

Grafana Tempo 1.2 released: New features make monitoring traces 2x more efficient
Grafana Tempo 1.2 has been released! Among other things, we are proud to present both our first version to support search and the most performant version of Tempo ever released. There are also some minor breaking changes so make sure to check those out below.
If you want ALL the details you can always check out the v1.2 changelog, but if that’s too much, this post will cover all the big ticket items.
You can also check out our ObservabilityCON 2021 session dedicated to tracing, Tempo, and our newest product Grafana Enterprise Traces.
New features in Grafana Tempo 1.2
Recent traces search
Recent traces search allows Grafana Cloud users to search Tempo for traces that are still in the ingesters. This duration defaults to at least 15 minutes but can be modified by using the complete_block_timeout in the ingester config block. Search is currently designed around basic filtering of tags, duration, services, and span names. Do check it out!
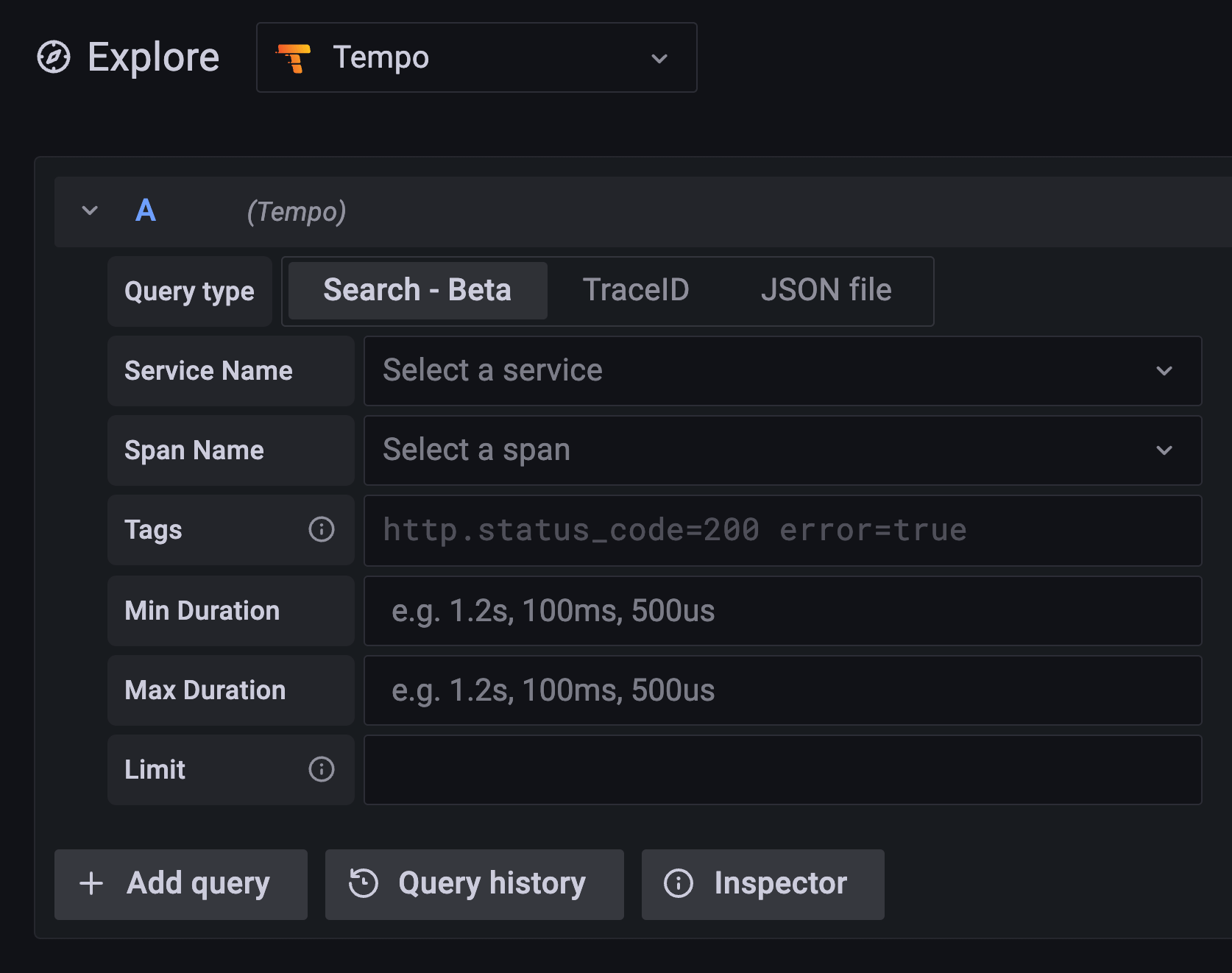
Search in Tempo and Grafana is still considered experimental and requires setting feature flags. Please consult the docs on how to enable it in both applications. This does come with a resource penalty, but v1.2 with search enabled is actually more performant than v1.1 (see below).
This release is a stepping stone to full backend search which is the team’s current priority. By focusing on recent traces the team was able to experiment with trace formats and other data structures designed to make querying traces efficient and fast. We are excited to deliver the next step in the near future!
Scalable single binary
Tempo 1.2 also brings a new operational mode we call scalable single binary. Before v1.2, Tempo was able to operate as a single binary or a set of distributed independent components:

Scalable single binary allows for a horizontally scalable single binary that contains every component. The components continue to act as if they were in a fully distributed setup (i.e., every distributor pushes to every ingester), but since they are packaged as a single binary, it can reduce operational burden.

This setup does not provide the same flexibility or the tight failure domains of a fully distributed deployment. However, it can provide a nice middle ground for engineers attempting to transition from the single binary to an HA setup.
Improved performance
Tempo 1.2 is the most performant version of Tempo released. The following graph shows bytes received over total Tempo CPU usage. It is roughly a measure of the efficiency at which Tempo ingests, organizes, and queries traces.

As you can see, Tempo 1.2 with search on is about 1.5x as efficient as v1.1, and if you don’t need the search features, it is almost 2x as efficient as v1.1. In fact the improvements have been so good that object storage (and accessing it) have started to become our major cost drivers.
Also v1.2 search is doing extra work to build searchable structures alongside the normal trace by id search. As we consolidate these code paths, we expect search performance to continue to improve.
Breaking changes
There is a long-ish list of minor breaking changes in Tempo 1.2. For the average operator/user these will have almost no impact, but they still should be mentioned!
- Support for v0 and v1 blocks were dropped as announced with Tempo v1.1. Refer to the v1.1 changelog for details.
- Small adjustments were made to the Querier API. When rolling a deployment, there will be a read outage until all queries and query frontends have rolled to the latest version.
- API improvements consolidated informational endpoints within the status endpoint.
- Metric
ingester_bytes_metric_totalis renamedingester_bytes_received_totalby PR 979. - Metric
cortex_runtime_config_last_reload_successfulis renamedtempo_runtime_config_last_reload_successfulby PR 945. - The
tempo-cliflag--storage.trace.maintenance-cycleis renamed--storage.trace.blocklist_pollby PR 897.
What’s next?
Full backend search is next! Now that the groundwork has been established with recent traces search in v1.2, we are actively working on providing full backend search and will hopefully release it soon. We are also looking at adding support for aggregating and writing trace metrics from Tempo to a metrics backend. Stay tuned for more!
If you are interested in more Tempo news or search progress, please join us on the public Grafana Slack channel #tempo, post a question in the forums, reach out on Twitter, or join our monthly community call. See you there!
The easiest way to get started with Tempo is with Grafana Cloud, and our free tier now includes 50GB of traces along with 50GB of logs and 10K series of metrics. You can sign up for free here.


