

Running distributed load tests on Kubernetes
One of the questions we often get in the forum is how to run distributed Grafana k6 tests on your own infrastructure. While we believe that running large load tests is possible even when running on a single node, we recognize that this type of load testing is something some of our users might want to do.
There are at least a couple of reasons why you would want to do this:
- You run everything else in Kubernetes and would like k6 to be executed in the same fashion as all your other infrastructure components.
- You want to run your tests within your private network for security and/or privacy reasons.
Prerequisites
To follow along with this load testing example, you’ll need access to a Kubernetes cluster, with enough privileges to apply objects.
You’ll also need:
The Kubernetes operator pattern
The operator pattern is a way of extending Kubernetes so that you may use custom resources to manage applications running in the cluster. The pattern aims to automate the tasks that a human operator would usually do, like provisioning new application components, changing the configuration, or resolving problems that occur.
This is accomplished using custom resources which, for the scope of this article, could be compared to the traditional service requests that you would file to your system operator to get changes applied to the environment.
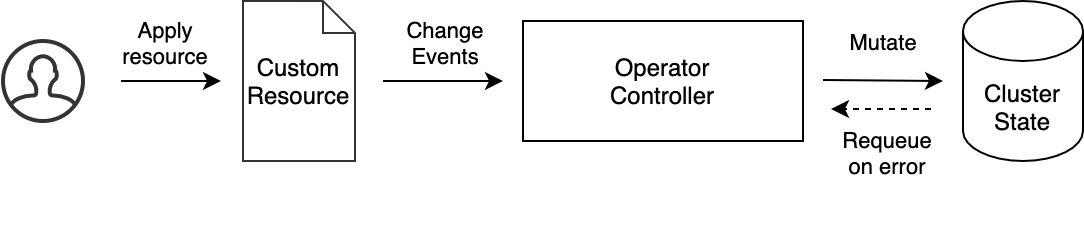
The operator will listen for changes to, or creation of, k6 custom resource objects. Once a change is detected, it will react by modifying the cluster state, spinning up k6 test jobs as needed. It will then use the parallelism argument to figure out how to split the workload between the jobs using execution segments.
Using the k6 operator to run a distributed load test in your Kubernetes cluster
We’ll now go through the steps required to deploy, run, and clean up after the k6 operator.
Cloning the repository
Before we get started, we need to clone the operator repository from GitHub and navigate to the repository root:
$ git clone https://github.com/grafana/k6-operator && cd k6-operatorDeploying the operator
Deploying the operator is done by running the command below, with kubectl configured to use the context of the cluster that you want to deploy it to.
First, make sure you are using the right context:
kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* harley harley harley
jean jean jean
ripley ripley ripleyThen deploy the operator bundle using make. This will also apply the roles, namespaces, bindings, and services needed to run the operator.
make deploy
/Users/simme/.go/bin/controller-gen "crd:trivialVersions=true" rbac:roleName=manager-role webhook paths="./..." output:crd:artifacts:config=config/crd/bases
cd config/manager && /Users/simme/.go/bin/kustomize edit set image controller=ghcr.io/k6io/operator:latest
/Users/simme/.go/bin/kustomize build config/default | kubectl apply -f -
namespace/k6-operator-system created
customresourcedefinition.apiextensions.k8s.io/k6s.k6.io created
serviceaccount/k6-operator-controller created
role.rbac.authorization.k8s.io/k6-operator-leader-election-role created
clusterrole.rbac.authorization.k8s.io/k6-operator-manager-role created
clusterrole.rbac.authorization.k8s.io/k6-operator-proxy-role created
clusterrole.rbac.authorization.k8s.io/k6-operator-metrics-reader created
rolebinding.rbac.authorization.k8s.io/k6-operator-leader-election-rolebinding created
clusterrolebinding.rbac.authorization.k8s.io/k6-operator-manager-rolebinding created
clusterrolebinding.rbac.authorization.k8s.io/k6-operator-proxy-rolebinding created
service/k6-operator-controller-manager-metrics-service created
deployment.apps/k6-operator-controller-manager createdWriting our test script
Once that is done, we need to create a config map containing the test script. For the operator to pick up our script, we need to name the file test.js. For this article, we’ll be using the test script below:
import http from 'k6/http';
import { check } from 'k6';
export const options = {
stages: [
{ target: 200, duration: '30s' },
{ target: 0, duration: '30s' },
],
};
export default function () {
const result = http.get('https://test-api.k6.io/public/crocodiles/');
check(result, {
'http response status code is 200': result.status === 200,
});
}Before we continue, we’ll run the script once locally to make sure it works:
$ k6 run test.jsIf you’ve never written a k6 test before, we recommend that you start by reading this getting started article from the documentation, just to get a feel for how it works.
Let’s walk through this script and make sure we understand what is happening: We’ve set up two stages that will run for 30 seconds each. The first one will ramp up linearly to 200 VUs over 30 seconds. The second one will ramp down to 0 again over 30 seconds.
In this case the operator will tell each test runner to run only a portion of the total VUs. For instance, if the script calls for 40 VUs, and parallelism is set to 4, the test runners would have 10 VUs each.
Each VU will then loop over the default function as many times as possible during the execution. It will execute an HTTP GET request against the URL we’ve configured, and make sure that it responds with HTTP Status 200. In a real test, we’d probably throw in a sleep here to emulate the think time of the user, but as the purpose of this article is to run a distributed test with as much throughput as possible, I’ve deliberately skipped it.
Deploying our test script
Once the test script is done, we have to deploy it to the Kubernetes cluster. We’ll use a ConfigMap to accomplish this. The name of the map can be whatever you like, but for this demo we’ll go with crocodile-stress-test.
If you want more than one test script available in your cluster, you just repeat this process for each one, giving the maps different names.
$ kubectl create configmap crocodile-stress-test --from-file /path/to/our/test.js
configmap/crocodile-stress-test created⚠️Namespaces
For this to work, the k6 custom resource and the config map needs to be deployed in the same namespace.
Let’s have a look at the result:
$ kubectl describe configmap crocodile-stress-test
Name: crocodile-stress-test
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
test.js:
----
import http from 'k6/http';
import { check } from 'k6';
export let options = {
stages: [
{ target: 200, duration: '30s' },
{ target: 0, duration: '30s' },
],
};
export default function () {
const result = http.get('https://test-api.k6.io/public/crocodiles/');
check(result, {
'http response status code is 200': result.status === 200,
});
}
Events: <none>The config map contains the content of our test file, labelled as test.js. The operator will later search through our config map for this key, and use its content as the test script.
Creating our custom resource (CR)
To communicate with the operator, we’ll use a custom resource called K6. Custom resources behave just as native Kubernetes objects, while being fully customizable. In this case, the data of the custom resource contains all the information necessary for k6 operator to be able to start a distributed load test:
apiVersion: k6.io/v1alpha1
kind: K6
metadata:
name: k6-sample
spec:
parallelism: 4
script:
configMap:
name: crocodile-stress-test
file: test.jsFor Kubernetes to know what to do with this custom resource, we first need to specify what API version we want to use to interpret its content, in this case k6.io/v1alpha1. We’ll then set the kind to K6, and give our resource a name.
As the specification for our custom resource, we now have the option to use several different properties. For the full description of possible options, please see the README. Let’s name a few of them here:
Parallelism
Configures how many k6 test runner jobs the operator should spawn.
Script
The name of the config map containing our script.js file.
Separate
Whether the operator should allow multiple k6 jobs to run concurrently on the same node. The default value for this property is false, allowing each node to run multiple jobs. This can be used to help manage the resources on each node to ensure it doesn’t become a bottleneck, in the case of large load tests.
Service account
You can also use a custom service account, which you can optionally set for the runner and starter objects.
Runner
Lets you configure options for the test runner pods, such as adding resource limits, setting up affinity and anti-affinity rules, or using a custom image of k6 (such as one with extensions).
Starter
Lets you configure options for the starter pod, such as a custom image of k6 or any labels/annotations you’d like to add.
Arguments
Allows you to pass arguments to each k6 job, just as you would from the CLI. For instance --tag testId=crocodile-stress-test-1,--out out, or —no-connection-reuse.
Deploying our custom resource
We will now deploy our custom resource using kubectl, and by that, start the test:
$ kubectl apply -f /path/to/our/k6/custom-resource.yml
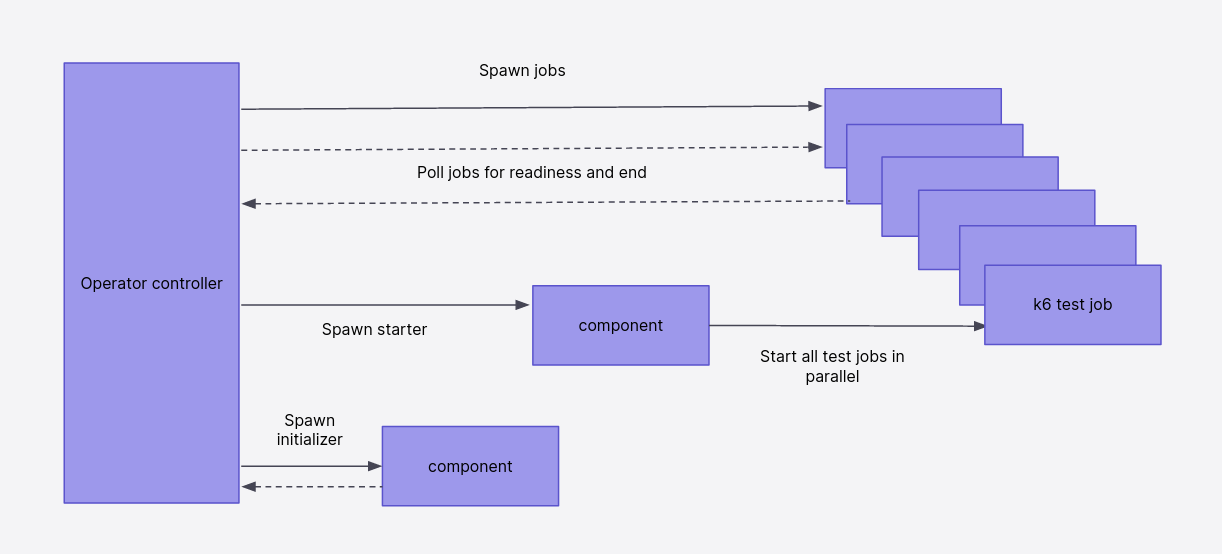
k6.k6.io/k6-sample createdOnce we do this, the k6 operator will pick up the changes and start the execution of the test. This looks somewhat along the lines of what is shown in this diagram:
Let’s make sure everything went as expected:
$ kubectl get k6
NAME AGE
k6-sample 2s
$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
k6-sample-1 0/1 12s 12s
k6-sample-2 0/1 12s 12s
k6-sample-3 0/1 12s 12s
k6-sample-4 0/1 12s 12s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
k6-sample-3-s7hdk 1/1 Running 0 20s
k6-sample-4-thnpw 1/1 Running 0 20s
k6-sample-2-f9bbj 1/1 Running 0 20s
k6-sample-1-f7ktl 1/1 Running 0 20sThe pods have now been created and put in a paused state until the operator has made sure they’re all ready to execute the test. Once that’s the case, the operator deploys two other jobs, k6-sample-starter and k6-sample-initializer, which are responsible for making sure all our runners start execution at the same time and for coming up with some sanity limits for the test run.
Let’s wait a couple of seconds and then list our pods again:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
k6-sample-3-s7hdk 1/1 Running 0 76s
k6-sample-4-thnpw 1/1 Running 0 76s
k6-sample-2-f9bbj 1/1 Running 0 76s
k6-sample-1-f7ktl 1/1 Running 0 76s
k6-sample-initializer-29799 0/1 Completed 0 66s
k6-sample-starter-scw59 0/1 Completed 0 56sAll right! The starter and the initializer have completed and our tests are hopefully running. To make sure, we can check the logs of one of the jobs:
$ kubectl logs k6-sample-1-f7ktl
[...]
Run [ 100% ] paused
default [ 0% ]
Run [ 100% ] paused
default [ 0% ]
running (0m00.7s), 02/50 VUs, 0 complete and 0 interrupted iterations
default [ 1% ] 02/50 VUs 0m00.7s/1m00.0s
running (0m01.7s), 03/50 VUs, 13 complete and 0 interrupted iterations
default [ 3% ] 03/50 VUs 0m01.7s/1m00.0s
running (0m02.7s), 05/50 VUs, 41 complete and 0 interrupted iterations
default [ 4% ] 05/50 VUs 0m02.7s/1m00.0s
[...]And with that, our test is running! 🎉 After a couple of minutes, we can list the jobs again to verify they’ve all completed:
$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
k6-sample-initializer 1/1 2s 6m12s
k6-sample-starter 1/1 8s 6m2s
k6-sample-3 1/1 96s 6m22s
k6-sample-2 1/1 96s 6m22s
k6-sample-1 1/1 97s 6m22s
k6-sample-4 1/1 97s 6m22sCleaning up
To clean up after a test run, we delete all resources using the same yaml file we used to deploy it:
$ kubectl delete -f /path/to/our/k6/custom-resource.yml
k6.k6.io "k6-sample" deletedWhich deletes all the resources created by the operator as well, as shown below:
$ kubectl get jobs
No resources found in default namespace.
$ kubectl get pods
No resources found in default namespace.Alternatively, we can use the cleanup: "post" option to make controller remove resources on its own.
Cloud output
Starting with v0.0.7, k6 operator has support for Cloud output, as a subscription feature. This is a distributed version of local Cloud output in context of Kubernetes operator.
To use it, we need to firstly deploy our k6 Cloud token. We do that by uncommenting the Cloud output section in main kustomization.yaml and paste our token to the token field. See the Cloud app’s settings to retrieve that token. Once that is done, we need to run make deploy to make sure our token is deployed to the cluster:
$ make deploy
/Users/simme/.go/bin/controller-gen "crd:trivialVersions=true" rbac:roleName=manager-role webhook paths="./..." output:crd:artifacts:config=config/crd/bases
cd config/manager && /Users/simme/.go/bin/kustomize edit set image controller=ghcr.io/k6io/operator:latest
/Users/simme/.go/bin/kustomize build config/default | kubectl apply -f -
namespace/k6-operator-system unchanged
customresourcedefinition.apiextensions.k8s.io/k6s.k6.io configured
serviceaccount/k6-operator-controller unchanged
role.rbac.authorization.k8s.io/k6-operator-leader-election-role unchanged
clusterrole.rbac.authorization.k8s.io/k6-operator-manager-role configured
clusterrole.rbac.authorization.k8s.io/k6-operator-metrics-reader unchanged
clusterrole.rbac.authorization.k8s.io/k6-operator-proxy-role unchanged
rolebinding.rbac.authorization.k8s.io/k6-operator-leader-election-rolebinding unchanged
clusterrolebinding.rbac.authorization.k8s.io/k6-operator-manager-rolebinding unchanged
clusterrolebinding.rbac.authorization.k8s.io/k6-operator-proxy-rolebinding unchanged
secret/k6-operator-cloud-token-f295md8b95 configured
service/k6-operator-controller-manager-metrics-service unchanged
deployment.apps/k6-operator-controller-manager unchangedNote the appearance of the secret/k6-operator-cloud-token-f295md8b95 line.
Now we can simply pass the --out cloudto our custom resource definition:
apiVersion: k6.io/v1alpha1
kind: K6
metadata:
name: k6-sample
spec:
parallelism: 4
arguments: --out cloud
script:
configMap:
name: crocodile-stress-test
file: test.jsAnd that’s it! Once the test starts, each runner will start sending metrics to k6 Cloud and we’ll be able to see them in the app:
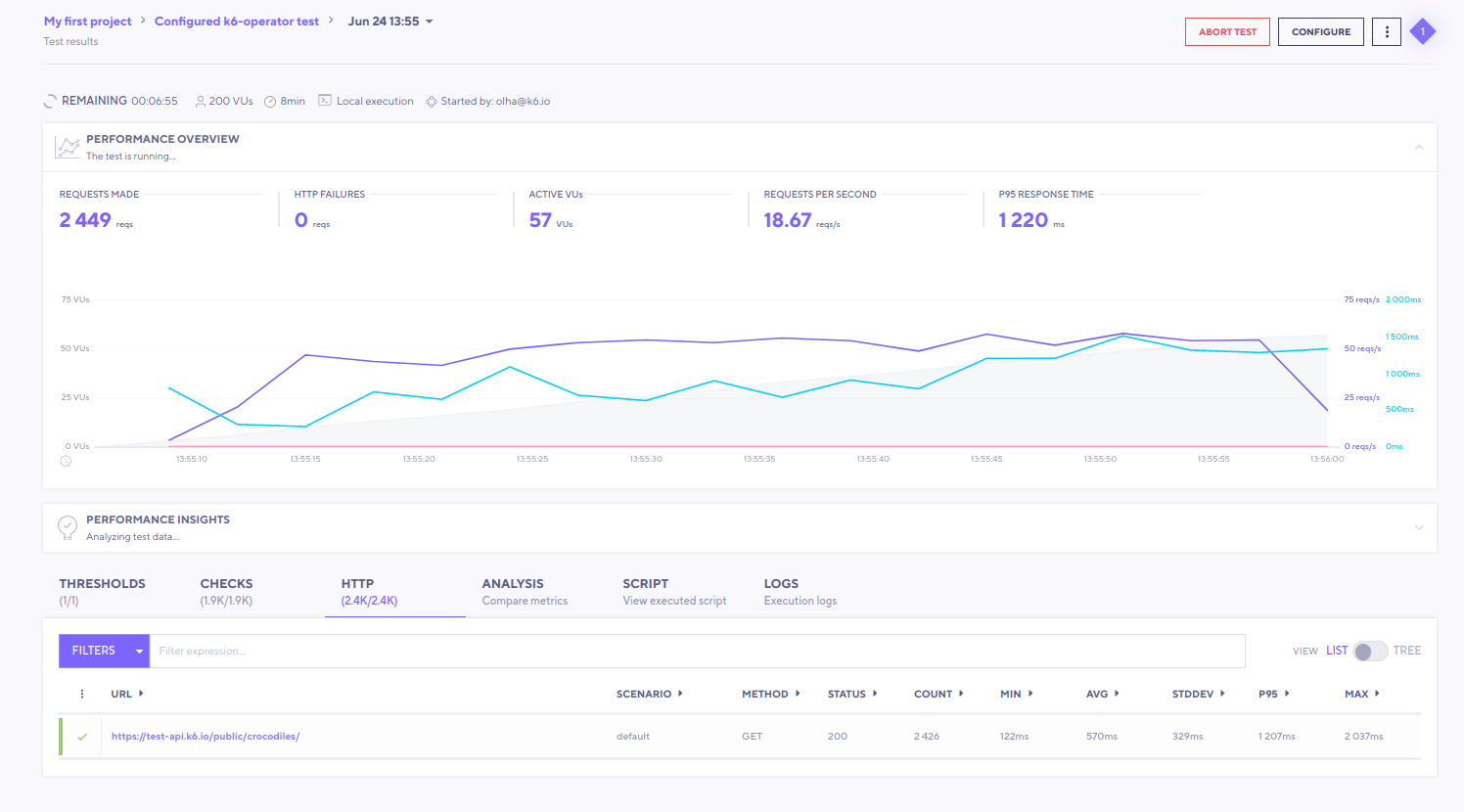
It must be noted that, currently, this feature has limitation on parallelism: it should be no more than 20.
⚠️ Deleting the operator
If you for some reason would like to delete the operator altogether, just run
make deletefrom the root of the project.The idea behind the operator, however, is that you let it remain in your cluster between test executions, only applying and deleting the actual k6 custom resources used to run the tests.
Things to consider
While the operator makes running distributed load tests a lot easier, it still comes with a couple of drawbacks or gotchas that you need to be aware of and plan for. For instance, the lack of metric aggregation.
We’ll go through in detail how to set up the monitoring and visualization of these test runs in a future article, but for now, here’s a list of things you might want to consider:
Metrics will not be automatically aggregated by default
Metrics generated by running distributed k6 tests using the operator won’t be aggregated by default, which means that each test runner will produce its own results and end-of-test summary.
To be able to aggregate your metrics and analyze them together, you’ll either need to:
- Set up some kind of monitoring or visualization software (such as Grafana) and configure your k6 custom resource to make your jobs output there.
- Use Logstash, Fluentd, Splunk, or similar to parse and aggregate the logs yourself.
- As of v0.0.7, you can also rely on k6 Cloud output for aggregations, as described above.
Thresholds are not evaluated across jobs at runtime by default
As the metrics are not aggregated at runtime, your thresholds won’t be evaluated using third-party aggregations either. One way to solve this is by manually setting up alarms for passed thresholds in your monitoring or visualization software instead.
Another way is possible if you use v0.0.7+ of the operator and k6 Cloud output: in this case, k6 thresholds can be evaluated by the k6 Cloud.
Overpopulated nodes might create bottlenecks
You want to make sure your k6 jobs have enough CPU and memory resources to actually perform your test. Using parallelism alone might not be sufficient. If you run into this issue, experiment with using the separate property.
It increases total cost of ownership
The k6 operator significantly simplifies the process of running distributed load tests in your own cluster. However, there still is a maintenance burden associated with self-hosting and data storage. If you’d rather skip that, as well as the other drawbacks listed above, and instead get straight to load testing, you might want to have a look at the Grafana Cloud k6 offering.
See also
For more information, check out these resources:
- The k6 operator project on GitHub
- Distributed load testing using Kubernetes with k6 (k6 Office Hours #72) (demo and project)
Grafana Cloud is the easiest way to get started with Grafana k6 and performance testing. We have a generous forever-free tier and plans for every use case. Sign up for free now!


