

The future of Prometheus remote write
At PromCon last month, Tom Wilkie, Grafana Labs VP of Product, described the origin and purpose of Prometheus remote write and previewed exciting developments on the road map. “We covered our efforts to standardize remote write, document how it works and why it works that way, and then test implementations,” Wilkie said. “In the next release or two of Prometheus, we’ll improve how we send metadata via remote write and start sending exemplars.” Other future enhancements detailed in his talk include making remote write atomic, improving the handling of 429s, and reducing bandwidth usage. Scroll on for an edited version of Wilkie’s presentation, or you can watch the full video here:
What is remote write, and how did it start?
The story of remote write matches Wilkie’s own story with Prometheus. The first PR he did for Prometheus, five years ago, involved switching the remote write system from gRPC over to Protobuf and HTTP. At the time it was challenging to get gRPC to go through an Elastic Load Balancer, and Wilkie wanted to use Prometheus remote write to send data to Cortex, the open source project for scaling Prometheus that Wilkie co-founded. That, in a nutshell, is what Prometheus remote write is for — sending data to other systems.

Since then lots of vendors have taken notice of Prometheus and added support for remote write to their products. “You can send data from Prometheus to pretty much any of the metrics vendors in the world,” said Wilkie. “Now we want to push the interoperability story of Prometheus as far as it will go.” Recently, Wilkie’s team at Grafana Labs enabled Prometheus to receive remote write requests as well as send them. This, as he points out, solves the Prometheus federation problem in a new way.
Global federation, revisited
Federation allows a Prometheus to scrape metrics from other Prometheus servers. The challenge is that, for the global Prometheus to be able to scrape the edge ones, you have to open up firewall ports and secure multiple servers. But with the push-based approach of Prometheus remote write, it’s possible to open up just the central location and have the edge locations push to it. “This may not sound like a big deal, but imagine if these edge locations were on IP addresses that were changing, or on unstable networks?” said Wilkie. “The remote write protocol could be a better fit.”

Standardization and interoperability
There are now numerous projects scraping Prometheus metrics and sending them elsewhere using remote write. These include Prometheus itself, the Grafana Agent (which is a stripped-down version of Prometheus using the same code), vmagent, Influx’s Telegraf, and the OpenTelemetry Collector. Adoption by multiple vendors has led to some differences in implementation. “We want to make sure that this ecosystem is interoperable,” Wilkie said, ”so that all the users of all the different components can have the best possible experience.”
The first step was to create a document that defined what Prometheus remote write is, and what it meant to be compatible. “We also wanted to explain the reasoning behind why we’ve done it this way,” said Wilkie. “And give some thought to how to future-proof this protocol so that when we introduce the v2, we can be backwards compatible.”
Testing against the standard
After establishing a standard, the team was able to test various implementations against it by building a test harness that runs an instance of each of the agents, exports some metrics to be scraped, and configures them to send that data back via remote write. The tool then checks the response to see if it matches what was expected. “This is relatively straightforward,” said Wilkie. “We export a counter, we check that we get a counter back. We export a histogram, we check we get a histogram back. But there’s a lot of nuance to this protocol. There are a lot of different areas which some people do or don’t implement, and so we wanted to figure out what level of coverage we had.”
The Prometheus team published updated test results during KubeCon + CloudNativeCon:
| Sender | Version | Score |
|---|---|---|
| Grafana Agent | 0.13.1 | 100% |
| Prometheus | 2.26.0 | 100% |
| OpenTelemetry Collector | 0.26.0 | 41% |
| Telegraf | 1.18.2 | 65% |
| Timber Vector | 0.13.1 | 35% |
| VictoriaMetrics Agent | 1.59.0 | 76% |
Introducing metadata
Prometheus client libraries currently allow you to add help text and type metadata to every metric in your application. Prometheus scrapes this and stores the latest values in memory, and has an API so the client application to Prometheus (Grafana or the Prometheus UI) can query it and use it. Wilkie would like to enable systems that implement remote write to have the same information and the same user experience as Prometheus. “Over a year ago, we added support for metadata to the remote write protocol,” said Wilkie. “It’s an extra field, and it’s a bit ‘best effort,’ where we were taking some of the metadata and sending it on a period, alongside your samples. We want to make a series of improvements to this. We want to write the metadata to the write ahead log, we want to send it alongside the same metrics that it’s supposed to be sent with, instead of arbitrarily sharding it.”
Introducing exemplars
In Grafana, exemplars allow you to overlay dots on a graph. Click on one of those dots and you can jump straight to the trace that that dot represents. “Beorn Rabenstein added exemplar support to client Golang quite a while ago, and Callum Styan added exemplar support to Prometheus in the last release,” said Wilkie. “Together you can implement this really cool experience that speeds up instant response and debugging workflows and makes the whole system feel a lot more integrated.” Now, the Grafana Labs team has added remote write for exemplars in the next release. “We want to make this available to remote write endpoints,” said Wilkie. “People who are implementing remote write should also be able to receive exemplars and offer the same APIs and the same experience.”
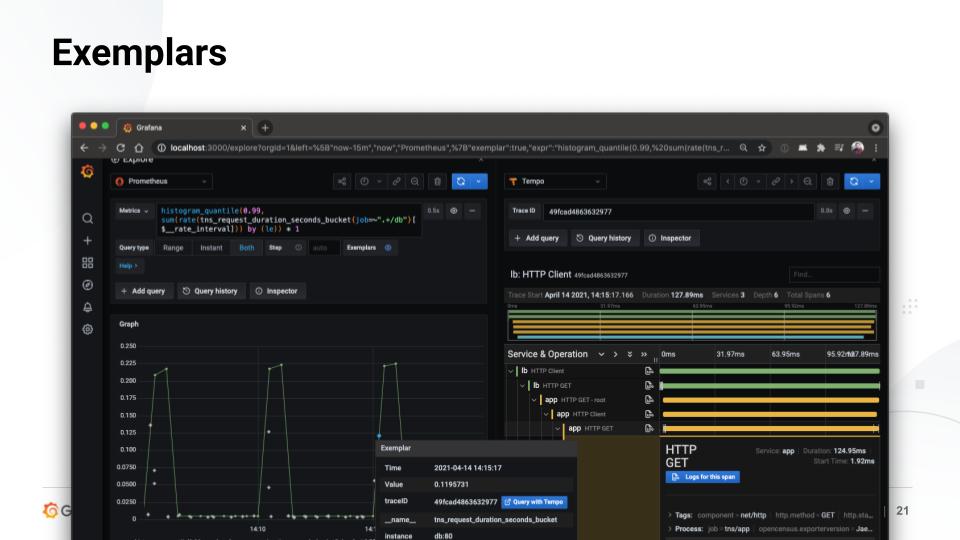
Next up: atomicity
Prometheus metrics are often composite and actually made up of multiple time series. (Take, for example, a histogram that is made up of time series per bucket, alongside a count, and a sum time series.) Thus, it’s important that when running a query you get a complete scrape, as opposed to partial updates from more than one scrape. Remote write unfortunately doesn’t do this yet because of the way the remote write client inside Prometheus splits up batches of requests in order to send them in parallel. This means that remote write systems might actually get metrics, or samples, for different series within a histogram in a different order. “We want to fix this,” said Wilkie. “We haven’t yet decided how.”
One solution under consideration is to have the entire batch of samples gathered in a single scrape and written to the write ahead log in a single batch. Then, the remote write system will read that entire batch in a single scrape of the write ahead log and send it out to the remote system. Aligning this throughout the pipeline will give the systems at the other end the opportunity to offer atomicity.
A better way to handle 429s
If Prometheus sends samples too quickly, remote systems will send back a 429. For context, a status code in the 500s indicates a problem with the system. If Prometheus receives a 500 code it will back off and retry. But Prometheus doesn’t retry 400s. This is by design because 400s indicate there’s something wrong with the request, and that request will not succeed if you try it again. For example, it might be that you’ve hit a limit on the total number of series. There’s no point in trying again because you’ve hit a limit.
Problems arise when there is an outage. If the system goes down, samples will buffer up on disk, and Prometheus will wait for the system to come back up. When it does, Prometheus will attempt to replay the write ahead log to the remote system to fill in any gaps. Prometheus will replay as quickly as it can — and it can replay pretty quickly — so the upstream system may send a 429 which says, in effect, “You’re too fast.” And at that point, Prometheus will drop the data. “So after doing all this really hard work to buffer up the data on disk and make sure it’s there during the period of the outage, when the system comes back, we drop the data,” said Wilkie. “It’s a real shame, but we think we can improve this by backing off on 429s and knowing when to balance catching up against falling behind.”
Reducing bandwidth usage
The remote write system was designed to be simple and stateless. There are no interdependencies between messages in the protocol, which drastically simplifies downstream implementations. “This makes things like Cortex easy to write, it makes the adapters between Prometheus and Grafana simple to write,” said Wilkie. “However, it’s expensive.” Stateless batches mean that labels get repeated multiple times, with the same labels being sent in most batches. This eats bandwidth.
“We use between 10 and 2 bytes per sample to send via remote write, and Prometheus only uses 1 or 2 bytes per sample on the local disk so there’s big, big room for improvement,” said Wilkie. “A lot of the work we’re going to do on atomicity and batching will allow us to have a symbol table in the remote write requests that will reduce bandwidth usage.”
Interested in learning more about the latest developments in Prometheus and Cortex? Don’t miss the June 9 GrafanaCONline session, “The pace of Prometheus and Cortex innovation.” Register here for free access to all the sessions!


