

Load testing Grafana k6: Peak, spike, and soak tests
Update: Grafana k6 load and performance testing is now available natively in Grafana Cloud. Existing k6 Cloud customers will not be impacted; they will be migrated to the new experience at a later date. Get started with Grafana Cloud k6 →
The original version of this blog appeared on the Grafana k6 blog.
With k6 Cloud, Grafana Labs is in the business of generating load — lots of load, distributed across a cluster of computers. So while our customers care about the systems they load, we care that our system can generate the load that they need and process the test metrics for them in an intuitive, explorable way.
Last fall, we ran a series of massive tests from our Grafana k6 infrastructure. This was essentially a reverse load test, because it flipped the focus of the test upside down. In normal load tests, testers really care only about the performance of the system under test (SUT) — that’s the point of the test. As long as the load generator generates the correct workflows and doesn’t use so much CPU that it skews results, its performance doesn’t matter much.
But because our focus is on generated load, we tested the full path of how we generate load: starting with load generation, through data ingestion, then DB storage, and finishing with data reads. To make this test significant, we also ran some tests that strayed pretty far from the typical best practices.
Continue reading to learn why we did this, what we did that was weird, what we discovered about our system, and how you can incorporate some of what we learned in your own load testing.
The normal: Test motivations
A few factors motivated our load test. We wanted to:
- Discover bottlenecks. The bottleneck would almost certainly be in how we process the vast volume of data.
- Provide reasonable expectations. Our team needs to be able to honestly answer customer questions about the limits of the load that we can generate.
- Test our new infrastructure. We had recently finished our migration to Kubernetes.
- Prepare for Black Friday. A classic case for load testing. Well, really, we needed to prepare for the preparation of Black Friday, since we knew our customers would soon be using k6 to make sure everything worked before November.
Certainly, the specific motivations of our load test weren’t that different from anyone else’s: We wanted to know the limits of our infrastructure and ensure that our system could meet customer expectations.
However, the design of our test was much more unusual.
The unusual: Test design
To probe the limits of our system, we needed to make a test that would be run only by an extremely unconventional client — a client that ignored many of the conventional load testing best practices.
Here are some of the most atypical parts of our design.
An invincible SUT
Load tests should discover realistic modes of failure. So, testers usually try to create a testing environment that is as close to production as possible (if they don’t just test prod directly).
But we didn’t want a realistic SUT. We wanted a SUT that couldn’t be knocked down. That way, we could ensure that when customers really do run huge tests, it won’t be our system that buckles first.
An unrealistically large load
Organizations new to load testing commonly want to start with huge load tests — like a million requests per second. Typically, we ask them, “Why? What will this tell you about your system in the real world?” In reality, it’s often much better to start with small, surgical portions.
But in our case, we wanted to indiscriminately blast the system, which is easy with an invincible SUT. We weren’t looking for nuance; we wanted a high volume of data.
An intentionally high amount of high-cardinality metrics
Typically, testers want to reduce the cardinality of the data because high cardinality makes it harder to filter and harder to store. An abundance of noisy metrics is a common problem, especially in parameterized tests. Indeed, k6 Cloud has a Performance Insight to process metrics and data, and our OSS docs highlight methods to reduce unique tags.
On the other hand, we don’t want our ability to process high-cardinality data to limit customers’ tests. First of all, if the test has useful metrics, it will naturally generate many series. Secondly, the SUT itself will increase the cardinality of the data as it starts to fail and responses and status codes start to become irregular. Finally, if a customer runs a soak test, the test might generate metrics for a long time.
Soak tests won’t necessarily increase cardinality, but they will increase the number of raw data points, making the data “denser” and harder to read from.
This is all to say that we need to know that k6 Cloud can handle high volumes of high cardinality. So we made a script that intentionally generated a ton of unique data in an inefficient way.
The tests
We wanted measurable assessments of the following questions:
- What benchmark numbers can we give customers?
- How does metric volume influence data-read times?
- What is the maximum number of records we can ingest?
In this context, records here can mean two things: the number of time series, and the number of HTTP records. An HTTP record would be one or more HTTP requests with the same label. Many parameters can affect how many time series and raw HTTP records a test has, including:
- URL
- HTTP status code
- HTTP method
- Load generator instance ID
- Load zone
- Tags, groups, and scenarios
If the number of any of these increases, it also increases the number of time series (and hence raw HTTP records) that we store in the database. This, in turn, effectively decreases the level of aggregation we can achieve.
Monitoring
Our test environment was the same one that you use to run k6 Cloud scripts. (You can read about the architecture here.) We felt comfortable running the test from the production environment because we were closely monitoring a number of system metrics in Grafana dashboards. With active monitoring, we knew that we could stop the test before performance degraded. Specifically, our monitoring included:
- The messaging queue
- Database metrics
- Ingestion worker metrics about duration and delay
- Infrastructure metrics, like pod number and health
- The read time for metric data in the browser
The invincible SUT
Our SUT was a cluster of Nginx instances, placed behind a load balancer and deployed to Amazon ECS via Terraform. The number of ECS tasks depended on the scale of the test run, so this was tweaked throughout the project.
Test scripts
These scripts weren’t too interesting. We created some groups with various minimum parameters (like minimum number of URLs), made some custom metrics, and used our batch method so that each VU sent concurrent requests (in addition to the concurrent iterations of each VU).
Again, we didn’t need to spend much time making a realistic script. The load profiles in our scenarios, however, were more interesting.
Test results
We ran three tests, each with a different goal. We did this because different goals have different workloads, as described in the docs about load test types.
Note: These values actually exceed the expectations that we set for our customers. Please don’t run uncontrolled tests of this magnitude — we’ll probably stop the test!
Peak load test
A stress test to see whether k6 could maintain an RPS that corresponded to peak load.
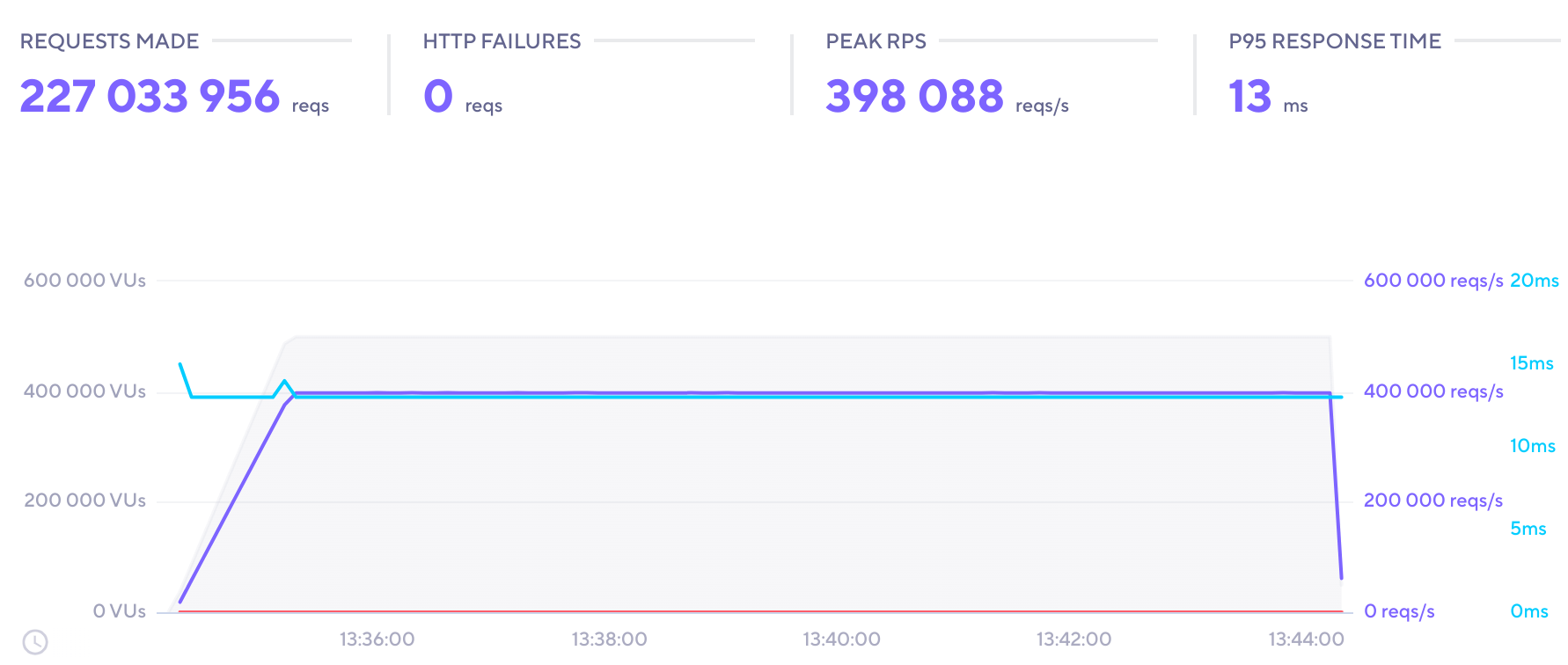
Load configuration:
- VUs: 500k
- Duration: 10m
- Unique URLs: 50
- Peak RPS: 400k
- Total reqs: 227M
- Load zones: 2
Output:
- Time-series: 23k
- Raw records: 1.3M
Observations: The system handled this decently, but only after auto-scaling kicked in. It also took a bit of time for the RabbitMQ queue to drain after this.
Spike test
A spike test to generate as high an RPS as possible in a short period of time.
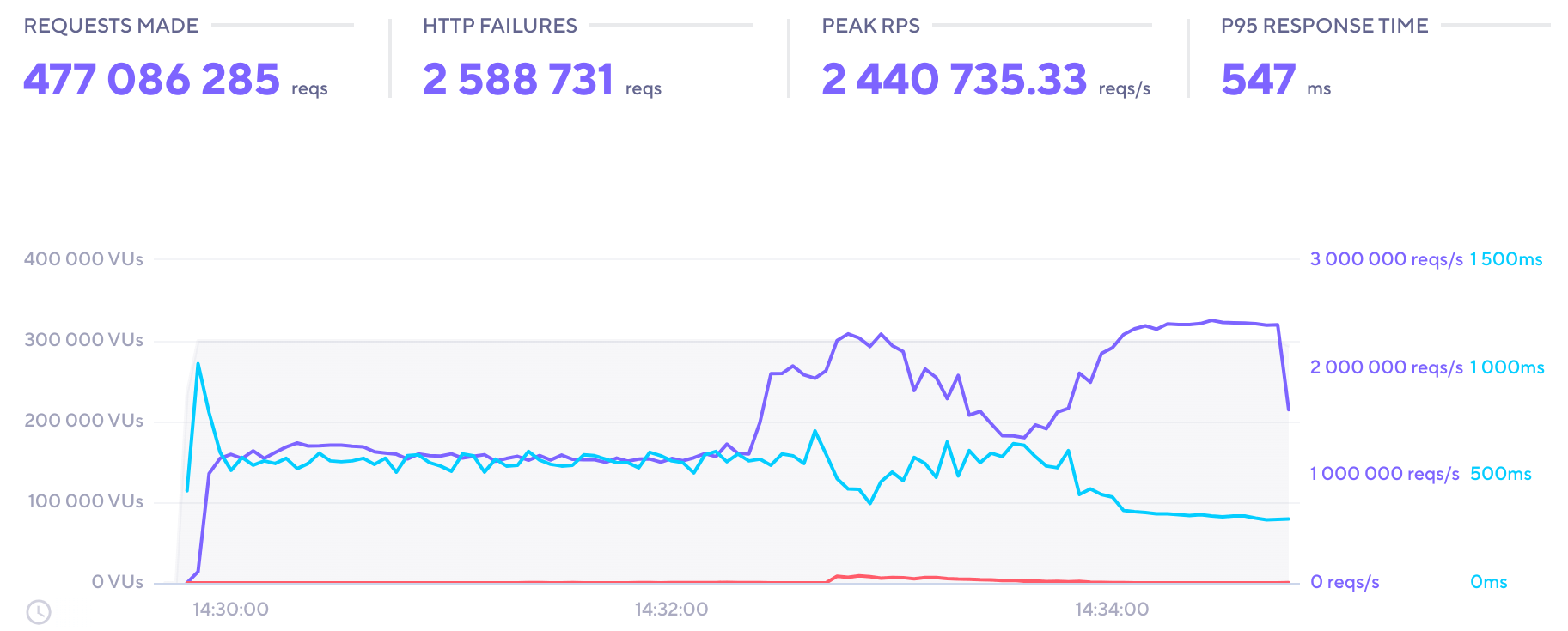
Load configuration:
- VUs: 300k
- Duration: 5m
- Unique URLs: 40
- Peak RPS: 2.4M
- Total reqs: 477M
- Load zones: 4
Output:
- Time-series: 13k
- Raw records: 210k
Observations: With the relatively low number of records, data-read time was lower than it was in the stress test. However, the CPU utilization of the load generators became very high.
Soak test
A soak test to discover how read time increases with test duration.

Load configuration:
- VUs: 100k
- Duration: 60m
- Unique URLs: 50
- Peak RPS: 80k
- Total reqs: 282M
- Load zones: 4
Output:
- Time-series: 5k
- Raw records: 1.7M
Observations: While the system could handle this, read time for metric data gradually increased over the course of the hour. Comparing this with the other tests, we concluded that read time increases more or less linearly with the number of records.
Analysis: Bottlenecks and planned improvements
Most importantly, these tests showed that k6 Cloud is indeed capable of meeting the current customer expectations. We also discovered a more-or-less linear relationship between records and read times, which gives us new data for how we can think of the limits of user-perceived performance on the frontend.
Besides these general observations, we also discovered some specific bottlenecks to improve.
Database locking
During data ingestion, we noted some locks in our database that could have been avoided with some code and query changes. For customer tests, this could occur in scenarios with extremely high numbers of time series.
Better aggregation and bucketing
If we can put our records in buckets more efficiently, it should greatly improve system limits and current read time, which will directly manifest in faster UX. This fix will involve some math.
The RabbitMQ-autoscaling wave pattern
Our autoscaler uses the number of queued RabbitMQ messages to determine whether it needs more ingest worker pods. When a long test run starts and the system catches up, the number of messages drops, then flatlines. After some time, the system then downscales the number of pods. However, since the same heavy test run continues to run, the number of messages rises again, and the cycle recurs in a “wavy” pattern.
We are investigating how to implement smarter autoscaling to keep the pod count at optimal numbers at all times.

Another plan is to make the test scripts a bit more robust, which will let us reproduce our scalability tests periodically to find regressions.
What you can take away from this
Unless you’re also building a load testing tool, you probably don’t want to do what we did. But our test served the essential purpose of a load test: We discovered major bottlenecks, we feel confident that we can set customer expectations honestly, and we have concrete plans for how to implement a more performant system.
And, despite the test’s weirdness, we can generalize some findings of the test into statements that might help any load tester. Here are the four key findings, in no particular order:
1. The bottleneck is often in storage
Databases scale vertically, but not horizontally. If you have auto-scaling set up, these non-horizontal components are usually where a bottleneck occurs.
Of course, horizontal-scaling components reach limits too, but the problem is often fixable with a second machine. This isn’t true of vertically scalable, stateful components.
2. Monitoring completes the load test picture
Load test metrics can simulate the experience of the user, but they won’t tell you about the system. Monitoring tells you about the health of the SUT, but it’s hard to translate the graphs into actual user experience.
Our test used Grafana dashboards heavily to monitor the relevant components. It was with system monitoring that we could discover the wavy auto-scaling patterns.
It also let us run the test in a real production system, confident that we would know before we entered the danger zone.
3. Different test types expose different weaknesses in the system
The spike test exposed the limits of the CPU utilization; the soak test also revealed the proportional relationship between read time and number of records. Component testing isn’t enough.
We tested every component in isolation as it rolled out to production. But, it wasn’t until we ran a test on the system as an integrated whole that we discovered how failure can cascade through the system. To really test your system, you have to test how its components interact with each other.
4. The real best practice is thinking
Every SUT is different. To prescribe best practices, you are going to have to be very general. Because the right test for your SUT is going to depend on the particularities of your system, SLOs, and load-generating abilities.
The easiest way to get started with k6 is through Grafana Cloud k6. The free tier includes 500 virtual user hours/month for k6 testing and more. Sign up for free now!


