

Breaking the memory barrier: How Grafana Mimir's store-gateway overcame out-of-memory errors
Grafana Mimir is an open source distributed time series database. Publicly launched in March 2022, Mimir has been designed for storing and querying metrics at any scale. Highly available, highly performant, and cost-effective, Mimir is the underlying system powering Grafana Cloud Metrics, and it’s used by a growing open source community that includes individual users, small start-up companies, and large enterprises like OVHcloud.
Historically, one of the biggest challenges in Mimir was the potentially unbounded memory utilization at query time. When a high cardinality or long-time range query was received, Mimir was loading all the metrics data, matching the selectors and time range of the query upfront and then processing it through the PromQL engine.
Several techniques have been introduced in Mimir to overcome it. A query can be split into multiple partial queries both by time and series shard, and then each query can be executed concurrently across multiple machines, effectively reducing the CPU and memory utilization of a single partial query and speeding up its execution. Results from partial queries are then aggregated together before sending back the response to the client. (You can learn more about how query sharding works, by reading the “How we improved Grafana Mimir query performance by up to 10x” blog post.)
However, for very complex queries processing tens or hundreds of GBs, even a single partial query may use a lot of memory, eventually leading to an out-of-memory error. For this reason, several months ago we started a complex project to tackle this issue and improve Mimir so that it can run any query with bounded memory utilization.
Though the work is still ongoing, several milestones have been reached, and this blog post is the beginning of a series to show what we changed in Mimir and the key results we achieved for memory utilization.
How a metrics query works in Grafana Mimir
Before showing the improvements we’ve done in Mimir, let’s take a step back and understand how a metrics query is executed.
Mimir has a microservices-based architecture. The system is composed of multiple horizontally scalable microservices (called components) that can run separately and in parallel. These components can be deployed either individually using the microservices deployment mode or bulked together within the same process using the monolithic deployment mode. When deployed in microservices mode, each individual component can be horizontally scaled and its workload spread across multiple machines.

Queries coming into Grafana Mimir arrive at the query-frontend. The query-frontend is responsible for looking up the query results cache and sharding queries into multiple, smaller partial queries. These partial queries are put into an in-memory queue within the query-frontend (or the optional query-scheduler).
The actual query execution happens in the querier, where the PromQL engine runs. The queriers act as workers, pulling queries to execute from the query-frontend (or the optional query-scheduler) queue.
To execute a query, the querier needs to fetch the data for metrics matching the label matchers and time range of the query. The most recent metrics data is read from the ingesters’ memory and local disk, while older data is read from the object storage where it’s stored using the Prometheus TSDB block format.
What is the store-gateway?
Queriers don’t directly access the object storage. Instead they go through the store-gateway, a dedicated service in Grafana Mimir that is responsible for fetching the metrics data from the object storage in an optimized manner and that has several layers of caching in front of the actual reading from the storage.
After the querier fetches the metrics data from ingesters and store-gateways, it runs the PromQL engine to process the data and produces the result of the partial query. Finally, the partial queries results are merged together by the query-frontend, and the aggregated result is returned to the client.
In this blog post, we are going to focus on the store-gateway and the path it takes in completing user queries.
The unbounded memory utilization problem
The major problem of the store-gateway was that it could allocate an unbounded amount of memory to serve a single query, eventually leading to an out-of-memory error and causing the store-gateway to crash.
Note: The crashes are usually handled gracefully by the querier by retrying another store-gateway replica, so these failures don’t necessarily result in user-facing errors. But if enough of these failures occur, and there are no available store-gateway replicas to serve a given block, then the user query will fail.
To better understand the problem, and how we changed the store-gateway to run any query with bounded memory utilization, we’re going to use the most common Prometheus query as an example:
sum(rate(node_cpu_seconds_total{cluster=”test”}[1m]))
This query computes the CPU usage of all nodes in the test cluster in 1-minute intervals. The store-gateway is responsible for finding all the time series (also called “series” in the rest of the article) and samples that match the vector selector node_cpu_seconds_total{cluster=”test”} between the query’s start and end times and returning them to the querier.
There are three major steps the store-gateway follows to fetch the series data:
- Find the series IDs
The store-gateway looks for all series IDs matching the metric namenode_cpu_seconds_total, then looks for all series IDs matching the label matchercluster=”node-1”, and finally intersects the two sets to get the list of series IDs matching the query vector selector. - Fetch series labels and chunks references
For each series ID found in the previous step, the store-gateway fetches the series labels to convert the series from a numeric ID to the actual set of unique labels, and fetches the references to the chunks containing the samples within the query time range. Chunks are sequences of compressed samples (timestamp-value pairs) stored in the Prometheus TSDB block format. - Fetch the actual chunks data
Finally, for each chunk reference it fetches the actual chunks data.
Note: The workflow described above looks very resource-intensive in terms of number of operations issued to the object storage, but the store-gateway uses several techniques to optimize its execution and so reduces the object storage API requests to the minimum. For example, when fetching chunks, multiple chunks that are close together in the same TSDB segment file are fetched in a single operation. There’s also a caching layer both in front of the index and chunks lookup.
Until recently, the store-gateway performed the three steps to completion before proceeding to sending the series data back to the querier. In practice, this meant that the store-gateway computed each step and kept the result in memory either as an input to the next step (in the case of series IDs and chunk references) or as the result to return to the querier (in the case of series labels and chunks).
The following diagram shows how the store-gateway was working before our recent changes, with a focus on when the actual memory was released:
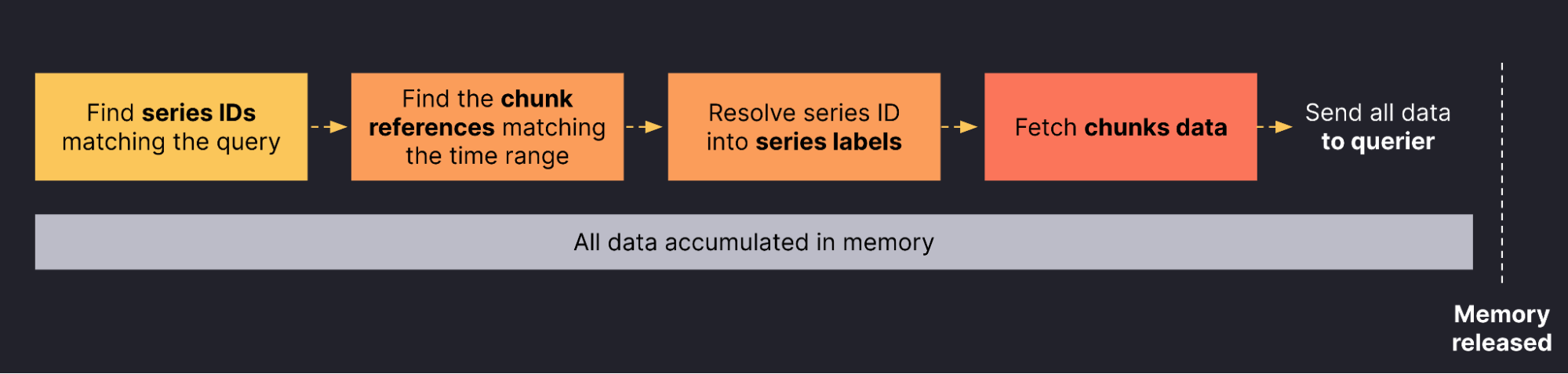
While keeping the labels and chunks of a few thousand series for a single query in memory is not a problem, the shortcomings of this model show when a single store-gateway replica has inflight requests fetching hundreds of thousands or even millions of series.
In an attempt to curb this problem, the store-gateway was protected by a concurrency limit that controlled the number of requests processed at the same time. However, even a small number of concurrent requests can drive massive memory usage. When a few big requests landed in the same store-gateway replica at the same time, it was prone to encounter out-of-memory errors and crash.
In addition to the concurrency limit, over time we’ve done several micro-optimizations that have reduced the memory footprint per series within a single request. But in the end, the memory required was still a function of the number of series that the query touches.
With a growing number of customers and a continuously growing scale, it became clear to us that we had to tackle this problem from the root and re-think how the data is fetched in the store-gateway. In other words, it was the right time to decouple the memory utilization peaks from the actual size of the query and get the memory utilization bounded, regardless which query the store-gateway is fetching data for.
Batching and streaming to the rescue
From a utilization perspective, where does most of the allocated memory come from? As seen above, there are few main data structures involved: series IDs, series labels, chunk references, and the actual chunks data.
A series ID is an 8-byte integer. For example, an array of one million series IDs can be stored in 8 MBs. Usually the list of series IDs does not have a significant memory footprint. (Although that turned out to not always be the case, and it led to another optimization we’ll cover in an upcoming blog post.) On the contrary, series labels, chunk references, and chunks data have the biggest memory footprint in the store-gateway.
So, can we limit the chunks and series labels that the store-gateway keeps in memory for any given request? Yes! We can batch the work and progressively stream the data to the querier. And that’s what we did: Instead of loading all labels, chunk references, and chunks upfront, the store-gateway now loads them in small batches and progressively sends them to the querier.
The following diagram shows how the streaming store-gateway works:
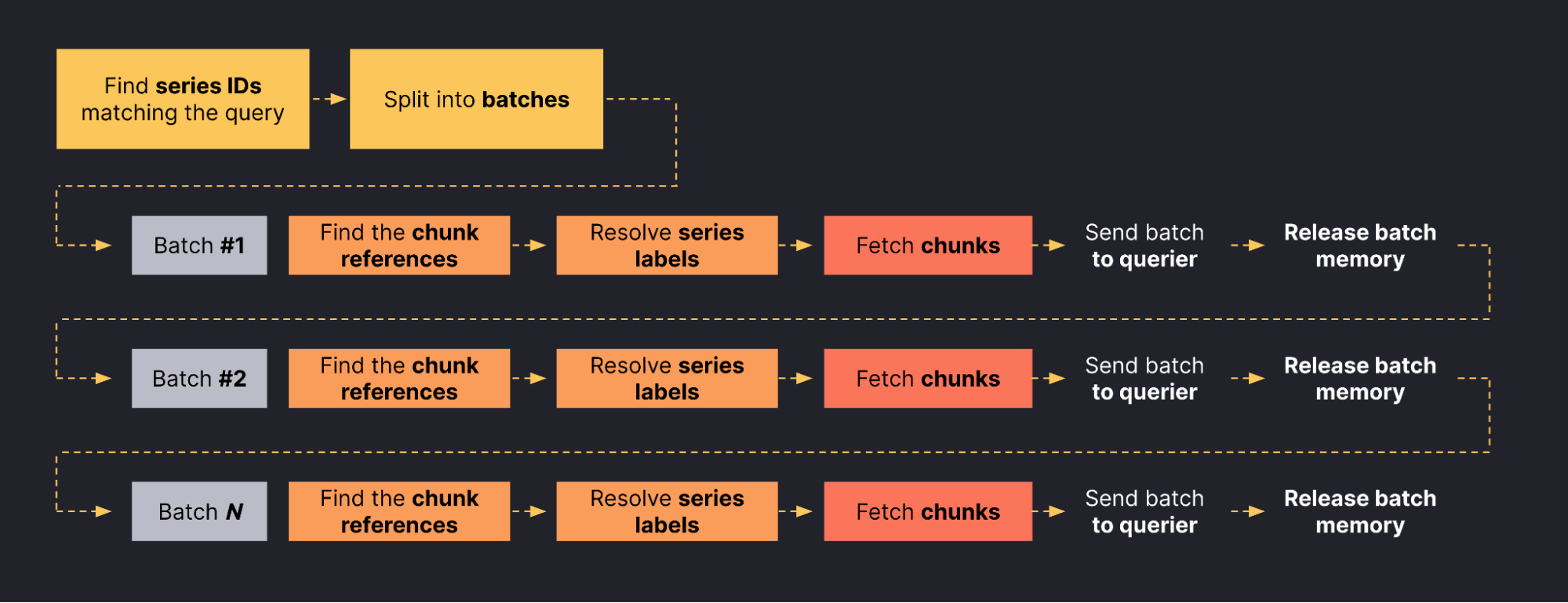
Batching the workload and streaming the data to the querier allows the store-gateway to decouple the memory utilization from the actual amount of data fetched for the request. For example, a store-gateway serving a request that needs to fetch 100k series will fetch them in 20 batches of 5k each. After loading a batch, the store-gateway sends the loaded batch back to the querier and processes the next batch, recycling the memory used by the previous one.
At Grafana Labs, we rolled out this change to production a few months ago, and we’ve seen a significant decrease in the rate of out-of-memory errors in store-gateways since then.
In order to test the performance of the streaming store-gateway, we deployed it alongside its non-streaming implementation and compared the rate of out-of-memory errors between the two while serving the same exact requests.
In the following graph, on the left you see the rate of out-of-memory errors in store-gateways that had been deployed with streaming, and on the right you see the rate of such errors in store-gateways using the old, non-streaming implementation. The streaming store-gateway reduced out-of-memory errors by about 90%.

Though the streaming store-gateway sounds like an easy concept, we had to introduce many changes under the hood. In the end, we ended up with a practically brand-new implementation. We also introduced several micro-optimizations to reduce memory copying and indirection in the data structures. We also had to decouple loading different data types in order to be able to reuse them for different batches within a request.
Okay, but what about the latency?
The streaming store-gateway processes the request in batches. Given that the store-gateway waits until a batch is sent to the querier before loading the next one, you may think the request latency increases. We thought the same when designing it, but after testing it we realized it doesn’t.
Why? Because we introduced preloading. In practice, while the store-gateway is sending one batch to the querier, it starts loading the next one, as shown in the following diagram.
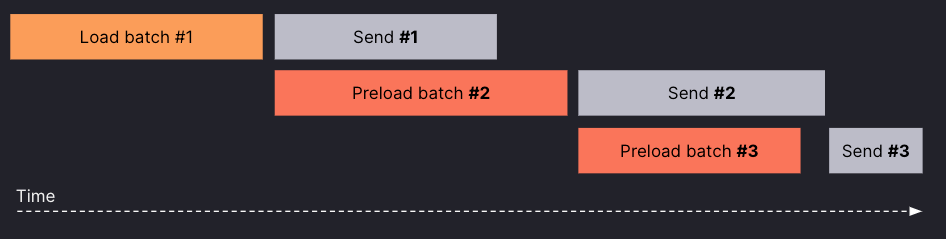
After an in-depth study of the distribution of time spent for a request, we discovered that a significant amount of time was spent in preparing and sending the response back to the querier. Depending on the size of the request, preloading reduced the latency of the request by as much as 60%.
The following charts show the average and 99th percentile response time (in milliseconds) of two store-gateway deployments serving the same exact requests in production:
 of two store-gateway deployments serving the same exact requests in production.*")
 of two store-gateway deployments serving the same exact requests in production.*")
No more store-gateway out-of-memory errors … forever?
Even if the rate of out-of-memory errors has been reduced drastically, the store-gateway could still go out-of-memory. Why? There are three main reasons:
- High number of inflight requests
With the streaming store-gateway, the memory utilization is bounded for a single request. However, a high number of inflight requests may add up to the total memory utilized by the store-gateway and eventually lead to an out-of-memory error. For this reason, fine-tuning the concurrency limit we mentioned previously is still important to keep the total memory utilization under control. - A huge list of series IDs
As mentioned above, the streaming store-gateway still needs to precompute the entire list of series IDs matching the label matchers. To do it, the store-gateway needs to find the series IDs matching each label matcher and then intersect them. Despite a series ID being just an 8-byte integer, if the query vector selector contains several matchers, each matching a large number of series, then the memory utilization could still spike significantly. For example, 10 label matchers, each matching 100M series, need to keep in memory 10 x 100M x 8 bytes = 8GB approximately.
This issue has been the topic of another optimization we introduced to improve how we select series IDs and eventually defer the evaluation of some label matchers to a later stage. We’ll cover this topic in-depth in an upcoming blog post. - Label names and values API
The store-gateway is not only responsible for fetching series data. The Prometheus API includes endpoints to list the possible label names and label values given some label selectors. Commonly these endpoints power functions such as template variables in Grafana dashboards. In Grafana Mimir, the store-gateway is responsible for serving these APIs for blocks in the object storage.
Computing the list of label names is effectively equivalent to fetching the series labels for the matchers and then combing through them to find the unique label names in the result. The steps are the same as for fetching series data, but there is no need to fetch the chunks data.
After rolling out the streaming store-gateway for the instant and range queries, we applied the same concept to the API used to retrieve label names and values. Despite conceptually looking the same, we actually found some inefficiencies when doing it for the label names and values API, and this led to further optimizations we’ll cover in an upcoming blog post.
What’s next in Grafana Mimir
In this blog post, we introduced the problem and explained the improvements we’ve done in the Mimir store-gateway to guarantee that the metrics data of a single query are never fully loaded in memory. Instead, data is progressively read from the object storage, processed, and sent to the querier more efficiently via streaming.
In future articles, we’ll cover other improvements, including how the querier can leverage streaming, why we removed any memory mapping usage from the store-gateway, and an optimization technique introduced in the store-gateway to find the series matching the label matchers and thus reducing the CPU and memory utilization when looking up the Prometheus TSDB index.
To learn more about Grafana Mimir, check out our free webinar “Intro to Grafana Mimir: The open source time series database that scales to 1 billion metrics & beyond” and our Grafana Mimir documentation.
Grafana Cloud is the easiest way to get started with metrics, logs, traces, and dashboards. We recently added new features to our generous forever-free tier, including access to all Enterprise plugins for three users. Plus there are plans for every use case. Sign up for free now!


