

Loki 2.4 is easier to run with a new simplified deployment model
Grafana Loki 2.4 is here!
It comes with a very long list of cool new features, but there are a couple things I really want to focus on here.
- Loki can now accept out of order writes
- Running Loki is easier than ever
Be sure to check out the full release notes and of course the upgrade guide to get all the latest info about upgrading Loki. Also check out our ObservabilityCON 2021 session Why Loki is easier to use and operate than ever before.
Supporting out of order logs
The strict ordering constraint on Loki has long been a challenge for many Loki users, and please believe me when I tell you that we didn’t do this just to be difficult. Ingesting log data quickly and in a memory efficient way is challenging!
Today, Loki groups incoming logs into blocks and when they reach a specific size those blocks are compressed. However, once incoming log lines are compressed, it becomes very difficult to insert new entries that are received out of order, specifically if that entry would need to be inserted into an already compressed block. Decompressing, recording, and re-compressing is slow and expensive.
We explored several ways of supporting out of order while trying to best manage the tradeoffs on performance and ordering flexibility. In the end, we came up with a solution we are really proud of, which is now available in the v2.4 release. An upcoming blog post will go into all the details of this solution, or if you are interested you can check out the design doc.
In short, we are thrilled to finally close the above issue and simplify the lives of many Loki users by allowing logs to be sent unordered to Loki!
Simple, Scalable Deployment
Next I want to talk about the work we’ve done to make it easier to run Loki. We’ve talked for a long time about how easy it is to get started with Loki by running it as a single process capable of ingesting and serving your logs.
But what if you want to run Loki in a highly available configuration? Or what if you want to take advantage of the query parallelization often talked about in our conference talks and webinars? You quickly found yourself at the limits of what the single binary could offer and were likely left staring wearily at the Helm or jsonnet of a Loki microservices configuration.
Don’t get me wrong — we love microservices. It’s how we run Loki at Grafana Labs, and it offers the most flexibility and configurability as well as the potential to scale to hundreds of TBs of logs per day. However, we also recognize it’s also our job to run Loki, and microservices are complex. For most people, this level of complexity is both unnecessary and a barrier to adoption.
This is why we put a significant effort into a hybrid mode we are calling the simple, scalable deployment. The idea is this: Take the simplicity of running Loki as a single binary but introduce an easy path to high availability and scalability.
Step 1: Single binary
Also known as the monolithic mode, this is the easiest way to get started with Loki, and we’ve made several significant improvements to this mode of operation. First, the single binary mode now runs a query frontend which is the component responsible for splitting and sharding queries. Now a single binary Loki can parallelize queries too!
Second, the single binary Loki can also be scaled by adding more instances and connecting them with a shared hash ring. We’ve also taken care of making sure the compactor is running and that only one instance of it runs automatically!
Adding more instances allows for sharding incoming writes over more processes as well as providing more CPU for more query parallelization allowing you to easily scale a Loki single binary instance for performance as well as enabling high availability runtime.
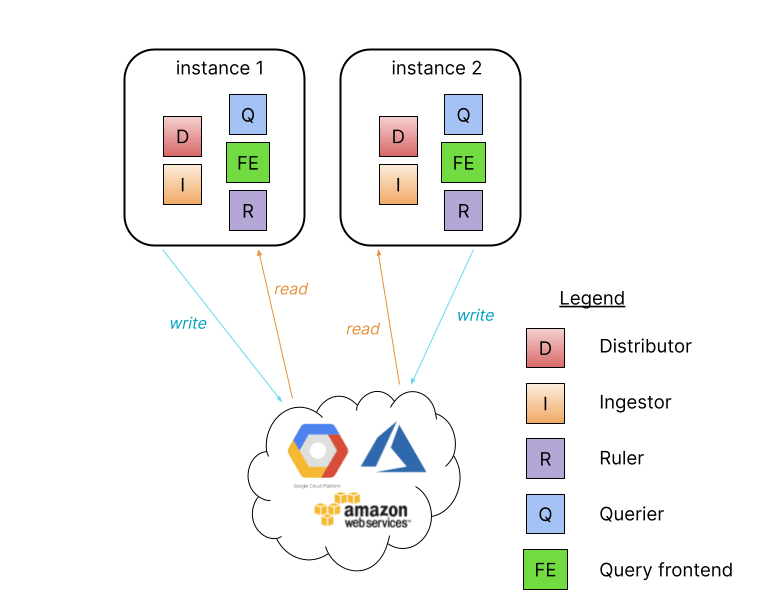
Note: Not shown above is the compactor which will use the ring to elect a single instance to run compactions.
Step 2: Simple, scalable deployment
This mode is a bridge between running Loki as a single binary/monolithic mode and full blown microservices. The idea is to give users more flexibility in scaling and provide the advantages of separating the read and write path in Loki.
This should be particularly appealing to someone who wants to run Loki outside of Kubernetes.
It works by taking the same binary/image and passing a -target=read and -target=write configuration flag.
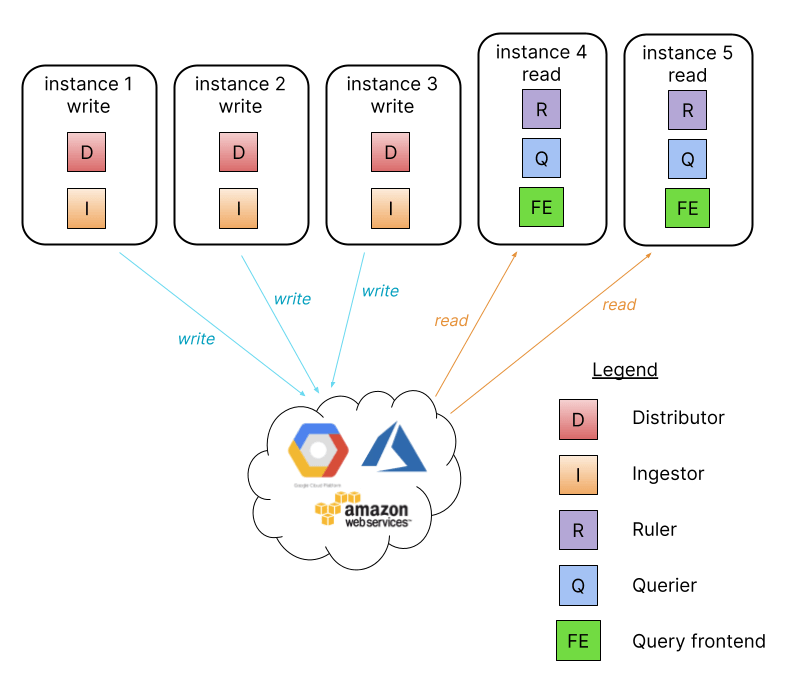
Note: Not shown above is the compactor which will use the ring to elect a single read instance to run compactions.
These new flags split up the internal components necessary for reads/writes into these separate processes, making it much easier to scale and monitor your read and write path separately. This also lets you add and remove read instances to increase/decrease the amount of query parallelism Loki is able to do so that you can scale read performance on demand, just like the microservices model.
Step 3: Microservices
For those who want the ultimate in flexibility, observability, and performance, Loki can still be run as individual component microservices just like before.

I think, however, many people will find this mode isn’t necessary, and the increased number of moving parts will be perhaps a hindrance more than a benefit. We will leave that up to you to decide and are very excited to provide you with more options for running Loki in a manner that suits you best!
Closing thoughts
The Loki team worked very hard to make v2.4 the easiest version of Loki to use yet. We are updating our Grafana Loki documentation, so look for more posts and examples on running Loki in these various modes soon!
The easiest way to get started with Grafana Loki is Grafana Cloud, with free and paid plans to suit every use case. If you’re not already using Grafana Cloud, sign up for free today.


