

Full trace retention search comes to Grafana Cloud
This week we have turned on full trace retention search (beta) in Grafana Cloud Traces. This feature was also introduced in the recent release of Grafana Tempo v1.3.
Previously, if you brought up your Grafana Cloud Traces data source, you were greeted with this message:

This message simply warned the user that the Grafana Tempo search was calibrated for recent traces only, regardless of the selected time window.
Now we have rolled out full trace retention search to all of our Google Cloud Platform-based clusters! That means all of the features you are currently enjoying for recent trace searches are now available across your entire 30-day retention.

Above: Trace search criteria in Grafana Tempo. Note that the maximum searchable range is currently 24 hours.
Behind the scenes
Grafana Tempo search is currently built on top of serverless technologies. Every time you initiate a search, hundreds (or even thousands) of Google Cloud Functions are spun up which scan your data and return search results in just a few seconds.
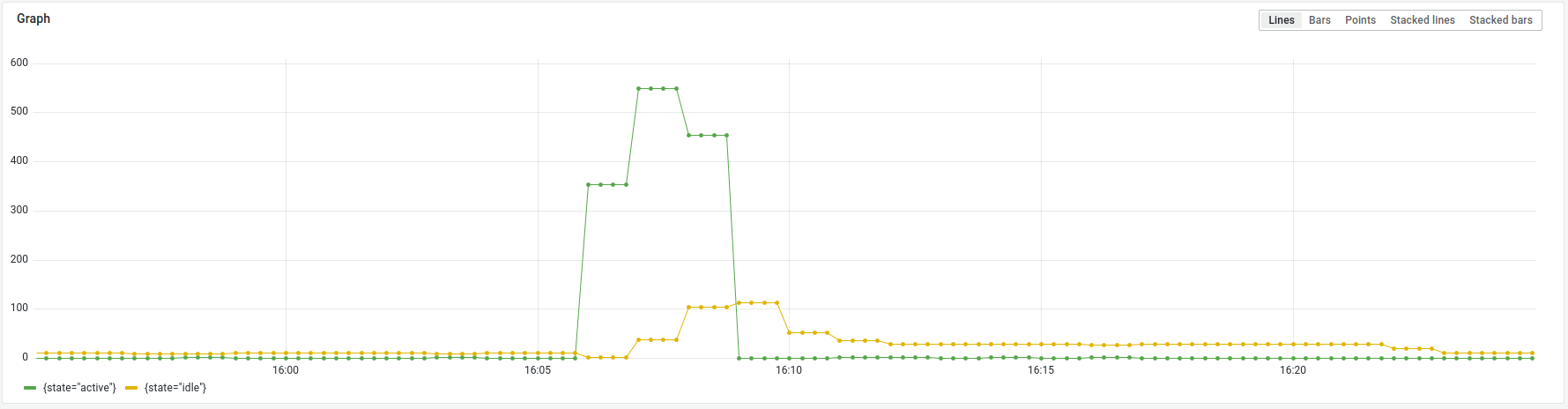
Above: Typical serverless function spikes to service backend search queries.
This feature is currently live in all of our GCP-based clusters. Thankfully, this covers our major clusters in the United States, Europe, and Australia. If you are a Grafana Cloud Traces customer, this almost certainly includes you! (Don’t have a Grafana Cloud account? Sign up for free now!)
Dropping beta
We are not quite ready to drop the beta label on full trace retention search. Ultimately, Tempo is about scale. It’s about being the biggest, baddest distributed tracing backend available and search is just not there yet.
Internally, we are able to search trace data at a rate of 30 GB/s to 60 GB/s. This may sound like a lot, but when you ingest 250 MB/s, it only takes 2 minutes to ingest 30 GB (and this doesn’t even take replication factor into account).
Also, there is a larger variance in search throughput than we’d like. 30 GB/s to 60 GB/s is a large range. This is due to our reliance on serverless technologies and the huge volume of data we are pulling out of Google Cloud Storage. It will probably always exist to some extent, but we believe we can still reduce the variance considerably.
What’s next?
We need to go faster. There’s not much more to it. We will continue to tweak our existing search algorithms and backend, but ultimately I believe an entirely new way to store trace data is needed to push this to the next level. Columnar formats are a likely option, but we’re still actively researching on this front.
Also we have some exciting new features coming up surrounding the metrics generator. Expect to see progress here both in OSS Grafana Tempo and Grafana.
Thanks for reading! If you have any questions or want up-to-date information join our #tempo channel in the Grafana Labs Community Slack. There’s also this handy community forum and the repo itself.
Happy tracing!
Grafana Cloud is the easiest way to get started with metrics, logs, traces, and dashboards. We have a generous free forever tier and plans for every use case. Sign up for free now!


