

"Open source done right": Why Canonical adopted Grafana, Loki, and Grafana Agent for their new stack
Michele Mancioppi is a product manager at Canonical with responsibility for observability and Java. He is the architect of the new system of Charmed Operators for observability known as LMA2.
Jon Seager is an engineering director at Canonical with responsibility for Juju, the Charmed Operator Framework, and a number of Charmed Operator development teams which operate across different software flavors including observability, data platform, MLOps, identity, and more.
Juju re-imagines the world of operating software securely, reliably, and at scale. Juju realizes the promise of model-driven operations. Excellent observability is undeniably a key ingredient for operating software well, which is why the Charmed Operator ecosystem has long provided operators the ability to run a variety of open source monitoring software. We collectively refer to these operators as the Logs, Metrics, and Alerts (LMA) stack.
With the advent of cloud native software and microservices, and the resulting increase in complexity of systems, we decided it was time to create the next generation of LMA running on Kubernetes. It needed to be capable of monitoring workloads running on Kubernetes, virtual machines, bare metal, or the edge.
Going back to the drawing board, we also reassessed which components would be part of this new cloud native LMA. The resulting design is composed of open source projects led or very heavily contributed to by Grafana Labs. Let us tell you why.
There’s something about Juju …
Juju takes a fundamentally different approach to building and operating infrastructure. Rather than a focus on the low-level components, such as virtual machines, subnets, or containers, Juju focuses the user on operating applications while it takes care of the rest.
At the heart of any Juju deployment lies a controller, which is aware of a set of underlying clouds and the state of the models and applications it’s managing. Models in Juju are essentially workspaces for groups of related applications, and applications are known as Charmed Operators.
A Charmed Operator comprises code that understands how to install, configure, integrate, and generally operate a piece of software. It uses an agent to communicate with the Juju controller, which is provisioned automatically when you deploy an application. Juju’s advantage is that Charmed Operators function the same whether your underlying cloud is AWS, Azure, OpenStack, VMware, Kubernetes, and more. You’re always just one juju deploy foo away from competently operating software with Juju, where the user experience and tooling is consistent across clouds and enables seamless integration between them.
There is an ever-growing collection of Charmed Operators available on Charmhub. Go have a look!
A new LMA for the new cloud native world
The new LMA stack, which we call “LMA2," has the following design goals:
- Quality and reliability: Uptime and reliability is a must for any software, but much more so for your monitoring software. If your monitoring software is not up and running to tell you what else is not working, what good is it, really?
- Scalability: Monitoring has a strong network effect. So, with adequate resources, LMA2 should be able to scale to monitor a lot of software for your ops teams to have the deepest possible insight about your infrastructure and applications.
- Resource efficiency: LMA2 should be able to run at the edge as well as data centers, requiring as little compute resources as possible to fulfill its mission.
- Composability: LMA2 should consist of a set of high-quality Charmed Operators that are designed to work well on their own and better together.
- Cohesive user experience: LMA2 should ensure a consistent, cohesive experience for end users, with tools that feel designed to work together — one UI to visualize all types of telemetry. LMA2 should also create consistent metadata on telemetry so that the context of the telemetry (“where is it coming from?”) can be used to bridge across telemetry type silos — from metrics to logs, from logs to alerts — all while leveraging the same metadata everywhere.
- Consistent operator experience: Various pieces of software following a similar philosophy feel similar in terms of operations, failure modes, dependencies, and pitfalls. This consistency helps immensely with reducing cognitive load on the operators.
- Monitoring coverage: While starting with logs, metrics, and alerts (that’s literally what the “LMA” moniker is made of, after all), there are other types of telemetry that are invaluable in cloud native environments, such as distributed tracing and synthetic monitoring. LMA2 should be designed with extensibility in mind, so it can grow the capability to process additional types of telemetry. On the flip-side, a lot of software is not cloud native, or even running on a cloud. LMA2 should be capable of monitoring software well outside the boundaries of Kubernetes. For example, just focusing on Canonical products, LMA should be able to monitor Ceph, Charmed OpenStack, running bare-metal with MAAS or in containers or virtual machines on LXD.
- Ease of operations: We want LMA2 to be a monitoring stack that feels like an appliance, with as few knobs to turn as possible, and great functionality out of the box. We want to entirely remove the toil from setting up the monitoring of your Juju workloads; it should be as simple as establishing a couple of Juju relations.
- Showcase the declarative power of the Juju model: If some functionality or integration can be adequately modelled as a relation between Charmed Operators, it should be. Also, relations must be semantically meaningful: By looking at a Juju model, you should intuitively understand what results from two charms being related.
The design goals above are ambitious, and we are delighted with how the result of our efforts are shaping up! Our success is thanks in no small part to the amazing quality of the Prometheus, Grafana, and Grafana Loki projects, and how well their philosophy aligns with the design goals for LMA2, so let’s dive deeper into that.
Grafana, Prometheus, Alertmanager, Loki to the rescue
At Canonical, open source is a part of our DNA. Juju and the entire Charmed Operator ecosystem is open source. We see eye-to-eye on this with the Grafana folks, who are excellent open source citizens, very responsive to the community, and overall a pleasure to work with.
Many good reasons to build on the Grafana ecosystem
But, of course, not only must the people be nice, the software must be nice, too! The open source projects led and contributed to by Grafana Labs don’t disappoint! Put very succinctly, the reasons why we decided to build LMA2 by composing Grafana projects are the following (not necessarily in order of importance!):
- Open source software done right.
- Easy-to-integrate components.
- Resource efficiency.
- Shared backing components.
- The straightforward nature of how object storage is used.
- Consistent philosophy and UX (down to “Loki is Prometheus for logs”).
- Good performance and scalability.
- Coverage of telemetry types (metrics, logs, distributed tracing, synthetic monitoring, etc.)
- Good agent story with Grafana Agent: it packs a punch!
To expand on the above, Prometheus, Alertmanager, and Grafana have been staples of the previous iteration of LMA2 and relying on them again was simply a no-brainer: familiarity for end users, quality, ease of use, consistency in design philosophy, resource efficiency — it’s all there!
Loki: a refreshing take on log analytics
Loki, the “Prometheus for logs,” has displaced Graylog as the log analytics component of choice in LMA2. We ran a detailed evaluation involving, among other aspects, ease of operations, ease of integration with the other LMA2 components, sparsity of dependencies, and scalability. We got really excited seeing that Loki 2.0 did away with a dedicated index store, further reducing the footprint for LMA2. Moreover, Loki uses object storage rather than complex databases, which is amazing for reliability and ease of operations. In terms of consistent user experience, Loki is very well integrated in Grafana, and LogQL feels very familiar to Prometheus users.
Grafana Agent: a telemetry collection powerhouse
Grafana Agent also deserves a loving mention. Monitoring benefits greatly from the network effect: the more you monitor together, the easier it is to find correlations and root causes. The ease of enabling telemetry collection helps to achieve this network effect: a single agent, capable of collecting and forwarding metrics, logs, and distributed traces goes a long way to reduce the cost and complexity of rolling our monitoring to many systems. We like the Grafana Agent so much that we will build the self-monitoring capabilities of LMA2 with it! We foresee two modes for self-monitoring: one in which the data goes to a remote LMA2 stack (think of it like Prometheus federation, but for the whole stack), and one in which the stack monitors itself, to be used for self-contained deployments.
A picture is worth a thousand words
The declarative nature of Juju lends itself really well to graphical representations.
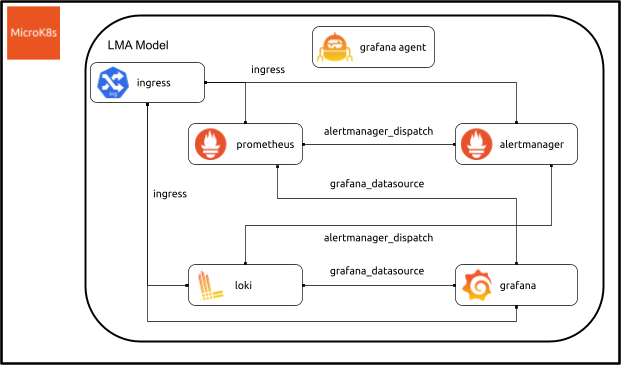
Above is a graphical representation of a Juju model hosting an LMA2 stack. For readability, the monitoring relations between Grafana Agent and the various components are not depicted.
Here above you see a diagram representing the deployment of an LMA2 in a Juju model and how the various Charmed Operators interact with one another. (Note that not everything in the diagram is implemented just yet.)
As mentioned before, the self-monitoring of the stack by the Grafana Agent is something we look forward to implementing soon. Similarly, we are working on charming (what the Juju community calls the process of creating a Charmed Operator) an Ingress controller so that we can expose outside various endpoints that are needed to monitor or receive data from outside the MicroK8s cluster since, for resilience reasons, we want LMA2 to be hosted in a dedicated MicroK8s cluster and share as little infrastructure as possible with the workloads it monitors. The endpoints that will need to be exposed outside of the MicroK8s cluster are:
- Loki push_api endpoint
- Web UIs of Prometheus, Alertmanager, and Grafana
- Prometheus’s remote_write (Note: We currently do not plan to implement support for Prometheus federation or remote_read, but if the use-case arises…)
And this is just the beginning
With regard to telemetry types, the work on the new cloud native LMA2 is currently focusing on metrics, logs, and alerts. But there is more than that to observability, especially in cloud native environments. On the “What is observability?” page we go through a number of other telemetry types, like distributed tracing, or end user and synthetic monitoring. The Grafana ecosystem has projects, such as Grafana Tempo and k6 that fit those bills, which makes us confident that as LMA2 grows and becomes more capable, it will be able to leverage projects with this consistent philosophy and quality as it does today with Prometheus, Grafana, and Loki.
Another direction we want to pursue with LMA2 is high scalability and availability. We are looking with great interest at Cortex as the way of bringing multi-tenancy and resilience to the Prometheus experience, and Loki already has a lot of the capabilities we need in that dimension.
Join us in making model-driven observability a first-class experience on the Charmhub Mattermost, have a look at the LMA2 documentation, or jump right into it and take LMA Light for a spin!


