

Scaling Prometheus: How we’re pushing Cortex blocks storage to its limit and beyond
In a recent blog post, I wrote about the work we’ve done over the past year on Cortex blocks storage. Cortex is a long-term distributed storage for Prometheus. It provides horizontal scalability, high availability, multi-tenancy and blazing fast query performances when querying high cardinality series or large time ranges.
At Grafana Labs, we’re currently running the blocks storage at a relatively large scale, with some tenants remote writing between 10 and 30 millions active series (~1M samples/sec), and up to 200GB of blocks stored in the long-term storage per tenant, per day.
Over the next few months, we expect to onboard new tenants that will be in the order of 10x bigger than our current largest one, but we’ve already faced several headaches while scaling out the blocks storage. So in this post, I want to take a deeper dive into the challenges we’ve faced and how we’ve dealt with them.
It’s blazing fast . . .until you try to query it back
The write path proved to be very solid. We can horizontally scale distributors and ingesters, and ingest millions of samples/sec with a 99th percentile latency usually under 5ms in the ingester.
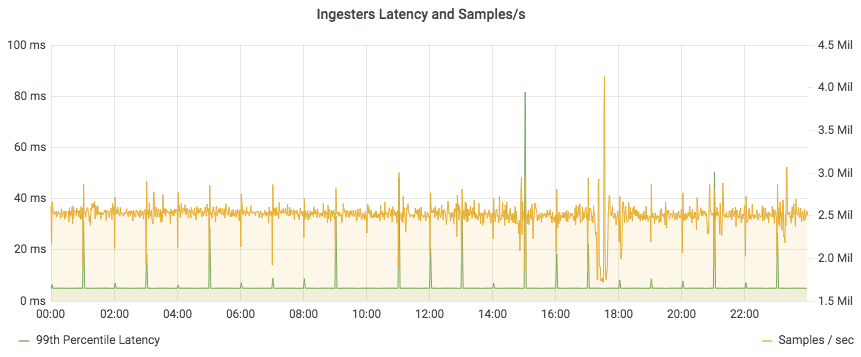
But if you have a tenant generating 200GB of blocks per day and you offer 13 months retention, you have to be ready to query back 80TB of sparse time series at any time.
That’s where issues arise.
Damn, those non-compacted blocks!
The first thing we learned is that querying non-compacted blocks is pretty inefficient.
Let’s say you run a Cortex cluster with 100 ingesters. Each ingester ships one block every two hours to the storage, so every two hours, you have 100 new blocks. Each single block is relatively small, but you have to query all of them to execute a single query.
Theoretically, in a distributed system like Cortex, having small shards of data that you can concurrently query (like those non-compacted blocks) should be preferable, because you can better distribute the workload.
But there are a couple of factors to consider:
- The 3x replication factor in the write path leads to 3x replicated data in TSDB blocks (both block’s chunks and index), and this leads it to fetch 3x data from the object store.
- The TSDB blocks’ index symbols and postings are frequently repeated across the indexes of blocks generated by different ingesters for the same 2h time range. This leads to inefficient index querying because the same postings are looked up over and over across different block indexes.
Now, the compactor is the service responsible for merging and deduplicating source blocks into a larger block. It supports both vertical compaction (to compact overlapping 2h blocks) and horizontal compaction (to compact adjacent blocks into a wider one).
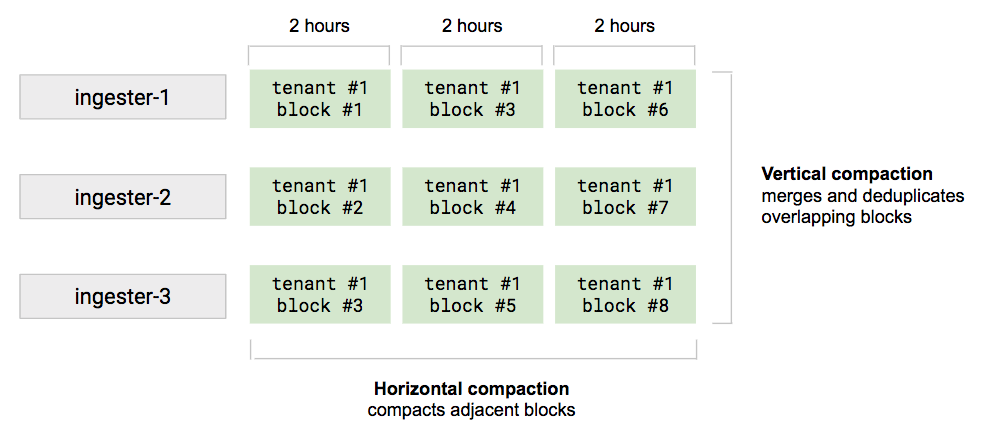
However, compacting blocks for a large tenant may take a few hours, so when you run a “Last 24h” query, it’s very likely that you will end up querying between 200 and 300 non-compacted blocks in a cluster with 100 ingesters.
The solution we adopted in Cortex is to query the last 12h only from ingesters (it’s configurable). The idea is to have a cut-off time of 12h between ingesters and long-term storage in order to give the compactor enough time to run the vertical compaction of 2h blocks. Samples with a timestamp more recent than 12h are only queried from ingesters, while older samples are only queried from the long-term storage.
This simple solution proved to work quite well for large tenants. Following the previous example, if you run a “Last 24h” query, the most recent 12h are fetched only from ingesters, while the remaining 12h are fetched from 6 compacted blocks in the storage.
To be honest, figuring this out was a typical case of spending one week brainstorming about an issue, then solving it by just changing a few lines of code. Unfortunately, we’re not born knowing everything.
Aligning with the query-frontend splitting
Since we can assume any block we query from the storage has already been vertically compacted, the next question is: How should we configure blocks range periods for the horizontal compaction?
In other words, given that the compactor can horizontally compact adjacent blocks, what’s the ideal range period to compact to? Up to one day? Or one week? Or two weeks?
To answer this question, we have to get back to the query-frontend.
We know the query-frontend splits a large time range query into multiple one-day queries. This means a single query hitting the querier never covers a time range greater than 24h, and it’s always aligned to the solar day (no query overlaps two days).
If we configure the compactor to compact blocks to a one-week range period, every query – which is guaranteed to be covering only a day – will waste resources looking up series from a seven-day range block. We know that by design we’ll never query more than one day.
For this reason, the default (and suggested) highest block range period configured in the Cortex compactor is one day, in order to align it with the query-frontend splitting.
The one-day blocks range period works perfectly in theory, but not in practice
The one-day block range period works perfectly in theory, but not so much in practice, because the assumption we made before is not 100 percent correct.
Prometheus – specifically the PromQL engine – has a configurable lookback delta, which defaults to five minutes. (You can learn more here, but the bottom line is that changing it is rarely a good idea.) What this means that when the querier receives a query for the time range 2020-07-16 00:00:00 - 2020-07-16 23:59:59, PromQL engine actually asks for samples in the range 2020-07-15 23:55:00 - 2020-07-16 23:59:59 because it applies the lookback delta of five minutes. So every query over the entire day will actually query not one but two 24h blocks.
We haven’t found any good solutions to that yet, and we still have an open issue for it. It’s not a critical problem, but it’s something we hadn’t considered initially, we learned about it the hard way and we want to fix at some point.
Breaking the vertical scalability limits
The store-gateway is responsible for querying chunks of samples out of blocks stored in the bucket. The workflow is pretty simple:
- The store-gateway receives a request to query series by label matchers within a given time range, plus a list of block IDs.
- For each block in the list, it concurrently queries the index to find the series by label matchers, and from the series it gets the list of chunk references. Finally, it loads the matching chunks from the storage via GET byte range requests.
Unfortunately, the TSDB index is not external memory friendly. You can’t efficiently query the index exclusively via GET byte range requests through the storage. In fact, there are two sections of the index – the symbols table and the postings offset table – that you need to have previously downloaded locally to efficiently look up the index.
What happens is, the store-gateway periodically scans the bucket and for each block found, it downloads a subset of the index, which we call the index-header. The index-header just contains the index’s symbols table (used to intern strings), and postings offset table (used to look up postings).
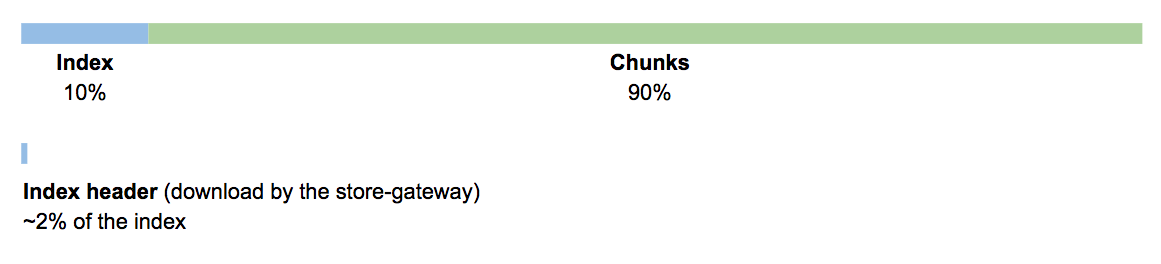
The size of the index-header is not dramatic. In our experience running the blocks storage at scale, the index-header of a 24h compacted block is in the order of 2 percent of the index, or about 0.2 percent of the total block size.
Getting back to the previous case of a tenant producing 200GB of blocks / day, the index-header would be in the order of 400MB / day. It doesn’t look like much, but if you project it to a 13 months retention, we’re talking about 160GB of data that needs to be downloaded locally in the store-gateway before it’s ready to query blocks. And this is for a single tenant.
The index-header clearly imposes a vertical scalability limit. The solution we adopted in Cortex is – guess what? – blocks sharding!
Similar to ingesters in the write path, the store-gateways join a hash ring, which is a generic distributed data structure we use for sharding and replication. Each block ID is hashed and assigned to a store-gateway instance and replicated on other RF-1 instances, where RF is the replication factor (defaults to 3).
A store-gateway is responsible only for the blocks belonging to its shard, so while periodically scanning the bucket, it filters out any block ID whose hash doesn’t match the hash ranges assigned to the store-gateway itself.
The hash ring topology is dynamic. Instances can be added and removed at any time (it happens whenever you scale up or down the store-gateways) and – whenever the topology changes – blocks are automatically resharded across store-gateways. The consistent hashing ring guarantees that no more than total number of blocks / total number of store-gateways blocks get resharded whenever an instance is added or removed.
As previously I mentioned, blocks are also replicated across store-gateways, typically by a factor of three (it’s configurable). This is not only used to protect missing blocks on a store-gateway instance while there’s ongoing resharding (remember, the querier can retry fetching missing blocks from other replicas), but it’s also used to distribute the workload when querying blocks.
For example, when running the store-gateways with a replication factor of three, the querier will balance the requests to query a block across the three store-gateways holding it, effectively distributing the workload for a specific block by a factor of three.
But the worst is yet to come . . .
It’s pretty clear now that the compaction plays an essential role in the query performance. But how performant and scalable is the compactor?
The TSDB leveled compactor is single-thread. Whatever best hardware you use, it won’t scale up more than a single core. Yes, it’s CPU capped.
We spent some time investigating options to optimize it (including a proposal to cache symbols lookup), but we haven’t found any easy wins.
Recently, the Prometheus community has legitimately spent significant effort to reduce the TSDB memory footprint, and some of the changes came with a tradeoff between memory and CPU. I personally believe that these changes make a lot of sense in the context of Prometheus, where the compactor runs within Prometheus itself, but it may look counterproductive in systems like Cortex, where the compactor runs isolated from the rest of the system. Not a rant, just an opinion.
Of course, behind every problem there’s an opportunity. And when it comes to opportunities, our solution is . . . sharding!
The Cortex compactor supports per-tenant sharding. The idea is that – to some extent – we don’t care much how long it takes to compact a single group of blocks, as long as we can horizontally scale it.
At this point, it seems quite superfluous to mention that we use the hash ring for the compactor sharding as well, right? But as long as I’m mentioning it, yes we do!
What’s next?
There’s still a lot more to discuss. I’d like to talk about how we implemented sub-object caching for the chunks, or all the nuances of the query consistency check, but it’s getting late and I’ve probably covered more than I should in a single blog post.
Let me just share two highlights from the next steps you can expect:
- Further query optimizations. In particular, we’re discussing introducing a second dimension – other than time – to shard single-tenant blocks like we’re doing in the chunks storage, and having the query-frontend leveraging it to parallelize queries.
- Shuffle sharding to scale out a large cluster made of many small tenants. We already support shuffle sharding on the write path, but on the read path, queries are still querying samples from all ingesters.
We’ll cover more details in subsequent blog posts over the next few weeks, but before leaving, let me mention that all this work is not a one-man show. It’s the result of a collaborative effort of a group of people involving Peter Stibrany (Cortex maintainer); Ganesh Vernekar (Prometheus maintainer); the Thanos community, captained by Bartek Plotka (Thanos co-author); the Cortex community; and me.
It’s really wonderful working on a daily basis with such great people, and I feel very grateful for the opportunity to be on their side. If all of this sounds interesting to you, consider joining us at Grafana Labs – we’re hiring!
Finally, let me remind you that if you’re looking for a managed solution to scale out your Prometheus, Cortex is the underlying technology powering Grafana Cloud Hosted Metrics for Prometheus service. Check it out!
Thanks for reading to the very end, and see you soon!


