

Improving query performance in Grafana Mimir: Why we dropped mmap from the store-gateway
In recent months, we have been working on improving the performance of Grafana Mimir, the open source, horizontally scalable, highly available, multi-tenant TSDB for long-term storage of your metrics. In a previous blog post, Mimir engineers Dimitar Dimitrov and Marco Pracucci introduced the store-gateway — a dedicated service in Mimir that is responsible for fetching metrics data from the object storage in an optimized manner — and they walked through the updates we’ve done to minimize out-of-memory errors when it processes queries.
In this post, I’d like to dive deeper into the depths of the store-gateway, focusing on index headers, which are a vital component to how we keep queries performant, and a performance and stability issue we recently fixed caused by mmap. This optimization is based on work I completed alongside Nick Pillitteri, and we built upon an earlier investigation by Steve Simpson.
What is the index-header?
The index-header is a subset of the Prometheus TSDB block index that Mimir uses to efficiently respond to queries without downloading the entire block from object storage.
Mimir is based on Prometheus, and therefore makes use of the Prometheus TSDB format to store ingested time series. While Prometheus is designed to run on a single node with a locally attached disk, Mimir takes advantage of object stores like Amazon S3 or Google Cloud Storage (GCS) to provide high performance at a scale well beyond what a single machine can handle.
Given the different performance and cost characteristics of object storage, Mimir builds upon the foundation of the Prometheus storage format to provide high performance without blowing the bank on bills. One particular example of where Mimir differs from Prometheus is the use of index-headers for each block. (A block is the unit of storage for time series; many time series for a 2-, 6-, or 24-hour time window are compacted together and stored in a single block.)
The index-header contains only part of the index for each TSDB block — just enough information for a store-gateway to decide whether a block contains time series matching a query, and if so, which parts of the block need to be loaded to retrieve the relevant data. This allows the store-gateway to only retrieve a subset of a block when responding to a query. Blocks can be many gigabytes in size, but most queries only need kilobytes of data from a block.
(If you’re curious to learn more about the Prometheus TSDB, our colleague Ganesh Vernekar has written an excellent series about its inner workings and how it stores data on disk.)
What is mmap?
mmap is a syscall that makes a file to an application available as if it was ordinary memory. Think of it as a magical alternative to the traditional file I/O.
When reading a file with traditional file I/O, the application allocates some memory for the contents of the file, then instructs the operating system to read some or all of the file into that memory. If the application doesn’t want to read the entire file into memory at once, it can ask the operating system to only load a portion of the file, and then later instruct the operating system to load later portions when the application is done reading the first portion.
In contrast, with mmap, the application asks the operating system to map the file into memory, and the operating system returns a memory address from which the application can read the file. From the application’s perspective, it then just reads from that memory like any other memory.
Under the hood, the operating system manages loading and unloading the file’s contents into memory. Whenever the application attempts to read a segment of the file not currently loaded, a page fault occurs, the application thread is paused, the operating system loads the necessary part of the file into memory and then resumes execution of the thread. The operating system also manages unloading parts of the file that haven’t been read recently, allowing this memory to be used for other things.
This behavior means applications can use mmapped files almost like a cache, with the operating system managing how much of each file is available to read instantly based on usage patterns and other heuristics, such as system memory pressure. And this is exactly what Mimir used mmap for: store-gateways would load index-headers with mmap, and let the operating system take care of managing them.
Like oil and water: why mmap and Golang don’t mix
We run dozens of Mimir clusters as part of Grafana Cloud Metrics. Across these clusters, we were seeing instances where store-gateways became slow or unresponsive to query requests. This meant that our customers were sometimes experiencing slower queries and errors — not something we want when they are relying on our stack to monitor their own mission-critical systems.
There were a couple of other symptoms that seemed to correspond with this latency and error rate. In particular, around the time of these issues, we also saw an increase in index-header loading activity and instance health checks timing out. These health checks are very simple: Kubernetes makes an HTTP GET request to /ready on the store-gateway instance, and the store-gateway returns an HTTP 200 response. Once a store-gateway has finished starting up, responses should be near-instant, and yet they were taking more than a second.
In other words, it seemed that the entire store-gateway process was stalling during periods when there was more index-header loading activity.
We believed this was due to the use of mmap to load index-headers, and Steve Simpson was able to prove this by setting up a small test that loaded index-headers from a FUSE filesystem that introduced artificial delays to I/O operations.
Why would using mmap lead to stalling the entire process? If a goroutine makes an ordinary file I/O syscall, Golang’s scheduler will pause the goroutine while the operating system completes the syscall, and use the underlying operating system thread to run another goroutine. When the syscall completes, Golang’s scheduler will resume the original goroutine.
However, when a goroutine accesses mmapped memory that needs to be loaded from disk, a page fault occurs, and the underlying thread is blocked until the required data is loaded from disk. From the perspective of Golang’s scheduler, the goroutine is busy, and so the underlying thread serving that goroutine can’t be used to make progress on other goroutines while the operating system is loading data from disk. A Golang process uses a limited number of threads, so if multiple goroutines trigger page faults at the same time, they can consume all available threads and cause the process to appear to have stalled.
I find this visualization helpful to understand the difference between regular I/O and mmap in Golang:

The solution: bye, mmap
So, how did we resolve this? The answer was conceptually straightforward — replace the use of mmap with ordinary file I/O operations — but more complex to actually implement.
In addition to modifying some complex code that relied heavily on the magic of mmap, we also needed to go through multiple rounds of optimization to achieve similar levels of performance that we had with mmap, as we could no longer rely on the operating system to cache recently used index-headers in memory.
There were three optimizations that were particularly impactful:
- Buffered I/O. Each field of the index-header is quite small, so making individual read calls for each field was prohibitively slow. Using buffered I/O means that we buffer a longer segment of the file in memory, read the individual fields from that buffer, and refill the buffer after exhausting it, significantly reducing the number of read calls that are made.
- Pooling file handles for each index-header. When an index-header is first loaded, we load only a subset of the header into memory, as keeping the full header in memory for every block would require a large amount of memory. When queries later arrive that query the block, we use this pre-loaded subset to locate the appropriate segments of the header that need to be read, and then read them from disk. However, we found that the seemingly simple act of opening the file for reading was quite slow. Once we introduced a pool of file handles for each index-header, we no longer needed to perform an expensive open operation every time, and instead simply needed to seek to the appropriate position in the file and begin reading.
- No longer creating new string instances for every single label name. One part of the index-header, the posting offset table, contains every label name and value pair in the block along with a reference to a list of all series that have that name/value pair. This table is sorted by name, then by value, so all name/value pairs with the same name appear next to one after the other. In our original implementation, we simply read the names and values, instantiating a string for each pair. However, this meant we were creating potentially dozens of strings for the same name, increasing memory consumption. Once we modified our index-header reader to reuse the existing string for the name (thanks to this optimization performed by the Golang compiler), we saw substantially reduced memory usage and reduced CPU usage thanks to reduced garbage collection pressure from all the unnecessary strings.
The impact: no more health check timeouts
We’ve been running store-gateways without mmap for almost six months now, and this, in conjunction with the other improvements we’ve made lately, has significantly improved their perceived performance and stability.
I wrote earlier about the significant number of health check timeouts that we were seeing. After deploying this change, we’ve seen that health check timeouts largely disappeared. For example, we run three zones of store-gateways for each Grafana Cloud Metrics cluster, and this graph shows the rate of health check timeouts in each zone for one cluster before and after disabling the use of mmap:
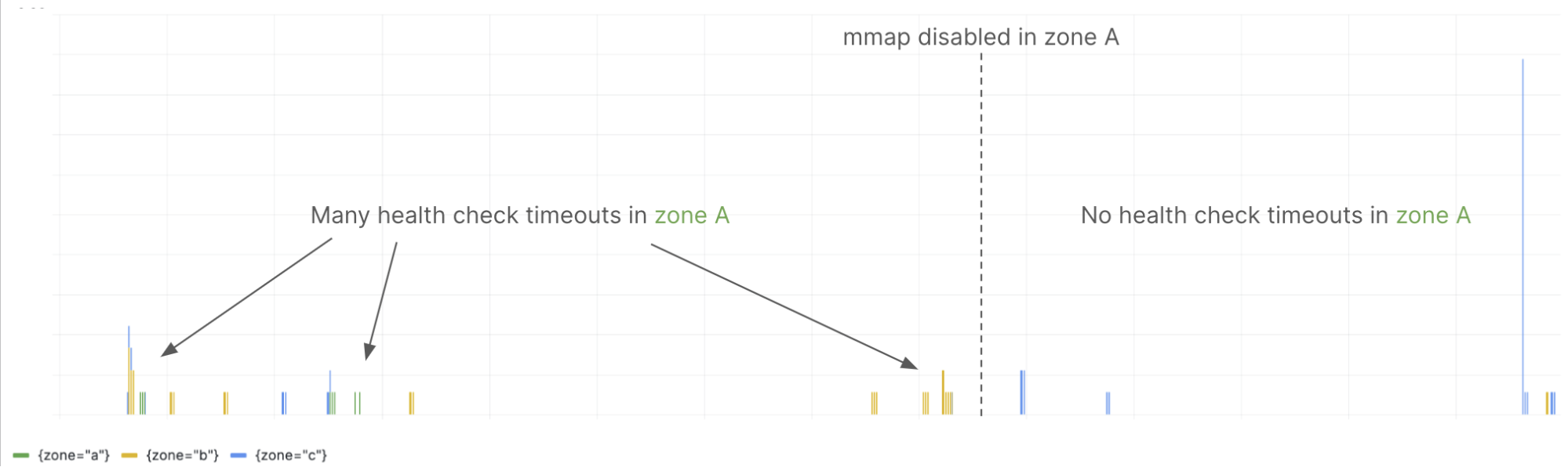
Even better, this change is now available in open source Mimir and enabled by default as of v2.7, so everyone benefits from this improvement. If you’re interested to see the code behind these changes, check out the PRs linked from this GitHub issue.
What’s next in Grafana Mimir
In addition to removing mmap from the store-gateway, we have also optimized the store-gateway to eliminate out-of-memory errors by progressively reading data from the object storage and sending it to the querier more efficiently via streaming.
In future articles, we’ll cover other improvements to Mimir, including how the querier can leverage streaming and an optimization introduced in the store-gateway to find the series matching the label matchers with reduced CPU and memory utilization.
To learn more about Grafana Mimir, check out our free webinar “Intro to Grafana Mimir: The open source time series database that scales to 1 billion metrics & beyond” and our Grafana Mimir documentation.
Grafana Cloud is the easiest way to get started with metrics, logs, traces, and dashboards. We recently added new features to our generous forever-free tier, including access to all Enterprise plugins for three users. Plus there are plans for every use case. Sign up for free now!


