

How We Designed Loki to Work Easily Both as Microservices and as Monoliths
In recent years, monoliths have lost favor as microservices increased in popularity. Conventional wisdom says that microservices, and distributed systems in general, are hard to operate: There are often too many dependencies and tunables, multiple moving parts, and operational complexity.
So when Grafana Labs built Loki – a service that optimizes search, aggregation, and exploration of logs natively in Grafana – the team was determined to incorporate the best of both worlds, making it much simpler to use, whether you want to run a single process on bare metal or microservices at hyperscale.
“Loki is single binary, has no dependencies, and can be run on your laptop without being connected to the Internet,” says Grafana Labs VP Product Tom Wilkie. “So it’s easy to develop on, deploy, and try.”
And if you want to run it with microservices at scale, adds Loki Engineer Edward Welch, “Loki lets you go from 1 node to 100 and 1 service to 10, to scale in a pretty straightforward fashion.”

Here’s a breakdown of how the Grafana Labs team developed the architecture of Loki to allow users “to have your cake and eat it too,” says Wilkie.
1. Easy to Deploy
With Loki, easy deployment became a priority feature after the team looked at the other offerings.
On the microservices side, “Kubernetes is well-known to be hard to deploy,” says Wilkie. “It is made of multiple components, they all need to be configured separately, they all do different jobs, they all need to be deployed in different ways. Hadoop would be exactly the same. There’s a big, whole ecosystem developed around just deploying Hadoop.”
The same criticisms even hold true for Wilkie’s other project, Cortex, with its multiple services and dependencies on Consul, Bigtable/DynamoDB/Cassandra, Memcached, and S3/GCS – although this is something Wilkie is actively working to improve.
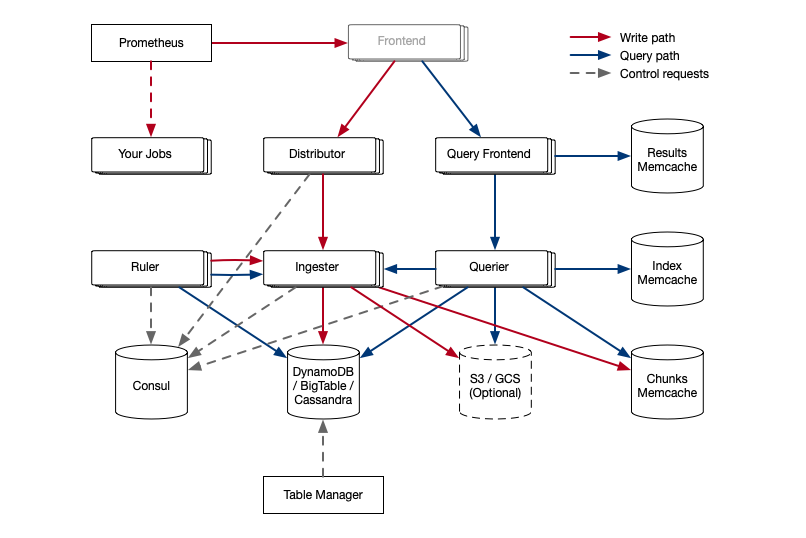
The single-process, scale-out models such as Cassandra and Nomad have been gaining more traction recently because users can get started much more easily. “It just runs a binary on each node, and you’re done,” says Software Engineer Goutham Veeramachaneni.
So in this way, the team built Loki as a monolith: “One thing to deploy, one thing to manage, one thing to configure,” says Wilkie.
“That low barrier to entry is a huge advantage because it gets people using the project,” says Welch. “When you’re trying out an open source project and not sure if it’s the right thing for you, you don’t want to put all this time, effort, and investment into configuring and deploying the service while learning the best practices up front. You just want something that you could get started with immediately and quickly.”
2. Simple Architecture
With microservice architectures such as Kubernetes, “you don’t get any value running a scheduler or an API server on its own. Kubernetes only has a benefit when you run all the components in combination,” says Wilkie.
On the other end of the spectrum, single binary systems like Cassandra have no dependencies, and every process is the same within the system.
A lot of the inspiration for Loki was actually derived from Thanos, the open source project for running Prometheus at scale. While Thanos operates with a microservices approach, in which users have to deploy all services to run the system, it aligns each service around a given value proposition. If you want to globally aggregate your queries, you deploy Thanos queriers. If you want to do long-term storage, you deploy the store and sidecars. If you want to start doing down sampling, you deploy the Compactor.
“Every service you add incrementally adds benefit, and Thanos doesn’t introduce too many dependencies, so you can still run it locally,” says Wilkie. “And it doesn’t do all the jobs in the one Cassandra-style homogeneous single process.”
With Loki, Welch explains, “every instance can run the same services and has the same code. We don’t deploy different components – it’s a single binary. We deploy more of the same component and then specify what each component does at runtime. You can ask each process to do a single job, or all the jobs in one.”
So in the end, Loki users have flexibility in both dimensions. “You can deploy more of the same component – that’s closer to a Cassandra-style architecture where every process in the system is the same – or run it as a set of microservices.” explains Wilkie. “You can split those out and have every single function done in a separate process and a separate service. You’ve got that flexibility which you don’t get with Cassandra.”
3. Easy to Scale
The final consideration is how does the service grow as the user’s system grows?
Microservices have become the most popular option because by breaking up different functions into different services, there is the ability to isolate each service, use custom load balancing and a more specialized way of scaling and configuring.
“That’s why people went down this microservices architecture – it makes it very easy to isolate concerns from the development process,” says Wilkie. “You might have a separate team working on one service and a different team working on another. So if one service crashes, runs out of memory, pegs the CPU, or experiences trouble, it’s isolated and won’t necessarily affect the other services.”
The challenge of this approach, however, is when multiple problems arise at once. “Deploying lots of microservices makes config management hard,” says Wilkie. “If you’ve got 10 different components, diagnosing outages become trickier – you might not know which component is causing the problem.”
Which is why some engineers prefer a simpler approach. “I really like single binary because the biggest problem with deploying a distributed system is not deploying the distributed system, but gaining that expertise as to what to fix, what to look at,” says Veeramachaneni. “Having it run locally, having it on a single node, and experiencing the issues help users gain familiarity with the system. It also gives you that confidence that you can deploy it into production.”
The compromise: Loki has a single-process, no dependencies scale-out “mode” for ease of deployment and getting started, while allowing users to scale into a microservices architecture when ready.
“I would run a single-node Loki first, look at what breaks, and then scale out what doesn’t work,” says Veeramachaneni. And then, “slowly add that expertise.”
The Best of Both Worlds
“The nice thing about Loki is you can independently scale the right parts by splitting out the microservices,” Wilkie says. “When you want to run Loki at massive scale with microservices, you can. You can just run them all as different services, and you can introduce dependencies on Big Table, DynamoDB, S3, Memcached, or Consul when you want to.”
By design, Loki “gives you the ability to start and learn the system easily,” he adds, “but grows to the same kind of enterprise-ready architecture that microservices offer.”
For more about Grafana’s user interface for Loki, check out this blog post.


