

How Grafana Mimir’s split-and-merge compactor enables scaling metrics to 1 billion active series
Grafana Mimir, our new open source time series database, introduces a horizontally scalable split-and-merge compactor that can easily handle a large number of series. In a previous blog post, we described how we did extensive load testing to ensure high performance at 1 billion active series.
In this article, we will discuss the challenges with the existing Prometheus and Cortex compactors and the new features of Grafana Mimir’s compactor. These features enable us to easily scale horizontally to allow us to ingest 1 billion active series, internally replicate to 3 billion time series for redundancy, and compact them back down to 1 billion again for long-term storage.
Problems, problems everywhere
How do we ingest 1 billion series into Grafana Mimir? One thing is clear – we need a lot of ingesters! If a single ingester can handle 10 million active series, and we also use 3x replication to ensure fault tolerance and to guarantee durability, we need to run 300 of them. But with this many ingesters, we have a new problem: Each ingester will produce a single TSDB block every 2 hours. That’s 3,600 new TSDB blocks every day. At ~5.5 GB per TSDB block with 10 million series, that’s about 20 TB of data daily.
We cannot efficiently search all these blocks from long-term storage when a user runs a query or opens a dashboard in Grafana. Mimir uses compaction to solve this problem. Compaction reduces the number of blocks in storage, which speeds up querying and also deduplicates samples. We need to deduplicate samples because thanks to using 3x replication, each sample was accepted by three different ingesters and is stored in three different ingester-generated blocks.
The original compactor in Cortex was quite limited – while it could run multiple instances of the compactor, each instance had to work on a different tenant. Most recent improvements in the Cortex compactor address this issue, and allow for parallel compaction of a single tenant in multiple instances. But compacting 300 ingester-generated blocks together still poses multiple challenges:
Problem number one is that downloading, compacting, and uploading 300 blocks, each with 10M series, takes a lot of space and time. One such block covering 2 hours of data needs about 5.5 GB of disk space, so 300 of them would require 1.5 TB of disk space. Compaction is a single-threaded task, and compacting 300 blocks together would take many hours, even days – if it would succeed at all. We want compaction to run faster than that, to avoid dealing with uncompacted blocks as soon as possible, because uncompacted blocks add stress to the querier and store-gateways, and they are slow to query.

Another problem is that even if we manage to merge 300 blocks into one, the resulting output block will break the limits of Prometheus TSDB format. The TSDB block has a limit of 64 GiB of total index size and 4 GiB per individual index section. Compaction attempts then fail with a “compact blocks … exceeding max size of 64GiB” error message. Unfortunately, these limits make it impossible to store 1B series into a single TSDB block. Limits may be avoided in the future by introducing an updated format of the TSDB index, but that also requires careful design and discussion across the wider Prometheus community.
The compactor in Mimir has multiple features up its sleeve to solve these problems.
Feature 1: How Grafana Mimir groups input blocks
Mimir’s compactor doesn’t compact all ingester-generated blocks at once. The compactor will instead divide all blocks into groups, and compact each group of blocks individually. For example, instead of one large compaction with 300 blocks, we can run 15 small compactions, each merging 20 blocks. This is a much easier task to perform, with fewer blocks to download and merge per compaction, and with the ability to compact all the groups in parallel!
However, compacting random blocks together isn’t very efficient when it comes to deduplication. For efficient deduplication, we need to compact the same series from different blocks together. Let’s see what other features help us with that.

Feature 2: How Grafana Mimir shards (splits) series
The next feature used by the Mimir compactor is sharding of series during compaction. The traditional compactor takes multiple input blocks and produces a single output block. The compactor in Mimir can produce multiple blocks, each block containing only a subset of input series. Series are sharded into output blocks based on their hash and the configured number of output blocks. For example, instead of storing all 1B series into a single block, we can divide the series into 32 output blocks. Each output block is assigned a “shard ID” like “5_of_32”, meaning this block is the 5th shard out of 32. This solves the problem with TSDB format limits.

The diagram above and those that follow show examples of when the Grafana Mimir split-and-merge compactor is configured with 3 shards.
There are several benefits of splitting series like this:
- The configurable number of shards allows us to accommodate a very large number of active series, which would otherwise not fit into a single block.
- We know exactly which series are in each block. For example, a block with shard ID “5_of_32” will only contain those series for which series.hash() mod 32 == 5.
- Merging multiple blocks with the same shard ID will preserve their shard ID! Let’s discuss what this means …
Feature 3: How Grafana Mimir merges shards
We mentioned that merging blocks with the same shard ID will preserve this shard ID. For example, if we have a block covering the time range “today from 6:00 to 8:00, with shard ID 5_of_32,” and also a block with data from “today between 8:00 and 10:00, shard ID 5_of_32,” we can merge these two blocks together into a single, larger block covering both time ranges: “today, from 6:00 to 10:00, shard ID 5_of_32.” For each series included in this block, the property series.hash() mod 32 == 5 still holds! This feature allows us to do our traditional merging of blocks into 12h or 24h blocks – one per shard.
This is a repeatable operation. Doing it again on the same data produces the same results. Remember our 3x ingester replication? This design guarantees that deduplication of replicated samples works efficiently, as the data will always come at rest in the same shards.
One caveat: This mechanism depends on modulo operations. If we change the modulo, we change everything. If the amount of data increases to a point where we need to increase the shard count, we cannot merge the resulting shards anymore. For example, mod 32 shards can only be merged with other mod 32 ones; if we introduce mod 48 shards later, they can only be merged with other mod 48 ones.
How does the Grafana Mimir compactor work?
The Mimir compactor uses these features together in order to scale to a large number of series. Each compactor instance runs a planner. The planner will look at all available blocks in the storage, find blocks that need to be compacted, and then compute the compaction jobs.
There are two types of jobs that the compactor can perform:
- Split jobs: Blocks generated by ingester are first grouped, and each group of blocks is then compacted separately (feature 1). During this compaction, we also shard series into output blocks (feature 2), which is why we call these jobs “split” jobs.
- Merge jobs: Merge jobs use the same traditional block merging compactions, with the restriction that we can only merge blocks with the same shard ID (feature 3). If blocks were not previously split, they have an empty shard ID, which can be matched and merged.
Each compactor instance runs a planner and computes all split and merge jobs, depending on the current state of the blocks in the storage when the planner runs. However, a compactor instance will only execute jobs that the instance “owns,” based on the hash ring.
Grafana Mimir’s split-and-merge compactor can easily distribute both split and merge jobs among many compactor instances, speeding up the overall compaction process! This also allows us to horizontally scale the compactor: The more compactors we add, the faster overall compaction can run!
For even more details, which are out of scope for this blog post, please see our documentation on how compaction works in Grafana Mimir.
How compaction works in practice
Let’s see how it works in practice. To continue with our example of 300 ingesters, each ingesting ~10M series, let’s say that we use 15 groups when compacting ingester blocks and 32 shards.
Every two hours, 300 ingesters produce a single block each. After blocks are uploaded to the storage, compactors start discovering these blocks, and they start compacting found blocks. In the first step, we need to perform 15 compactions (“split” jobs), one for each group of 20 blocks – 300 blocks randomly divided into 15 groups of 20 blocks per group. If groups are too big and compactions run too slowly, we can simply use more groups (with fewer blocks) and add more compactors. Each of these compactions will produce 32 output blocks with sharded series.
After this step is finished:
- We have performed 15 “split” compactions, producing sharded blocks “1_of_32” up to “32_of_32.”
- Altogether we have produced 15 * 32 = 480 new blocks and deleted the 300 original ingester blocks.
But the compactors are not done yet. When they discover new sharded blocks, compactors know that such blocks can be merged. We need to run one more compaction per shard, which means 32 more compactions. This time we also deduplicate samples (because we are compacting the same series) and produce a single output block per shard.
At this point:
- We have performed 32 additional “merge” compactions, each merging all blocks with a given shard ID (eg. “5_of_32”).
- We have produced 32 new blocks (one per shard ID) and deleted the previous 480 blocks.

All of this happens every two hours. All split jobs can run in parallel, and the same is true for all merge jobs for a given time range. (Merge jobs will not be started if there are still split jobs for the same time range.) This makes for better horizontal scaling of the compactors.

After 12 hours, we can now easily merge all blocks with the same shard ID together to produce a single 12h block for each shard. We can then do the same after 24h. One day and a few hundred compactions later, we end up with only 32 compacted blocks per day, each block containing 1B / 32 = ~31M series.
Query sharding and compactor sharding
But there’s more! A few sections earlier, we said that we know exactly which series are in which block. Grafana Mimir uses this fact to speed up series lookup when a query is accelerated by query sharding!
Grafana Mimir can speed up many types of PromQL queries by leveraging their inner structure and running partial queries in parallel. As a trivial example, the simple query “sum(rate(metric[1m]))” can be executed as:
sum(
concat(
sum(rate(metric{__query_shard__="1_of_4"}[1m]))
sum(rate(metric{__query_shard__="2_of_4"}[1m]))
sum(rate(metric{__query_shard__="3_of_4"}[1m]))
sum(rate(metric{__query_shard__="4_of_4"}[1m]))
)
)(Note: concat is used to show when partial query results are concatenated/merged by the query-frontend.)
Each sum(rate(metric{...})) partial query is then executed as a separate query, which allows Mimir to run these partial queries in parallel.
When the querier is fetching data for metric{__query_shard__="2_of_4"}, it knows to look only for metrics in the second shard out of four. The algorithm to check if a series belongs to the given shard is the same as the one used by the compactor: series.hash() mod 4 == 2.
If the number of shards used by the compactor and query sharding is exactly the same, then the querier can simply look at the relevant block-shard to find the series it is looking for.
More compactor shards than query shards
If shards differ, we can still benefit from compactor sharding. For example, let’s say that the number of query shards is 4, but the compactor uses 32 shards. In this case, the querier can only query 8 blocks out of 32, specifically the blocks with compactor shard ID 2_of_32, 6_of_32, 10_of_32, … up to 30_of_32. Blocks with other shard IDs cannot possibly contain any series that would belong to the “2_of_4” shard used by the query that the querier is running.

More query shards than compactor shards
The situation is similar when the number of query shards is higher than the number of compactor shards. With only 4 compactor shards, the lookup for metric{__query_shard=”5_of_8”} must hit the block with shard ID “3_of_4”. Also, the lookup for metric{__query_shard=”6_of_8”} must use the same “3_of_4” block.

In any case, series sharding by the compactor helps us to reduce the number of blocks that we need to query from long-term storage, even if the number of shards between query sharding and compactor sharding is not exactly the same. In general, we can perform this reduction if the number of shards in query sharding is divisible by the number of compactor shards, or vice versa.
With query sharding enabled, Grafana Mimir will compute a number of query shards for a given query based on configuration options, range of the query, and also compactor shards, so the optimization described in this section can work automatically.
Conclusion
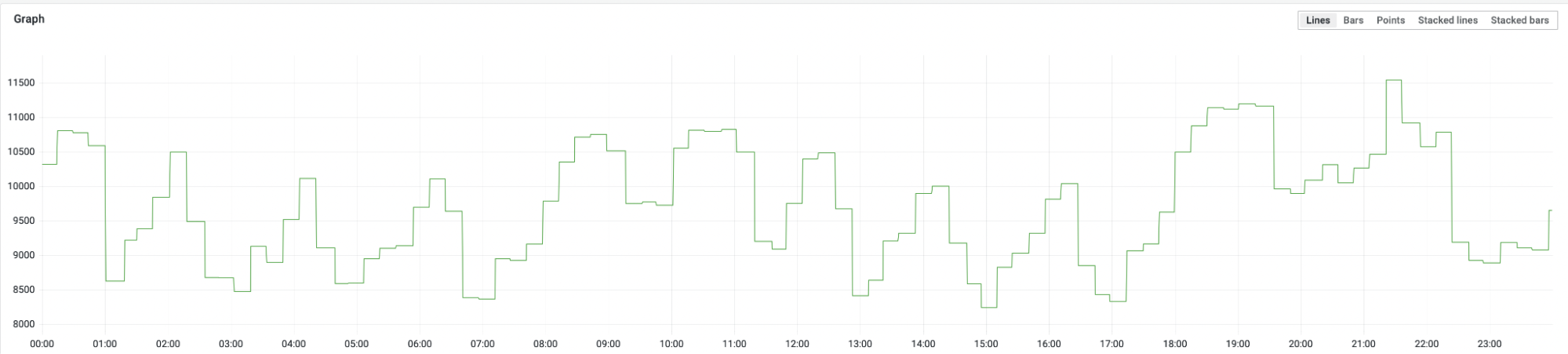
By using the techniques described above and with some additional compactor improvements, the Grafana Mimir compactor is able to keep up with the regular arrival of blocks with 3 billion series coming from all the ingesters, deduplicating them down to 1 billion. In our setup with 600 ingesters, 48 block groups, and 48 compactor shards, we see between 10 and 100 compactors compacting blocks for the tenant at any given moment, and a stable number of blocks for the tenant over time.
Active compactors over one day:

Number of blocks over one day (same time period as previous graph):
FAQ about the Mimir compactor
What are the limits and possible future improvements in the Mimir compactor?
One possible improvement we have seen has to do with how compaction jobs are distributed among compactor instances. Right now all compactors do their own planning and decide which jobs to run based on the ring. This works, but has some problems too, because there are dependencies between the jobs. For example, compactors plan all “split” jobs before planning any “merge” jobs. Sometimes multiple split jobs fall onto the same compactor (due to hashing and ring), and then these jobs need to wait for each other.
One way to fix this would be to introduce a global queue of compactor jobs, instead of relying on the ring. This would allow the distribution of jobs between compactors in a more fair approach, and as long as there are free compactor instances, it would avoid blocking compaction jobs.
So we will have multiple blocks per day. How does that affect queriers and store-gateways?
Both queriers and store-gateways need to work with more blocks now. Queriers don’t do much work, but store-gateways download and (lazily) load the blocks into memory. However, if we know that we can compact blocks in time, we can use the newly introduced option for store-gateways to ignore blocks for yet-uncompacted time ranges (e.g., blocks from the last 6h).
Having multiple blocks per day also helps store-gateways. With a single block per day, if we query a specific day, this query will hit a single store-gateway. With multiple blocks per day, blocks will be sharded across multiple store-gateways, and the query can hit more of them, thus spreading the query workload.
What happens when we reconfigure the number of groups for splitting, or number of shards?
Reconfiguring the number of groups for splitting may cause some blocks to be split by multiple compaction jobs. This temporarily adds extra work to compactors, but is otherwise harmless – all blocks will eventually be compacted and samples will be deduplicated correctly.
Changing the number of shards is also a safe operation. Each block generated during the split stage has its own “compactor shard ID,” which also includes the total number of shards. When this total number of shards changes (say, from A to B), blocks using the previous value (A) will not be merged with new blocks (using B). This means that for a given day, there will be two streams of blocks, and there will be A+B total blocks after all compactions are finished, instead of just having “A” number of blocks (before the change) or “B” (after the change). All querying will work correctly.
How does a compactor deal with old blocks that were not split before?
Blocks that are not split have empty “compactor shard ID” and can only be merged with other blocks that are not split. These blocks can be queried as usual.
How can we configure this in our Mimir installation?
The split-and-merge compactor is the only compactor available in Grafana Mimir. There are a few new options that can be set:
- -compactor.split-groups: number of groups to use during the split phase
- -compactor.split-and-merge-shards: number of series shards to produce during the split phase
- -compactor.compactor-tenant-shard-size: number of compactor instances that a single tenant can use. Useful in multi-tenant systems.
All of these values can also be set per tenant, so tenants with different needs will use a different number of split groups and series shards. See the Grafana Mimir configuration parameters documentation.
Do you have recommended values for splitting groups and merging shards?
Right now our recommendation is to target ~25M series per block. For tenants with 100M series, that means using 4 series shards. The number of split groups depends on the number of ingesters and time of compaction, but for a start we recommend the number of split groups to be equal to the number of series shards.
Can I use blocks generated by Mimir in Prometheus or Thanos, or are there compatibility issues?
Blocks generated by Grafana Mimir during compaction with series sharding are the same TSDB blocks as used by Prometheus or Thanos. Grafana Mimir adds an extra label to such blocks into the “Thanos” section of the meta.json file. Prometheus will attempt to merge blocks covering the same time range together, which may hit the TSDB index limits as mentioned above. Thanos will use the extra metadata as “external labels.”
Other than these small issues, the blocks are regular Prometheus TSDB blocks, and all TSDB-related tools work with them just fine.
Leverage Grafana Mimir for yourself
To learn more about Mimir and how to deploy it yourself:
- Read our extensive Grafana Mimir documentation
- Follow our tutorial to get started
- Sign up for our “Intro to Grafana Mimir” webinar on April 26
- Join our Grafana Labs Community Slack
And if you’re interested in helping us scale Mimir to the next order of magnitude, we’re hiring!
Grafana Cloud is the easiest way to get started with metrics, logs, traces, and dashboards. We have a generous free forever tier and plans for every use case. Sign up for free now!


