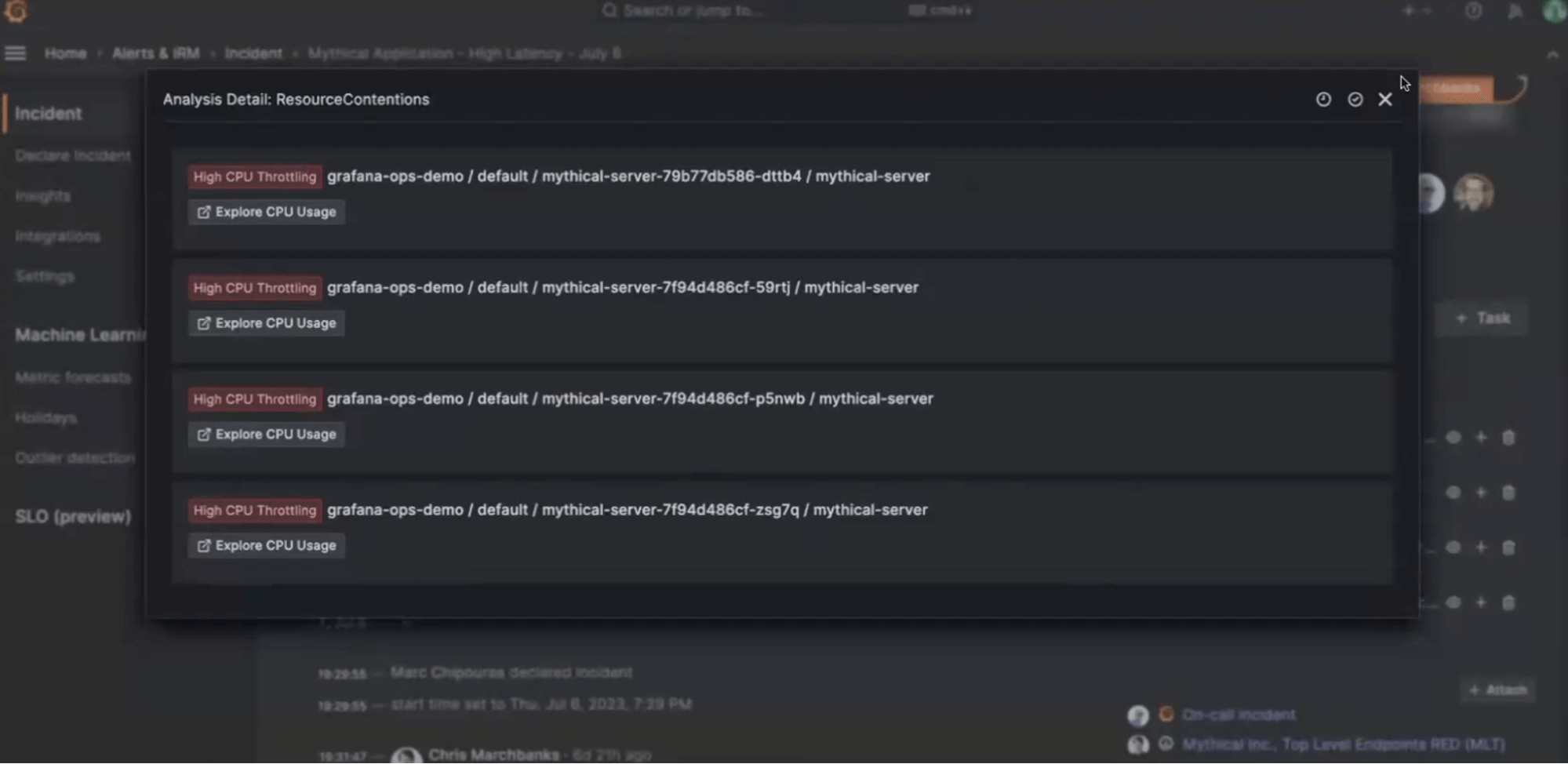
- Resource contention. CPU throttling can cause hard-to-identify slowdowns in application performance. Sift focuses on containers hitting significant CPU throttling due to limits. Plus, if you’re having network problems, Sift keeps an eye on packet drops.
- Slow requests. Sift queries distributed tracing data present in Grafana Cloud Traces, to identify requests that take longer than a defined threshold (default: three seconds). This check helps you spot bottlenecks in your system’s performance, keeping you informed about any potential inefficiencies.
We have been running Sift in Grafana Labs’ internal clusters for a year now, and it has surfaced valuable insights during incidents. One recent incident involved a bug in CertMagic in our production systems, where our gateways crashed due to failed certificate renewals for custom domains. Sift discovered an increase in SSL error logs and surfaced this automated check as a suggestion for the teams investigating the incident.

Another example was when Sift helped our Grafana-as-a-Service team. In Grafana Cloud, Grafana upgrades were causing contention as hundreds of instances launched simultaneously. Sift’s noisy neighbors check helped quickly identify this issue and the team was able to optimize the launch process, as well as schedule instances more intelligently to avoid contention going forward.
How to use Sift to assist your investigation
Sift is automatically triggered in certain cases when using Grafana IRM. In other words, when you declare an incident from a Grafana alert or Grafana OnCall alert group and relevant Kubernetes data is available, Sift will run automatically. It’s also triggered automatically when adding a dashboard to a Grafana Incident timeline and relevant Kubernetes data is available.
You can also manually run Sift by going to the Suggestions section in the right sidebar of the incident timeline, then click Start Sift investigation. Manually enter the cluster and namespace corresponding to the Kubernetes cluster and namespace of your services to start a Sift investigation specifically tailored to the incident.
Once Sift identifies any relevant results, it populates the sidebar under Suggestions with clickable links. Those links will take you to detailed information about the specific check. You can then add suggestions to your incident timeline or remove them if they’re deemed irrelevant.
What’s next for Sift in Grafana Incident?
Currently, Sift is only available in Grafana Cloud and its primary focus is on Kubernetes environments. But we plan to expand its capabilities to make Sift more versatile and accessible, including additional system checks and delivering new ways to use Sift outside of Grafana IRM workflows.
We invite you to try out Sift today. Integrate it into your incident response toolkit, and join us in the ongoing improvement of this valuable resource. We look forward to seeing how Sift can empower your incident-solving efforts.
For more information, check out our Sift documentation and you can also reach out to the team on the #grafana-incident channel in the Grafana Labs Community Slack.
If you’re not already using Grafana Cloud — the easiest way to get started with observability — sign up now for a free 14-day trial of Grafana Cloud Pro, with unlimited metrics, logs, traces, and users, long-term retention, and access to all Enterprise plugins.


